摘要:在 AI 辅助编码的时代,开发者面临的最大瓶颈不再是“代码写不完”,而是“AI 读不懂整个代码库”。传统 AI 工具,如 Claude、Cursor、Copilot,依赖上下文窗口和简单 grep 搜索,面对企业级 4000 万行以上代码库时,往往陷入幻觉、工具调用爆炸或上下文溢出。SocratiCode 正是在这一痛点上诞生的开源解决方案,一个零配置、本地私有、MCP 协议驱动的代码库上下文引擎。它自动管理索引、混合语义搜索、多语言依赖图,以及非代码基础设施知识,让 AI 瞬间“理解”整个项目。 SocratiCode 由 giancarloerra 开发并开源(GitHub: giancarloerra/socraticode),已通过 VS Code 245 万行真实代码库基准测试。相比传统“AI + grep”模式,它将上下文消耗减少 61.5%,工具调用减少 84%,响应速度提升 37 倍。项目采用 Docker 托管 Qdrant 向量数据库和 Ollama 嵌入服务器,默认完全本地运行,无需 API 密钥,支持 air-gapped 环境。同时,它为 Claude Code、Cursor、VS Code Copilot、Zed、Gemini CLI 等平台提供原生插件或 MCP 集成。 本文将从架构、索引管道、搜索机制、依赖图、上下文工件、MCP 工具集、性能基准到配置扩展,全面拆解它的技术实现,理解其“一个工具,只做一件事”的极简设计哲学。
在 AI 辅助编码的时代,开发者面临的最大瓶颈不再是“代码写不完”,而是“AI 读不懂整个代码库”。传统 AI 工具,如 Claude、Cursor、Copilot,依赖上下文窗口和简单 grep 搜索,面对企业级 4000 万行以上代码库时,往往陷入幻觉、工具调用爆炸或上下文溢出。SocratiCode 正是在这一痛点上诞生的开源解决方案,一个零配置、本地私有、MCP 协议驱动的代码库上下文引擎。它自动管理索引、混合语义搜索、多语言依赖图,以及非代码基础设施知识,让 AI 瞬间“理解”整个项目。
SocratiCode 由 giancarloerra 开发并开源(GitHub: giancarloerra/socraticode),已通过 VS Code 245 万行真实代码库基准测试。相比传统“AI + grep”模式,它将上下文消耗减少 61.5%,工具调用减少 84%,响应速度提升 37 倍。项目采用 Docker 托管 Qdrant 向量数据库和 Ollama 嵌入服务器,默认完全本地运行,无需 API 密钥,支持 air-gapped 环境。同时,它为 Claude Code、Cursor、VS Code Copilot、Zed、Gemini CLI 等平台提供原生插件或 MCP 集成。
本文将从架构、索引管道、搜索机制、依赖图、上下文工件、MCP 工具集、性能基准到配置扩展,全面拆解它的技术实现,理解其“一个工具,只做一件事”的极简设计哲学。
一、为什么需要 SocratiCode?
传统代码搜索工具,如 ripgrep、AST-based grep,只能处理关键词,无法捕捉“认证中间件”这类概念查询。向量搜索虽然能做语义匹配,但往往缺乏精确关键词融合和依赖关系分析。更现实的问题是,大多数方案要么依赖云 API,存在隐私和成本问题;要么安装链条复杂,需要手工拼装向量数据库、嵌入模型和中间服务。
SocratiCode 的设计目标非常明确,就是**“一个工具,做一件极致的事”**,为任意 AI 提供即时、自动化、全局代码库知识。
它的核心价值主要体现在四点:
- 零配置:
npx -y socraticode或 MCP JSON 配置即可启动。 - 完全本地:Docker 自动拉起 Qdrant v1.17.0 和 Ollama 容器,使用
