摘要:在 AI 浪潮席卷全球的当下,“AI 工程师”已经成为科技行业最炙手可热的高薪岗位之一。不同于传统机器学习研究者或数据科学家,AI 工程师的核心任务不是从头训练模型,而是把大语言模型真正落地到生产环境中,构建可靠、可扩展、可维护的完整系统。 这份路线图源于 Alexey Grigorev 的开源项目《AI Engineering Field Guide》。该项目分析了超过 2445 个职位 JD、5694 个职责描述和 4525 个实际用例,从中提炼出真正驱动 80% 工作产出的 20% 核心技能。对于想转型或进阶的工程师来说,这不是一份“概念清单”,而是一张非常务实的实战导航图。
在 AI 浪潮席卷全球的当下,“AI 工程师”已经成为科技行业最炙手可热的高薪岗位之一。不同于传统机器学习研究者或数据科学家,AI 工程师的核心任务不是从头训练模型,而是把大语言模型真正落地到生产环境中,构建可靠、可扩展、可维护的完整系统。
这份路线图源于 Alexey Grigorev 的开源项目《AI Engineering Field Guide》。该项目分析了超过 2445 个职位 JD、5694 个职责描述和 4525 个实际用例,从中提炼出真正驱动 80% 工作产出的 20% 核心技能。对于想转型或进阶的工程师来说,这不是一份“概念清单”,而是一张非常务实的实战导航图。
一、AI 工程的核心本质:不是训练模型,而是构建系统
传统 ML 工程师可能会把大量时间投入在数据清洗、特征工程和模型训练上,而 AI 工程师 80% 的工作,其实是围绕现有 LLM 构建生产级应用。
核心不在“模型有多强”,而在“系统是否能稳定交付价值”。一个真正可用的 AI 系统,往往不仅包含模型本身,还包括:
- RAG 检索增强
- Agent 工具调用
- 评估与测试体系
- 监控与可观测性
- 安全与防护机制
- 部署、扩展与持续迭代
也正因此,这份路线图把能力拆成两类:
- 核心 20% 技能:决定 80% 产出的主战场
- 支持技能:让 AI 系统真正落地的工程底座
二、核心技能:20% 决定 80% 产出
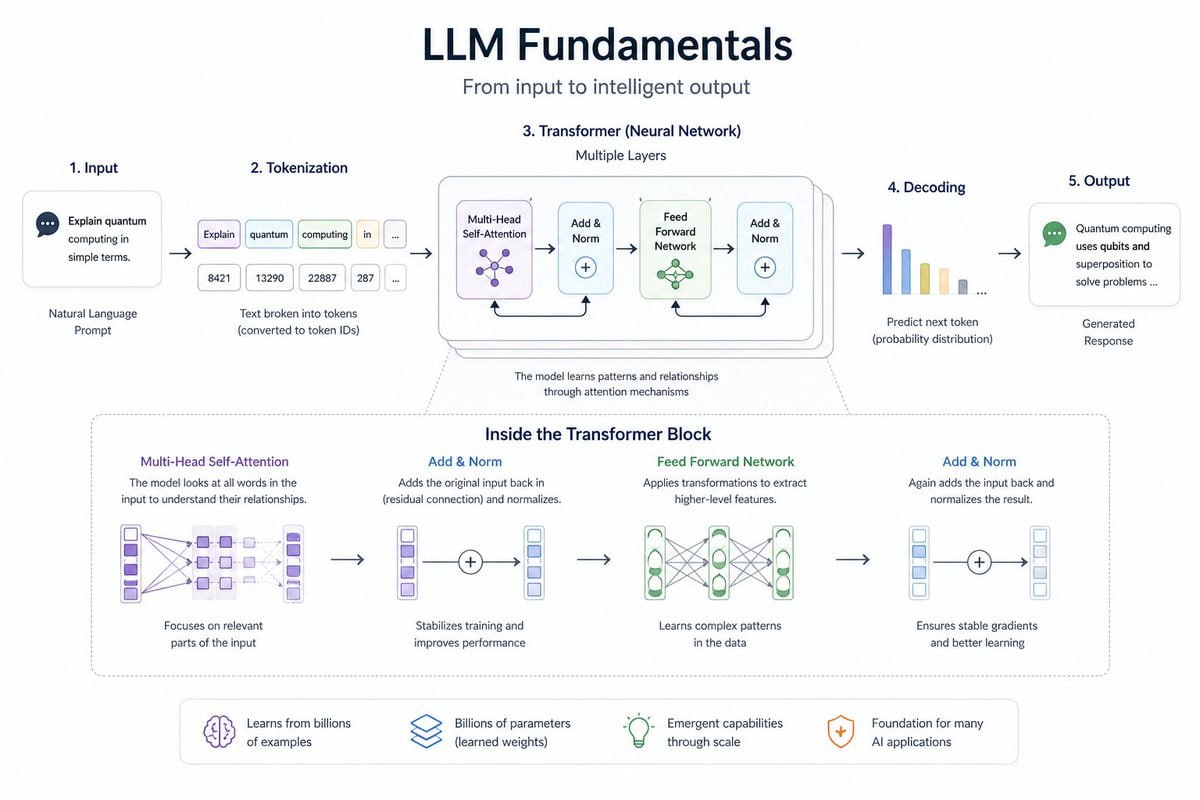
1. LLM 基础:一切的起点
先别急着扑向各种高级框架,第一步是搞懂 LLM 这个“黑箱”到底在做什么。
你至少需要掌握:
