摘要:企业一窝蜂推进“全员 AI Coding”,最常见的结局不是效率革命,而是 Token 账单暴涨、流程更乱、老板更焦虑。问题不在 AI 没用,而在于很多公司把拖拉机当成了印钞机。
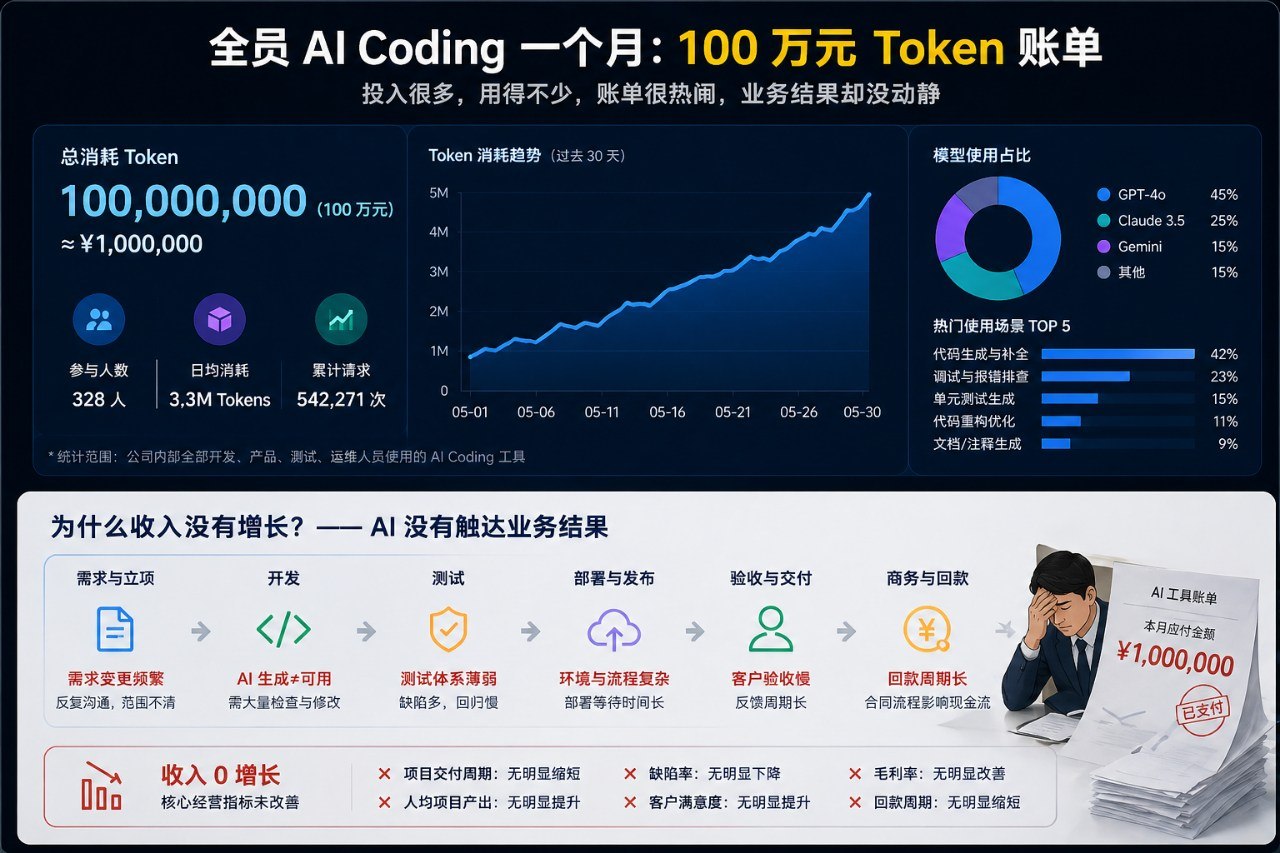

最近,IT 圈子里流传着一个令人啼笑皆非却又无比真实的段子,或许它本身就来自某家公司的真实经历。某大型软件企业为了响应“拥抱大模型”的时代号召,大刀阔斧地搞了一个月的“全员 AI Coding”运动。公司豪掷千金,直接给所有研发人员开放了高级模型的 API 权限,鼓励大家用 AI 写代码、查 Bug、写文档。
结果,短短一个月时间,全员狂飙突进,直接烧掉了价值 100 万的 Token 账单。
然而,到了第二个月的复盘会上,老板看着财务递上来的账单,又看了看业务部门毫无起色的营收数据,陷入了沉思。老板的逻辑很简单:“我花了 100 万给你们上了加速器,你们写代码的速度翻倍了,为什么公司的产品收入没有翻倍?为什么上线的项目没有成倍增加?”