socraticode_qdrant_data、socraticode_ollama_data持久化数据。 - 企业级规模:支持 4000 万+ 行代码,依靠批处理、checkpoint 和增量索引保证稳定性。
- 多代理协作:多个 AI 实例共享同一索引,通过
proper-lockfile跨进程协调,只保留一个有效 watcher。
它借用了苏格拉底的那句名言,“知识是唯一的善,愚昧是唯一的恶”。放在 AI 编码时代,这句话几乎可以直接翻译成一句工程宣言:真正限制 AI 的,不是生成能力,而是上下文知识质量。
二、整体架构:MCP Server + Docker 托管基础设施
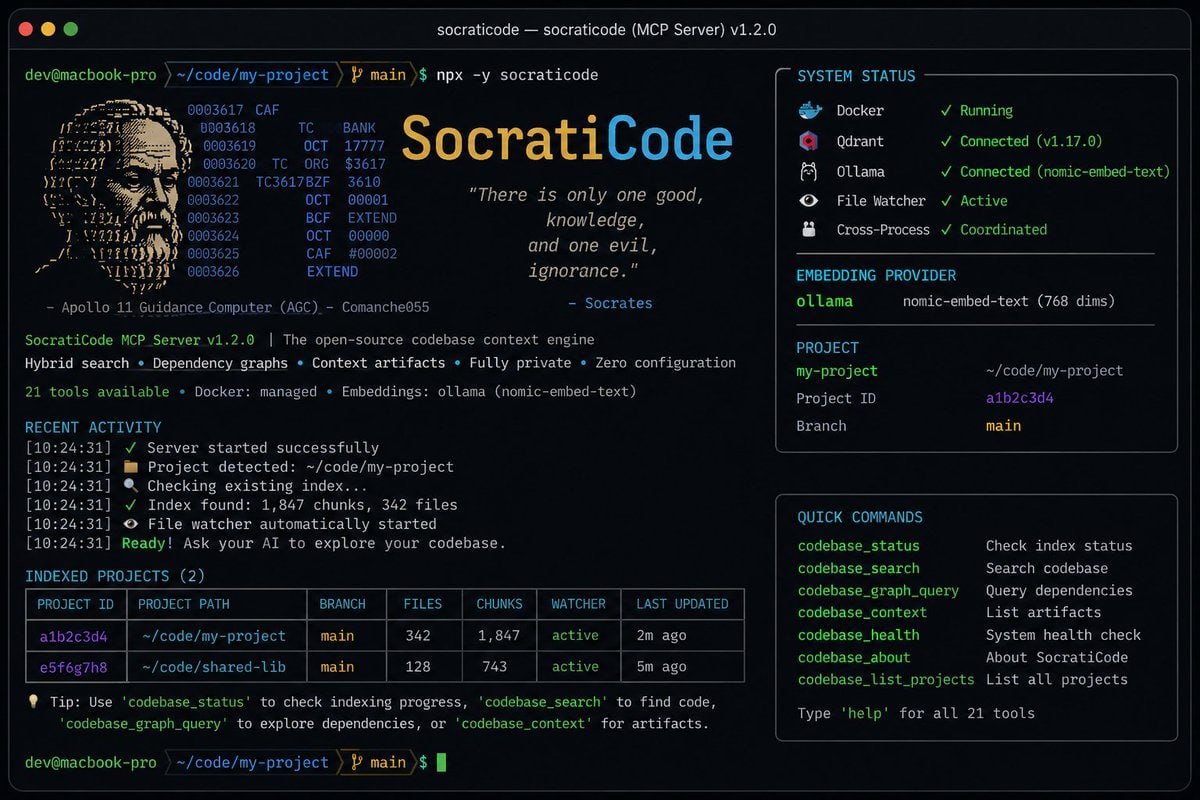
SocratiCode 本质上是一个基于 Node.js 18+ 实现的 MCP(Model Context Protocol)服务器,对外暴露 21 个标准化工具,覆盖索引、搜索、图操作和管理能力。
默认启动流程非常简洁:
- 自动检测 Docker,并拉取
socraticode-qdrant和socraticode-ollama镜像。 - 启动容器,Qdrant 占用 REST
16333、gRPC16334,Ollama 占用11435。 - 下载默认嵌入模型
nomic-embed-text。 - 扫描当前项目目录,构建索引、依赖图和 watcher。
整个系统可以理解为三层结构:
- 基础设施层:Qdrant 负责 HNSW 向量索引、payload filtering 和 BM25 稀疏向量,Ollama 或外部 OpenAI/Gemini 提供嵌入模型。
- 核心引擎层:Node.js 负责文件发现、AST 分块、嵌入生成、依赖图构建以及锁管理。
- 协议层:MCP 工具接口,兼容 Claude Desktop、Cursor、Claude Code、Gemini CLI 等宿主。
它支持三种典型部署模式:
- 托管模式:默认启用,零配置 Docker。
- 外部模式:通过
QDRANT_MODE=external和OLLAMA_MODE=external接入自托管或云服务。 - 分支感知模式:设置
SOCRATICODE_BRANCH_AWARE=true后,每个 Git 分支独立持有一个 collection。
这里有一个很容易被忽略、但非常重要的工程细节,就是跨进程安全。SocratiCode 使用 proper-lockfile 防止多个实例重复做索引或同时启动 watcher。进程崩溃时,锁会自动回收,关闭时还会给索引任务 60 秒宽限期完成当前批次。这种细节决定了它是不是一个“玩具工具”,还是一个能进入真实团队工作流的基础设施组件。
三、索引管道:AST-aware 分块 + 批处理 + 可恢复设计
索引是 SocratiCode 最强的竞争力之一,因为它解决了传统向量索引最常见的两个问题:语义割裂和大规模不可靠。
1. 文件发现
它会递归扫描项目目录,同时尊重 .gitignore 和 .socraticodeignore。默认支持 54+ 文件类型,包括 Dockerfile、SQL 等基础设施文件,也可以用 EXTRA_EXTENSIONS 补充自定义扩展名。单文件默认大小上限为 MAX_FILE_SIZE_MB=5。
2. 语义分块
SocratiCode 的主路径不是简单的“每 200 行切一次”,而是 AST-aware chunking。
- 对于 JS/TS、Python、Java、Go、Rust 等 18+ 语言,它使用
ast-grep在函数、类、模块边界上切块。 - 对于不支持 AST 的语言,则退回到行式分块策略。
- 对 TypeScript 项目,还额外支持
tsconfig.json路径别名解析。
