摘要:当大模型从“超级计算器”进化成会调工具、读文件、跑代码的代理型 AI,算力需求的重点也在悄悄变化。GPU 仍然是训练时代的霸主,但在持续执行、低延迟逻辑处理和能效成本都更重要的 AI 执行时代,CPU 正重新成为底层基础设施的核心角色。

过去这几年,只要稍微关注过科技圈,你大概率都被一个词反复刷过屏,那就是 GPU。
随着 ChatGPT 横空出世,英伟达的 GPU 一下子成了全球最抢手的“硬通货”,各大科技公司为了抢卡、堆算力、建集群,几乎把整个产业链都卷进去了。
于是很多人自然形成了一个印象:搞 AI 就必须靠 GPU,CPU 早就退居二线了。
但科技演进经常不是线性推进,而是会在关键节点突然拐弯。
就在大家默认 GPU 会长期统治 AI 世界的时候,亚马逊、Meta 等科技巨头却开始大规模转向另一条路线。尤其是在最新一代 AI 系统的落地阶段,越来越多任务开始回流到 CPU 上,甚至是像 AWS Graviton 这样基于 ARM 架构定制出来的新一代云 CPU。
这件事表面看起来很反直觉,但如果把 AI 的工作内容真正拆开来看,你会发现这其实非常合理。
核心原因只有一句话:AI 的工作,已经从单纯“拼命计算”,变成了“持续思考加执行”。
而一旦 AI 从超级计算器,进化成会跑腿、会调工具、会处理流程的“数字助手”,CPU 的价值就会迅速被重新放大。
第一章:AI 变了,它不再只是一个“超级大百科”
过去一两年里,我们最熟悉的 AI 形态,其实是大语言模型。
你给它一段提示词,它就在内部做海量矩阵运算,最后生成一段回答。整个过程的核心是“算”,而且是那种极度适合并行化的大规模数学计算。
这种模式下,GPU 天生占优。因为 GPU 最擅长的事情,就是把大量相似计算同时铺开,一口气并行完成。
但现在,AI 正在从“生成式 AI”走向“代理型 AI”。
什么叫代理型 AI?简单说,它不只是回答你的问题,而是开始替你完成任务。
比如过去你问它:
- 苹果公司的历史是什么?
它会生成一段文字,任务就结束了。
但现在你可能会对它说:
- 帮我查一下 A 公司最近的财务状况
- 对比一下竞争对手的数据
- 把结果整理成一份汇报
- 再发一封邮件给老板
这时候,AI 已经不是一个“在脑子里计算答案”的系统,而是在执行一个多步骤流程。
它要先拆解任务,再调用网页搜索、文件读取、代码执行、表格分析、邮件发送等一连串工具。整个过程中,它会不断经历这样一个循环:
思考 → 行动 → 获取结果 → 再思考下一步。
问题就在这里。
除了生成文字的那一小段时间之外,这种代理型 AI 的大部分工作,其实都不是传统意义上的“大规模并行计算”,而是大量琐碎的逻辑判断、系统调用、外部交互与任务编排。
而这部分活,恰恰不是 GPU 最舒服的领域,反而是 CPU 的传统主场。
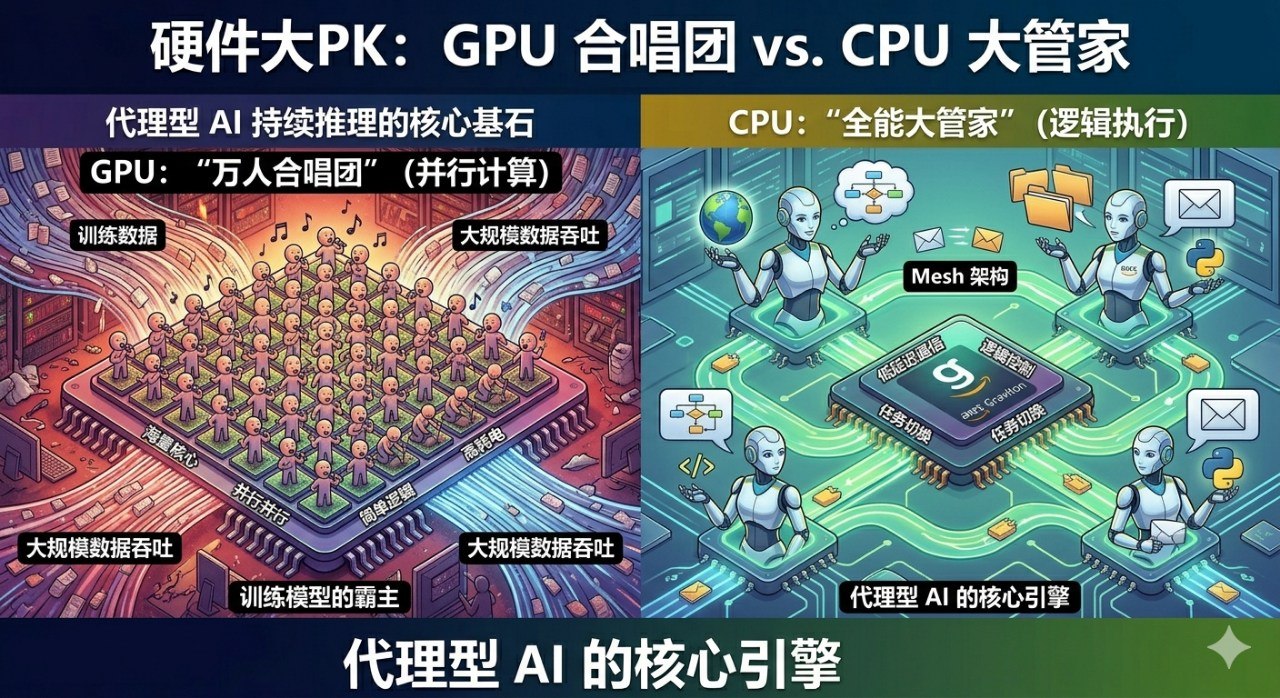