由于迟迟看不到传说中的“降本增效”真正转化为真金白银的流水,这场轰轰烈烈的全员 AI 计划,在第二个月就被紧急叫停了。
这听起来像一个荒诞的黑色幽默,但它又精准地刺痛了当下无数企业在进行 AI 转型时的软肋。今天,我们就把这件事掰开揉碎,聊清楚一个关键问题:为什么“全员赋能 AI”这么容易演变成一场昂贵的闹剧?企业真正可持续的 AI 转型,到底该怎么走?
一、算力账本:这 100 万 Token 的“学费”到底是怎么烧掉的?
一个月烧掉 100 万,无论是人民币还是对应价值的额度,对于单纯的 API 调用来说都绝不是个小数目。问题不是“为什么这么贵”,而是企业往往根本不知道这笔钱是怎么被一点点放掉的。
根据许多企业的真实踩坑经验,这种“天价账单”通常来自几类非常典型的不良习惯和管理漏洞。
1. 毫无节制的“上下文喂养”
很多开发者在使用 AI 辅助编程时,并没有建立起最基本的 Prompt 意识。遇到一个微小的组件报错,他们不是提炼报错栈、相关函数和最小复现代码,而是简单粗暴地把整个项目文件、配置文件、日志片段甚至无关模块一起塞给模型。
大型模型是按输入输出长度收费的,这种“连带祖宗十八代一起问”的提问方式,本质上是在把 Token 当自来水放。表面上看只是复制粘贴几下,实际上每轮对话都在持续燃烧预算。
2. 自动化 Agent 的无限死循环
一些偏技术极客型的开发者,喜欢尝试 Auto-GPT 一类自动化智能体框架,给 AI 设定一个宏大的目标,比如“帮我重构这个支付模块”,然后让它自己去调用 API、读写文件、自我修正。
问题在于,当前模型的能力边界远没有到“可放心全托管”的程度。Agent 极其容易陷入“报错、重试、再报错、继续重试”的死循环。如果企业没有设置严格的调用上限、预算封顶和熔断机制,一个周末被遗忘在后台运行的脚本,就足以在两天内烧掉几万块钱。
3. 高射炮打蚊子,模型资源严重错配
很多企业为了追求“效果最好”,一上来就给全员开放最昂贵的顶级模型。但问题是,研发人员 80% 的日常诉求,可能只是“帮我写个正则表达式”“解释一下这段旧代码”“生成一段标准 JSON 测试数据”。
这类任务,往往根本不需要最强模型。成本只有十分之一甚至百分之一的轻量级模型,甚至本地化代码模型,已经足够胜任。如果企业没有模型分级策略,那本质上就是在用战斗机送外卖。
4. 缺乏缓存与工程化管控
一万个开发者在做相似业务时,很可能问出一万次非常接近的问题。如果企业没有统一的 AI 网关、缓存层和拦截机制,那么每一次重复请求都在为外部模型厂商重复付费。
说得更直白一点,缺乏工程化管理和使用规范的“全员 AI”,不是在降本增效,而是在给 AI 厂商做精准扶贫。
二、老板的执念,与软件工程的现实完全不是一回事
弄明白钱是怎么没的之后,我们再来回答老板最困惑的问题:“我花了钱,为什么营收没有增长?”