- Transformer、注意力机制、Tokenization 的高层原理
- LLM 的优势与局限
- 擅长生成、总结、推理、分类
- 但容易 hallucination
- 存在上下文长度限制
- 受到知识截止日期约束
- 熟练调用 OpenAI、Anthropic、Groq 等 API
- 学会做结构化输出,如 JSON Schema、Tool Calls
- 掌握 Prompt Engineering:从基础提示到 Chain-of-Thought、ReAct、多轮对话控制
这一步的目标,不是“和模型聊得开心”,而是把模型从“不可控聊天对象”变成“可预测系统组件”。
建议实践:第一周就用 Python + OpenAI SDK 做 10 个小 demo,例如:
- 自动生成结构化日报
- 抽取简历字段
- 生成会议纪要
- 识别投诉类型并给出处理建议
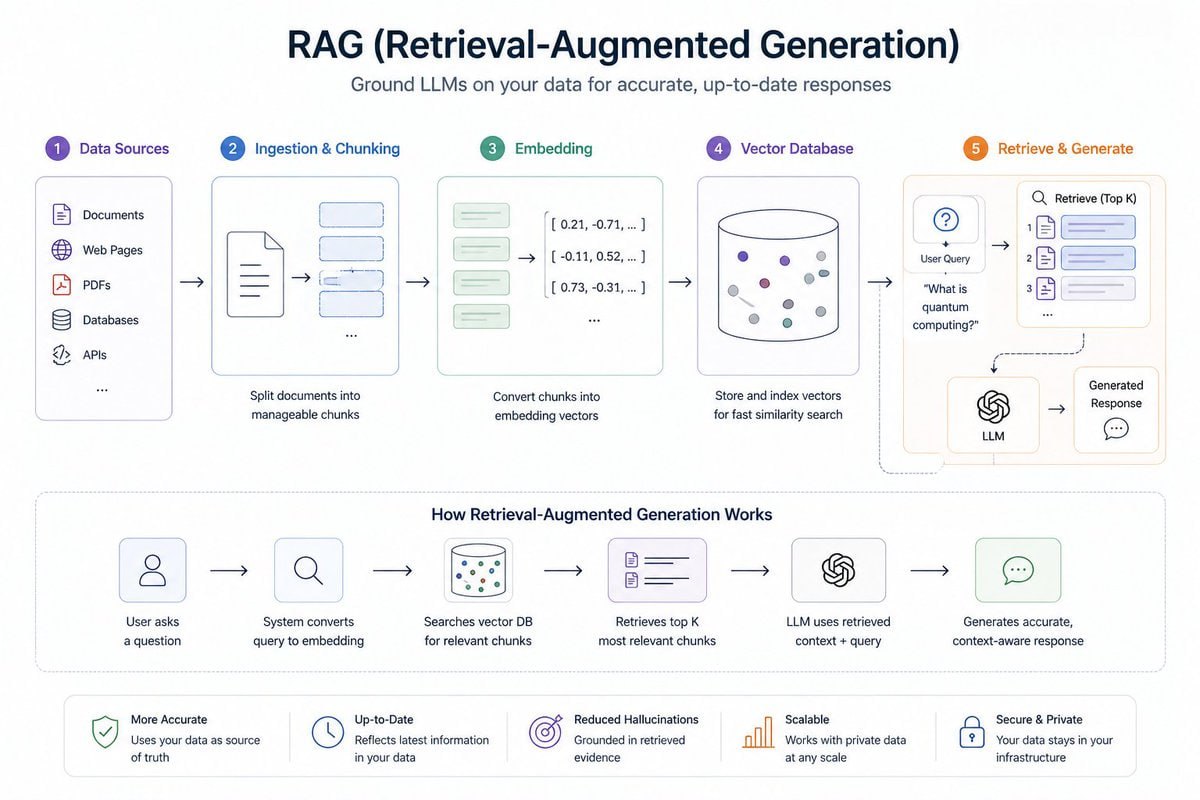
2. RAG:真实世界 AI 系统的脊梁
如果说 LLM 是大脑,那么 RAG(Retrieval-Augmented Generation)就是企业 AI 应用真正的知识供血系统。
在现实业务中,企业最关心的不是模型“会不会聊天”,而是它能不能基于公司自己的资料说对话、办对事。RAG 正是为了解决 LLM 的两个硬伤:
- 知识过时
- 幻觉严重
它通过检索企业私有数据,把“通用模型”变成“懂业务的系统”。
关键技术点包括:
- 文档处理:PDF、网页、会议纪要、转录文本等内容清洗与切分
- Chunking 策略:固定长度切分 vs 语义切分
- 向量数据库:Pinecone、Weaviate、Qdrant、pgvector、Elasticsearch
- 检索优化:Hybrid Search、Reranking、Query Rewrite
典型项目:
- 内部 FAQ 助手
- 文档智能问答系统
- 企业知识库搜索平台
掌握 RAG 后,你就能把一个“泛化大模型”改造成“企业专属大脑”。这正是当下招聘市场最看重的落地能力之一。
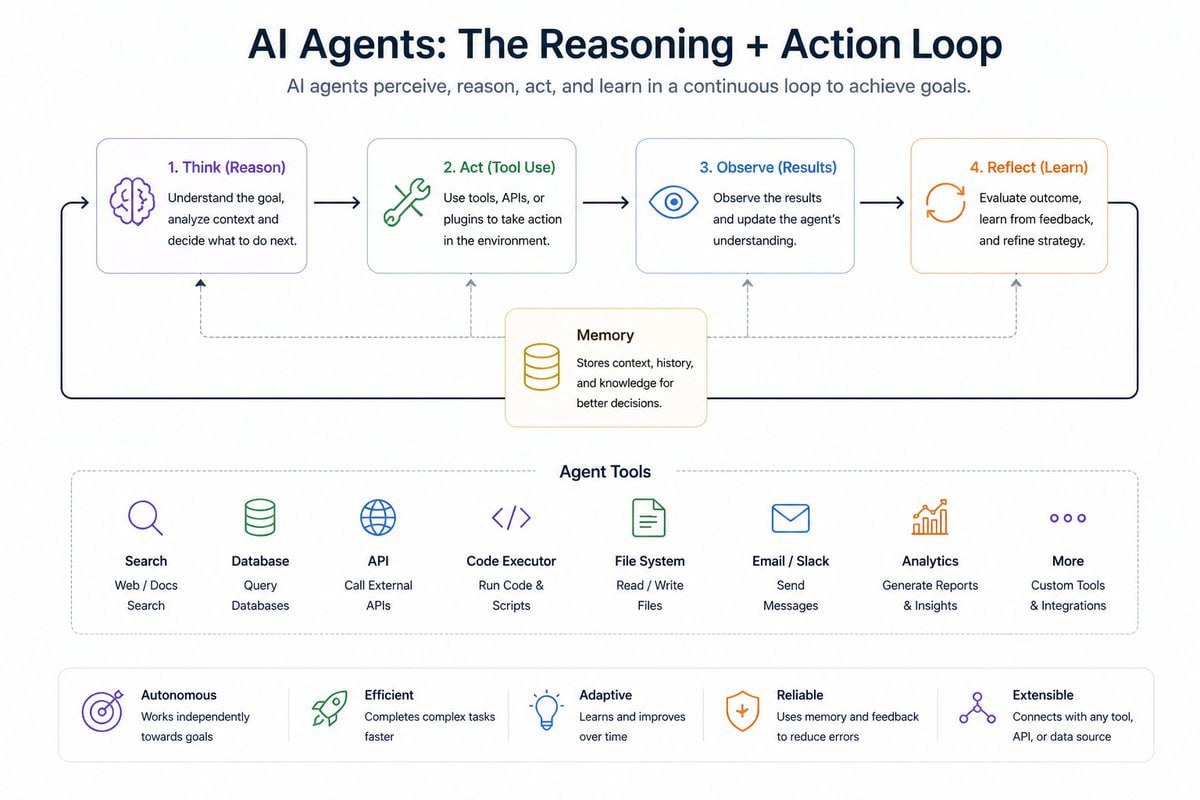
3. AI Agent:让 LLM 真正“行动”起来
Agent 是当前最火的 AI 工程方向之一。它意味着模型不再只是回答问题,而是开始调用工具、执行步骤、迭代观察,并自主完成复杂任务。
它的核心逻辑通常是:
Think → Act → Observe → Repeat
你需要理解的关键概念有:
- Tool Calling / Function Calling
- Agent Loop 与状态管理
- 多步任务拆解
- 失败重试与异常处理
- 多 Agent 协同
常见框架包括:
- LangChain
- LangGraph
- PydanticAI
- OpenAI Agents SDK
- Google ADK
还有一个越来越重要的能力栈:
- MCP(Model Context Protocol)
- 多 Agent 路由、协调与流水线编排
典型项目:
- 自动搜集资料并总结的研究 Agent
- 数据提取与清洗流水线
- 销售、客服、分析多 Agent 协同系统
Agent 的价值很高,但挑战也很大,因为它把非确定性放大到了系统层。真正会做 Agent 的工程师,和只会“写几个 prompt”的人,差距非常明显。
4. 测试 AI 系统:被严重低估的能力
传统软件有单元测试和集成测试,AI 系统同样需要测试,只不过测试对象从“函数返回值”变成了“输出质量与行为稳定性”。
你需要关注:
- Tool Usage 是否正确
- 最终输出是否符合预期
- 边界条件下是否稳定
- 多轮任务里是否会逐步偏航
常见方法包括:
- Golden Dataset 测试
- 一致性测试
- 鲁棒性测试
- 边缘案例测试
- LLM-as-a-Judge / Meta-Evaluation
很多 AI Demo 看起来很惊艳,但一到真实环境就崩,根源往往不是模型不够强,而是没有测试体系。
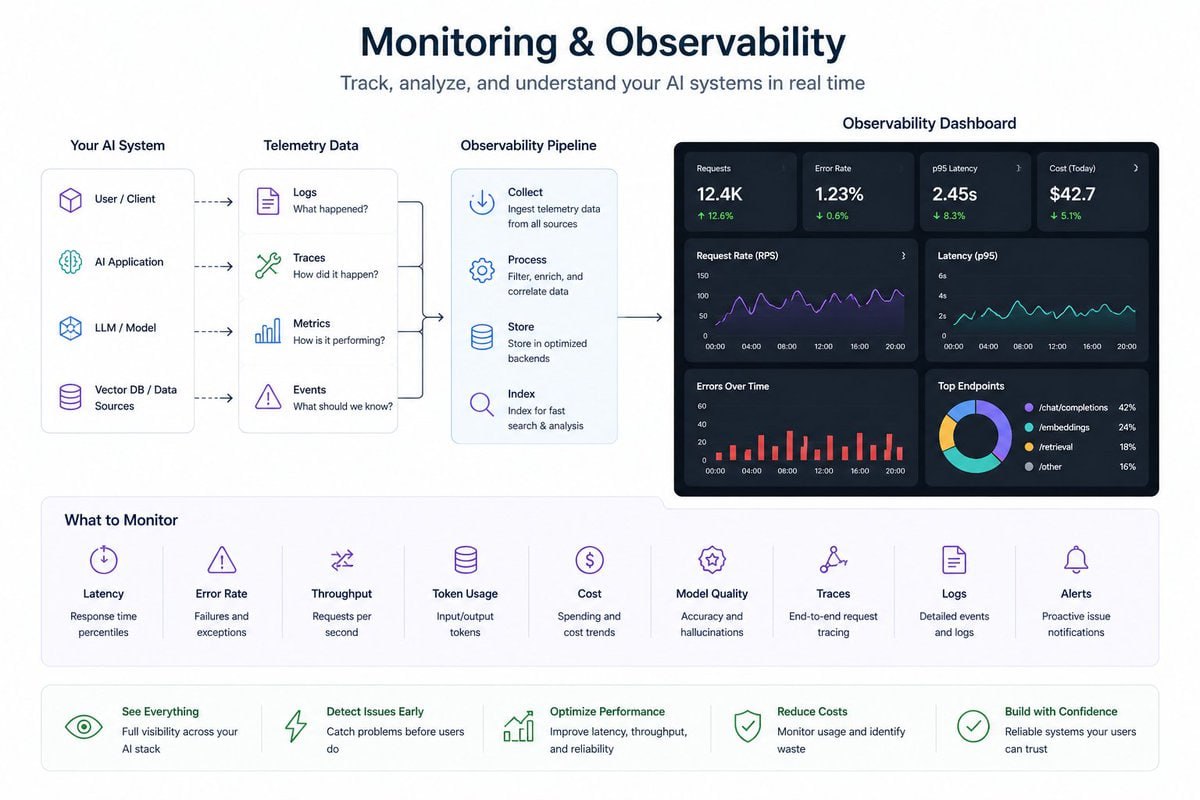
5. 监控与可观测性:从 Demo 到 Production 的分水岭
生产环境里,如果你看不到系统在做什么,就没法持续优化它。
AI 工程师必须建立对系统行为的可观测性,包括:
- Agent 工作流 tracing
- 请求日志与交互记录
- Token 与成本追踪
- 响应时延、失败率、重试次数
- 用户反馈闭环
常见工具:
- OpenTelemetry
- Grafana
- Prometheus
企业在面试中常问的一个问题非常直接:
“你的 AI 系统上线后,怎么监控性能、成本和失败原因?”
这个问题答得好不好,往往决定你在面试官心里更像“做 Demo 的人”,还是“能扛生产的人”。