第二章:GPU 和 CPU,本来就不是一类“选手”
要理解为什么 CPU 会重新变重要,关键不是记参数,而是理解 GPU 和 CPU 的“性格差异”。
1. GPU 更像“万人大合唱”
GPU 最初是为图形计算设计的。图像处理有一个非常典型的特点,就是任务量巨大,但每个小任务的形式又高度重复,比如成千上万个像素点同时计算。
所以 GPU 的设计思路是,尽可能塞进去大量核心,让它们一起执行类似的计算。
你可以把 GPU 想象成一支几千上万人组成的大合唱团。只要任务统一、节奏一致、动作整齐,比如一起唱同一首歌,或者一起挥锄头挖战壕,它的效率会高得惊人。
这就是为什么 GPU 特别适合训练大模型,或者做大规模推理吞吐。
2. CPU 更像“全能大管家”
CPU 的路子完全不一样。
它的核心数量通常比 GPU 少得多,但每个核心都更复杂、更聪明,也更擅长处理变化频繁、逻辑分支很多的任务。
如果把 GPU 比作大合唱团,那 CPU 更像一组经验老到的大管家。人数不算夸张,但每个人都能处理复杂事务,知道什么时候切换任务,什么时候优先处理紧急事项,什么时候根据上下文临时调整流程。
而代理型 AI 的日常工作,本质上恰恰像这种“杂而细”的项目管理。
它要:
- 做逻辑判断
- 跳转不同任务分支
- 调各种外部接口
- 频繁读写文件
- 执行系统命令
- 管理上下文状态
这种场景下,GPU 当然不是完全不能做,但它并不擅长。因为这不是“让一万人做同一件事”,而是“让少数很聪明的人不断协调、切换、响应和处理异常”。
这时候,CPU 的优势就会非常明显。
第三章:代理型 AI 真正拼的是持续执行,不只是峰值算力
训练时代的 AI,更看重吞吐量。
企业把海量数据打包扔给训练集群,只要整体训练速度够快,哪怕过程中的局部延迟大一点,也不会有太大问题。GPU 在这里像一台超大功率的工业炼炉,适合干这种集中式爆发计算。
但代理型 AI 完全不同。
代理型 AI 是在线服务,它面向的是人,服务的是实时任务,所以它更在乎两个东西:
- 延迟够不够低
- 状态切换够不够快
你可以想象一个 AI 助手正在替你订机票。它前一秒还在理解你的需求,下一秒就要去查网站,再下一秒可能要解析一个页面、对比几种方案,随后还得把结果整理出来,甚至进一步去下单。
整个过程中,系统内部会有大量模块不断交换信息。一个模块刚完成判断,另一个模块就要立刻接手。如果这些环节之间的数据传递和逻辑切换不够快,AI 就会显得反应迟钝,像总在发呆。
而像 AWS Graviton 这类专门为云场景优化的 CPU,恰恰在这种持续低延迟执行上有非常强的竞争力。
尤其是当代理型 AI 进入企业应用、SaaS 工作流、云端协作系统之后,它需要的往往不是“最暴力的单点算力”,而是一个能长时间稳定运转、逻辑切换流畅、内部通信高效的执行底座。
这就是为什么很多公司在构建 AI 执行层时,不再只是盯着 GPU 数量,而开始重新重视 CPU 架构本身。