这恰恰是整场闹剧里最大的逻辑谬误,也是很多非技术管理者最容易陷入的思维陷阱。他们潜意识里把软件开发等同于传统制造业流水线,认为只要给程序员换上一台更快的机器,代码产量翻倍,营收自然就应该翻倍。
但软件工程从来就不是计件工资制的机械劳动,它是一种高度复杂的知识协作工程。
1. “打字速度”从来都不是软件开发的主要瓶颈
AI 编程工具本质上解决的,是代码生成速度问题。它可以帮你自动补全模板代码、快速生成样板函数、补出测试用例,甚至写出一个像样的小模块。
但在真实商业项目里,程序员每天真正用于“从零疯狂敲新代码”的时间,可能连 20% 都不到。剩下的大量时间,都消耗在需求对齐、历史代码理解、跨部门沟通、联调、测试、开会和修 Bug 上。
换句话说,AI 也许能让那 20% 的纯编码时间提速两倍,但如果另外 80% 的沟通与等待时间完全没有变化,那么整个产品交付周期并不会出现肉眼可见的质变。
2. 局部优化,可能反而导致系统性灾难
如果一家公司的真实瓶颈在需求评审、人工测试或者发布审批环节,而你只通过 AI 提高了研发人员写代码的速度,会发生什么?
答案很简单,功能会像洪水一样堆积到下游,测试和上线流程瞬间成为新的堵点。研发借助 AI 飞速产出,大量代码迅速涌向测试团队。测试人员测不过来,问题积压,上线延期,线上风险增加。局部看似优化,系统反而更失衡。
这就是典型的“木桶效应”与约束理论问题。你优化了不是瓶颈的环节,最终得到的不是效率革命,而是库存积压。
3. 营收增长,本质上是商业问题,不是代码问题
老板指望用 AI 编程来直接拉动营收,本身就是错位期待。一款软件产品能不能赚钱,核心取决于产品有没有抓住真实痛点,销售有没有把价值卖出去,市场有没有建立用户心智。
哪怕程序员用 AI 一秒钟写出一个功能完备的聊天产品,如果没有用户网络效应、没有渠道、没有产品定位,它照样一文不值。把商业层面的营收压力直接甩给开发工具的 ROI,本质上是一种极度短视的管理方式。
三、行业为什么会集体踩坑?因为很多公司把 AI 想得太万能了
这绝不是一家公司的孤例。放眼整个行业,很多急于求成的企业都在经历类似的 AI 阵痛期。按照 Gartner 的技术成熟度曲线,AI 辅助编程正从“期望膨胀期”逐渐走向“幻灭的低谷期”。
企业不是没买工具,也不是没人用,而是买回来之后才发现,现实与想象之间有一道极深的鸿沟。
案例 A,高级工程师被 AI 生成代码淹没
某互联网公司大规模推广 AI 编程后,初级工程师表面上产出暴增,每天能提交大量 Pull Request。但高级工程师很快就崩溃了,因为 AI 生成的代码常常表面优雅、结构完整、注释清晰,内部却埋着非常隐蔽的上下文错误、边界漏洞和维护陷阱。
结果是,原本应该节省的时间,最后被高级工程师用更多倍的时间花在审查、回滚、重构和补测试上。团队整体交付质量不升反降。
案例 B,昂贵企业版工具被当成高级自动补全
另一类公司买了大批企业版 AI 席位,年费动辄数百万。半年后做内部审计才发现,超过 70% 的员工只是拿它写几行 console.log、补变量名、查语法、生成几段样板 JSON。真正高价值的能力,比如项目级重构、测试生成、架构推演和知识沉淀,几乎没被激活。
最后企业续费时砍掉了大量席位,因为它终于发现,自己花的不是“效率革命”的钱,而是“高级自动补全器”的钱。
为了更直观,我们可以把管理层与一线研发的认知撕裂感总结成下面这张表。
| 维度 | 管理层的期望 | 一线开发的现实 |
|---|---|---|
| 效率提升 | 产能翻倍,甚至可以少招人 | 少写点模板代码,少切几次搜索页面 |
| 质量控制 | AI 不会犯错,Bug 应该更少 | AI 经常一本正经胡说八道,还会引入隐蔽问题 |
| ROI | 花了 Token 钱,当月就该体现在财报里 | 开发快了一点,但需求变更和测试瓶颈还在 |
| 学习成本 | 工具买来就能用 | 需要反复试 Prompt,还要花时间辨别结果真假 |
四、企业到底该怎么科学引入 AI 编程?