这一步非常关键。因为固定长度分块最大的缺陷,就是容易把一个函数切成两半,把一个类拆成前后两个无关片段,最终让嵌入向量失去结构语义。而 AST-aware 分块能让一个 chunk 更像“一个完整语义单元”,这会直接影响后续检索质量。
3. 嵌入与存储
每个 chunk 会同时生成两套表示:
- dense vector,用来表达语义相似度
- BM25 sparse vector,用来表达关键词精确匹配
索引过程采用批处理方式,每 50 个文件作为一组,结合并行 I/O 和批量嵌入减少开销。每个批次结束后,都会把 checkpoint 写入 Qdrant,因此整个索引过程是可恢复的。
这意味着即使在 4000 万行这种超大规模代码库中,索引中途被中断,也不需要从头再来。后续增量索引则基于内容哈希,只重建变更文件,首次索引可能较重,但后续更新可以做到秒级。
4. 文件监听
Watcher 采用 2 秒 debounce 机制,文件发生变化后,会自动触发增量更新,并使图缓存失效。更妙的是,第一次调用搜索工具时,它才会自动启动 watcher,这让系统默认更轻量,也更适合多代理共享。
四、混合搜索机制:Qdrant + RRF 融合
搜索是 AI 决策的起点。SocratiCode 采用的不是单纯向量搜索,而是 Qdrant 原生混合查询。
每个 chunk 同时保存 dense 向量和 BM25 sparse 向量。一次查询会并行执行两套检索:
- 语义搜索,理解“认证中间件”“结算主流程”这类概念问题
- 关键词搜索,精确命中标识符、类名、函数名和常量
两路结果再通过 RRF(Reciprocal Rank Fusion) 做统一排序,避免用户手工调权重。
再配合路径、语言、项目、分支过滤器,以及 SEARCH_MIN_SCORE=0.10 这样的噪声过滤参数,SocratiCode 能在大规模工程里同时兼顾“懂意思”和“找得准”。
这套设计的实际意义非常大。传统 grep 很准,但听不懂概念;纯向量搜索能猜意思,但常常对工程命名一头雾水。SocratiCode 的混合搜索,本质上是在让 AI 同时拥有“语言理解能力”和“工程检索能力”。
五、多语言依赖图:Polyglot 静态分析 + 可视化
如果说混合搜索解决的是“找内容”,那依赖图解决的就是“理解结构”。这也是 SocratiCode 和普通向量工具最大的差异之一。
它使用 ast-grep 静态分析 import、require、use、include 等语句,自动构建多语言依赖图,并支持 tsconfig 路径别名解析。索引完成后自动建图,watcher 更新时也会触发重建。
围绕这个图,它提供了一整套工具:
codebase_graph_query查询 imports 或 dependentscodebase_graph_stats查看最连接文件、孤儿模块、语言分布codebase_graph_circular检测循环依赖codebase_graph_visualize输出 Mermaid 图并按语言着色
这件事对 AI 的价值很大。很多时候,AI 不是看不懂一个函数,而是看不懂这个函数在整个模块树、服务边界和依赖关系里的位置。依赖图正是把这种结构知识显式化,让 AI 不必通过“读 20 个文件”来猜项目结构。
六、上下文工件:把非代码知识也纳入统一索引
真实项目里,真正影响开发决策的知识不只有代码。数据库 Schema、API 规范、基础设施配置、架构文档,这些东西同样重要。
SocratiCode 用根目录的 .socraticodecontextartifacts.json 来描述这些工件,例如:
1 | { |
这些工件会像代码 chunk 一样被分块、嵌入,并存入独立的 Qdrant collection,然后通过 codebase_context_search 统一检索。
这一步非常像把“项目外脑”也内建进了 AI 的认知系统。它让 AI 不再只会读 src/,而是真正能理解一个项目运行所依赖的完整知识边界。