第四章:最后逼巨头转向 CPU 的,其实是那本算不过来的经济账
技术逻辑是一方面,更残酷的其实是商业现实。
哪怕 GPU 理论上能干很多代理型 AI 的活,企业在大规模部署时,也未必真的愿意这么干。
原因很简单,太贵,也太耗电。
1. 训练是一次性猛烧,执行是 7×24 小时长期消耗
训练大模型当然非常耗电,但它再耗,本质上仍然是阶段性的。训练完了,这一轮超高功耗也就过去了。
可代理型 AI 不一样。
一旦 AI 被推向真实市场,开始给几亿、几十亿用户提供服务,它就会进入一种几乎不间断运转的状态。系统可能不是时时刻刻都在做最重的推理,但它始终在线,始终要响应,始终要处理任务流。
这就意味着,运行成本不再只是“偶尔爆发”,而是变成长期、稳定、持续的消耗。
如果你用大量高功耗 GPU 去承担这些执行型工作,就像开着一辆重型主战坦克去通勤。不是不能开,而是油钱和维护成本会让你先崩掉。
2. ARM 架构 CPU 的高能效,开始变成战略级优势
这也是为什么 AWS Graviton 这类基于 ARM 的 CPU 会越来越重要。
ARM 架构本身就以高能效著称,这种优势过去在手机和移动设备上已经被证明过很多年了。如今当 AI 服务进入大规模云端执行阶段,这种“在较低功耗下维持稳定性能”的能力,开始变成巨头最在意的指标之一。
对于云厂商来说,这不仅仅是芯片采购问题,而是整个数据中心的总体拥有成本问题,包括:
- 电费
- 散热成本
- 机房承载能力
- 碳排放压力
- 长期扩容的可持续性
当 AI 服务从少数高价值试验,变成面向海量用户的基础设施时,能效就不再是“加分项”,而是“生死线”。
这也是为什么 CPU 在 AI 执行时代并不是作为 GPU 的替代者出现,而是作为真正能把系统跑长期、跑稳定、跑得起的底层基石重新回到中心。
结语:不是 GPU 失势了,而是 AI 进入了一个“各司其职”的新阶段
看到这里,应该已经很清楚了。
CPU 的重新崛起,并不意味着 GPU 被淘汰。GPU 仍然会在未来很长时间里继续统治大模型训练,以及那些高度并行的大规模推理任务。它依然是 AI 世界里最重要的“炼丹炉”。
但问题在于,AI 的世界已经不只剩下炼丹了。
当模型训练完成,真正走进企业系统、办公流程、消费应用和云服务之后,AI 的角色正在从“超级计算器”变成“会持续执行的数字代理”。
而在这个阶段,系统最需要的不只是算力峰值,而是:
- 持续执行能力
- 复杂逻辑处理能力
- 低延迟响应能力
- 更好的能效比
- 更可控的长期成本
这些能力,恰恰都是 CPU 重新发光的地方。
所以,与其说 CPU 是在 GPU 时代完成了“复仇”,不如说 AI 正在进入一个新的硬件分工时代。
GPU 继续负责把模型练出来,CPU 负责让这些模型真正把事情做起来。
这不是一次简单的角色轮换,而是 AI 从“训练时代”迈向“执行时代”的底层信号。未来真正成熟的 AI 基础设施,极可能就建立在这种新的协同关系之上。