面对这 100 万打水漂的教训,最危险的结论不是“AI 没用”,而是“我们再也不要碰 AI 了”。这同样是误判。
AI 当然是趋势,但趋势从来不等于可以不加设计地一股脑铺开。企业真正想吃到红利,必须从“盲目跟风”切换到“工程化部署”。
1. 建立正确的度量体系,别再拿营收做单点考核
千万不要用“营收有没有增加”来考核 AI 编程工具的效果,这既不科学,也会把整个组织导向错误方向。
更合理的做法,是采用成熟的工程效能指标,例如 DORA:部署频率是否提升,变更前置时间是否缩短,线上故障恢复是否加快,变更失败率是否变高。同时也可以结合 SPACE 框架,观察开发者满意度、协作效率与组织健康度。
如果 AI 帮研发团队少做了很多机械重复劳动、减少了熬夜修样板代码的时间,这本身就是一种非常实在的组织收益。
2. 实施精细化算力管控与工具分级
不要再搞“全员高级 API 裸奔”了。
企业应该对模型做分级,对任务做分层。轻量任务用便宜模型甚至本地模型,复杂任务再调用昂贵闭源模型。中间必须有企业级网关,对 Prompt 做脱敏、缓存、审计和预算限制。每个部门、每个人,都应当有明确的调用额度、预警机制和使用规范。
只有这样,企业才是在用 AI,而不是被 AI 账单牵着鼻子走。
3. 重塑研发工作流,而不是只给开发者发一个新工具
如果流程不改,工具再强也只是局部优化。
引入 AI 之后,代码审查标准应该更高,而不是更低。所有开发者都必须对 AI 生成的代码承担最终责任,不能因为“这是 AI 给的”就默认可信。与此同时,更聪明的方式不是只让 AI 写业务逻辑,而是让 AI 去生成测试、构建文档、辅助故障排查、沉淀知识库,用它来夯实整个研发底座。
4. 不要搞大跃进,先建立先锋队制度
真正有效的推进方式,通常不是一夜之间要求几千人改变工作习惯,而是先选出公司内部技术最强、最愿意折腾新工具的那 10% 人作为 AI 先锋队。
让他们先试 1 到 2 个月,摸索最适合本公司业务的 Prompt 模板、最佳实践和避坑规则,再把这些经验沉淀成内部规范,逐步带动剩下的 90%。
这比直接一刀切全员铺开,要稳得多,也更容易形成可复制的组织能力。
结语:AI 是拖拉机,不是摇钱树
回到开头那个故事,那 100 万 Token 的学费其实买来了一个极其重要的教训。
很多老板对 AI 的误解在于,他们以为自己买的是一台印钞机,只要不断往里通电,营收就会自动冒出来。但事实上,AI 编程工具更像是一台马力很强的拖拉机。
如果你本来就是个懂行的农场主,有规范的研发流程、清晰的产品定位、严谨的测试体系和明确的协作边界,这台拖拉机能让你一个人种过去三个人的地,效率优势会非常明显。
但如果你的农场本来就杂草丛生、沟壑纵横,需求混乱、架构腐化、流程失衡、责任不清,那你开着拖拉机冲进去,并不会 magically 收获更多粮食。你只会用更高的速度,把原本混乱的土地翻得更乱,最后还要付出一笔昂贵的油费,也就是那张百万 Token 账单。
所以,企业真正该做的,不是停止幻想后彻底远离 AI,而是放下“AI 一来营收立刻翻倍”的幼稚期待,回到软件工程和组织管理的基本面上来。把流程、度量、测试、权限、协作和知识沉淀这些底层能力补起来,AI 才会真正成为杠杆,而不是新的成本黑洞。