6. 评估(Evaluation):从“感觉不错”到“数据说话”
AI 输出本质上是概率性的,所以不能只靠主观感觉判断系统是否变好了。
评估体系通常包括:
- Offline Eval 数据集构建
- 检索质量指标:Recall、NDCG
- 输出质量评分
- 合成数据生成
- Prompt / Pipeline 优化闭环
真正成熟的 AI 工程团队,会把“改了一个 prompt”变成“某项指标提升了 23%”。
而这,正是很多候选人欠缺的能力:
- 他们会调 prompt
- 但不会证明效果提升
- 更不会建立可持续迭代机制
能把评估讲清楚,往往就是你在面试中脱颖而出的关键差异点。
7. 生产系统构建:AI 工程师的终极价值
Notebook 里的原型不是产品,真正的价值在于把原型变成服务。
你需要会的生产化能力包括:
- 快速原型:Streamlit / Gradio
- 后端服务:FastAPI
- 容器化:Docker
- 上云部署:AWS、GCP、Azure
- 编排扩展:Kubernetes
- 安全防护:Guardrails、Prompt Injection 防御
- 性能扩展:并行处理、缓存、负载均衡
说到底,AI 工程师最核心的价值不是“调出一个惊艳结果”,而是让这个结果能够:
- 被稳定调用
- 被多人使用
- 被持续监控
- 被安全维护
三、支持技能:JD 里反复出现的“隐形要求”
这些能力不是 AI 专属,但几乎是所有 AI 工程岗位的底层共识。
1. Python 工程基础
这是 AI 工程师最硬的基本功之一,包含:
- 测试
- CI/CD
- Git
- 包管理
- 代码质量控制
很多岗位写的是“会大模型”,真正筛人时看的却是:你写的代码能不能进团队主干分支。
2. Web 开发
AI 系统不是只活在 Jupyter Notebook 里,它最终得通过产品界面和 API 被使用。
- 后端:FastAPI 几乎是 AI 后端标配
- 前端:React / Next.js 常用于 AI 产品交互层
- 接口:REST / GraphQL
3. 云与基础设施
至少掌握一朵云已经是常态要求:
- AWS / GCP / Azure
- Docker(几乎必备)
- Kubernetes
- Terraform
4. 数据库
AI 系统很少只依赖向量库,通常需要传统数据库和缓存一起配合:
- PostgreSQL + pgvector
- Redis
- Pinecone / Qdrant / Weaviate
- Elasticsearch
5. ML 基础
虽然 AI 工程师未必天天训练模型,但你还是需要理解:
- Embeddings
- 基础 PyTorch
- 轻量 Fine-tuning
- 模型评估
6. 数据工程
数据往往决定了 AI 系统真实表现的上限,因此懂一点数据工程非常加分:
- ETL
- Airflow
- Spark
- Kafka
- Databricks
7. 其他语言与工程栈
除了 Python,以下能力也经常出现在岗位要求中:
- TypeScript:全栈 AI 产品开发高频出现
- SQL:数据分析与业务接入必备
- Go / Java:高并发后端场景常见
四、从后端工程师转型 AI 工程师:你其实已经有 70% 的优势
这份路线图里一个很重要的判断是:后端工程师 / 软件工程师,是转型 AI 工程师的最佳起点之一。
因为你原本就掌握了很多 AI 落地最稀缺的能力:
- API 设计
- Docker
- CI/CD
- 数据库
- 云部署
- 生产监控
- 微服务治理
这些恰恰是很多纯研究背景候选人最薄弱的部分。
你真正需要补的“Delta”主要只有四项:
- LLM API 调用 + Prompt Engineering
- RAG 管道
- Agent 模式
- 评估框架(尤其是 LLM-as-Judge)
一个 2-3 个月的高效转型路径
- 第 1 周:掌握 LLM API、结构化输出、Prompt 基础
- 第 2-3 周:搭建第一个 RAG 项目(推荐 FastAPI + pgvector)
- 第 4 周:补上评估体系,构建 Golden Dataset
- 第 5-6 周:开发一个 LangGraph Agent 系统
- 第 7-8 周:部署上云 + 监控 + CI/CD
- 持续补足:PyTorch 基础与轻量 Fine-tuning
这种转型路径的最大优势在于:你不是从零开始学 AI,而是在已有工程能力上加装 AI 能力层。企业真正稀缺的,也不是只会聊模型的人,而是能把模型变成业务系统的人。
五、典型 AI 工程技术栈(2026 年版)
如果把当前主流 AI 工程岗位的要求做一次汇总,大致会收敛到下面这套技术栈:
- 前端:React / Next.js