七、MCP 工具集:21 个工具驱动完整工作流
SocratiCode 总共暴露 21 个 MCP 工具,基本覆盖了一个 AI 编码助手所需的完整工作流。
大致可以分成几类:
- 索引管理:
codebase_index、codebase_update、codebase_watch、codebase_stop - 搜索能力:
codebase_search、codebase_status - 依赖图工具:
codebase_graph_build、codebase_graph_query等 6 个 - 上下文工件:
codebase_context_index等 4 个 - 系统管理:
codebase_health、codebase_list_projects、codebase_about
它的插件模式还会附带 workflow skills 和 agent instructions,强调“先搜再读”的行为原则。这其实是一种非常成熟的 agent tool design 思路,不是给 AI 无限工具,而是让它遵循一套高效、低幻觉的工作纪律。
八、性能基准:为什么它能快 37 倍?
SocratiCode 最打动人的,不只是设计漂亮,而是它拿真实工程做了实测。
在 VS Code 仓库,245 万行代码、5300+ 文件、5.5 万个 chunk 的测试中,使用 Claude Opus 4.6 回答架构问题,结果是:
- 上下文消耗减少 61.5%
- 工具调用减少 84%
- 响应速度提升 37 倍
这不是“跑 benchmark script”的漂亮数字,而是更接近真实工作场景的实验。它说明 SocratiCode 的价值并不只是“搜得更准”,而是系统性地减少 token 浪费、工具爆炸和上下文污染。
对企业团队来说,这些指标最终会转化成三件更现实的东西:更少的幻觉、更快的回答、更低的成本。
九、配置与企业扩展性
虽然 SocratiCode 默认零配置启动,但它并不是“不可扩展的黑盒”。它开放了大量环境变量,足以支持复杂团队场景。
例如:
- 嵌入配置:
EMBEDDING_PROVIDER=ollama|openai|google、EMBEDDING_MODEL - 向量库配置:
QDRANT_MODE=managed|external、QDRANT_API_KEY - 高级行为:
SOCRATICODE_BRANCH_AWARE、RESPECT_GITIGNORE、SEARCH_DEFAULT_LIMIT - 自定义能力:
EXTRA_EXTENSIONS、MAX_FILE_SIZE_MB、SOCRATICODE_LOG_LEVEL
它支持多项目、Git worktree、结构化日志,还在推进私有 beta 的 SocratiCode Cloud,用于团队共享索引、SSO、审计日志等企业能力。
这说明它不是只为个人 hacker 设计,而是具备向团队协作平台演进的架构弹性。
十、总结:它不是插件,而是 AI 时代的代码库操作系统
SocratiCode 的真正价值,不在于“又多了一个 AI 编程插件”,而在于它重新定义了 代码库知识如何被 AI 获取和消费。
AST-aware 分块、混合 RRF 搜索、多语言依赖图、上下文工件、跨进程协调,再加上零配置和本地私有部署,这些能力组合起来,让它更像一个“代码库上下文操作系统”,而不是单点工具。
它抓住了 AI 编程真正的核心矛盾,不是模型不会写代码,而是模型缺乏足够高质量、结构化、可检索的代码库知识。谁先解决这一层,谁就更接近真正可靠的 AI 工程工作流。
在这个意义上,SocratiCode 代表的是一条很明确的方向:本地私有 + 深度结构化知识 + 面向多代理协作的基础设施化设计。随着语言支持继续扩大、云协作能力增强,它很可能会成为未来开发者工作流里的默认底座。