- 后端:FastAPI
- AI 编排:LangChain / LangGraph / PydanticAI
- 模型层:OpenAI、Anthropic、Groq、本地模型
- 向量数据库:Pinecone / Weaviate / Qdrant / pgvector
- 基础设施:Docker + Kubernetes + 云平台
- 监控:OpenTelemetry + Grafana
- 评估:Evidently、LLM Judge、自建 Eval Pipeline
技能优先级建议
必备:
- Python
- Prompt Engineering
- RAG
- Docker
- 云平台基础
高价值:
- LangGraph
- FastAPI
- TypeScript
- Kubernetes
- PyTorch
差异化能力:
- Agent 框架
- 多 Agent 系统
- Fine-tuning
- 评估系统设计
六、结语:行动比完美计划更重要
这份路线图最大的价值,在于它足够务实。它不是要你成为论文型研究员,而是帮助你成为一个能把 AI 转化为业务价值的工程师。
专注在真正有复利的方向上:
- RAG
- Agent
- Evaluation
- Production
只要把这几个关键能力打穿,你就已经甩开绝大多数停留在“AI 爱好者”阶段的人了。
真正的机会,不在于你知道多少概念,而在于你能不能把一个 AI 想法做成一个上线可用的系统。与其沉迷收藏路线图,不如今天就动手做第一个项目。
原帖作者最后强调:AI 工程不是追逐 hype,而是构建可靠系统,LLM 只是其中一环。最好的学习方式不是收藏一堆课程,而是边学边搭项目,把每个模块都部署成可演示的 Demo,再放到 GitHub 和个人网站上——这其实就是最有说服力的简历。
如果想进一步系统学习,建议直接阅读 Alexey Grigorev 的开源仓库《AI Engineering Field Guide》:
https://github.com/alexeygrigorev/ai-engineering-field-guide
里面包含了完整学习路径、面试题库和转型指南。现在就行动起来:打开 VS Code,调用第一个 OpenAI API,搭建你的第一个 RAG 系统。也许 2-3 个月后你会发现,AI 工程师的门票,其实早就已经握在你手里。