摘要:DeepSeek 今天正式推出 V4 系列模型预览版并同步开源,一次性发布 V4-Pro 和 V4-Flash 两个版本。最大的变化不是某项跑分又刷新了,而是一个产品决策:百万 token 上下文,全线标配,不额外收费。这意味着长上下文从"高端选配"变成了基础能力。
![]()
DeepSeek 今天正式推出了 V4 系列模型预览版,并同步开源。
这次不是小版本迭代,而是一次产品线重构:两个型号同时上线,技术架构做了底层升级,API 接口格式也做了重大调整。
但如果只能记住一件事,那就是这个:
百万 token 上下文,从今天开始,是 DeepSeek 全线服务的标配。不分版本,不分价位,不额外加钱。
这个决定的意义,可能比任何一项跑分提升都大。
两个型号,定位清晰
V4 这次分成了两条产品线。
V4-Pro:旗舰版
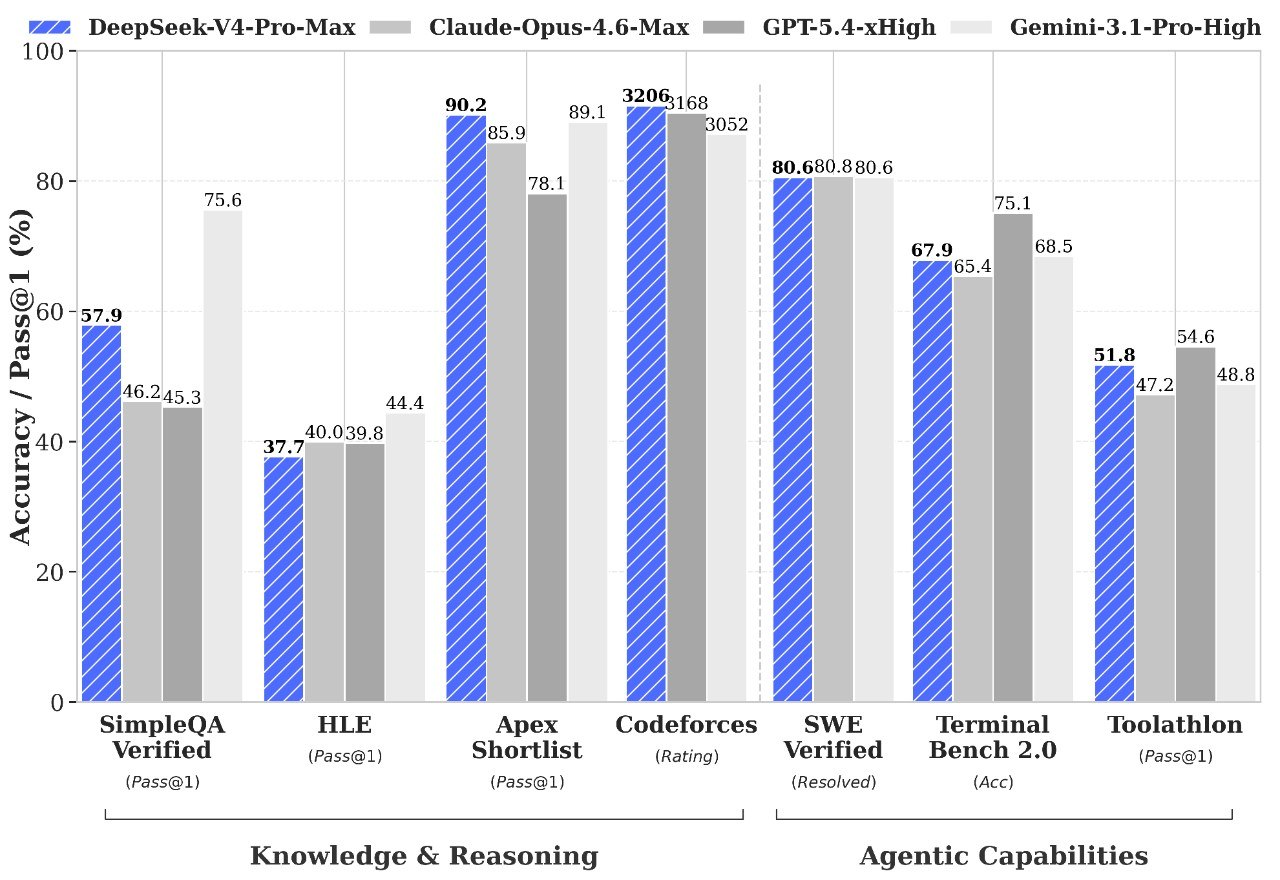
这是 DeepSeek 目前能力最强的模型。根据官方公布的评测数据,V4-Pro 在推理能力上已经追平了当前顶级闭源模型的水准,世界知识维度上仅次于 Gemini-Pro-3.1。
换句话说,在"能不能解决难题"这件事上,V4-Pro 已经站到了第一梯队。
V4-Flash:轻量版
V4-Flash 的定位是"够用且便宜"。推理能力和 Pro 版接近,但在世界知识储备和复杂 Agent 任务的处理上会有一些差距。
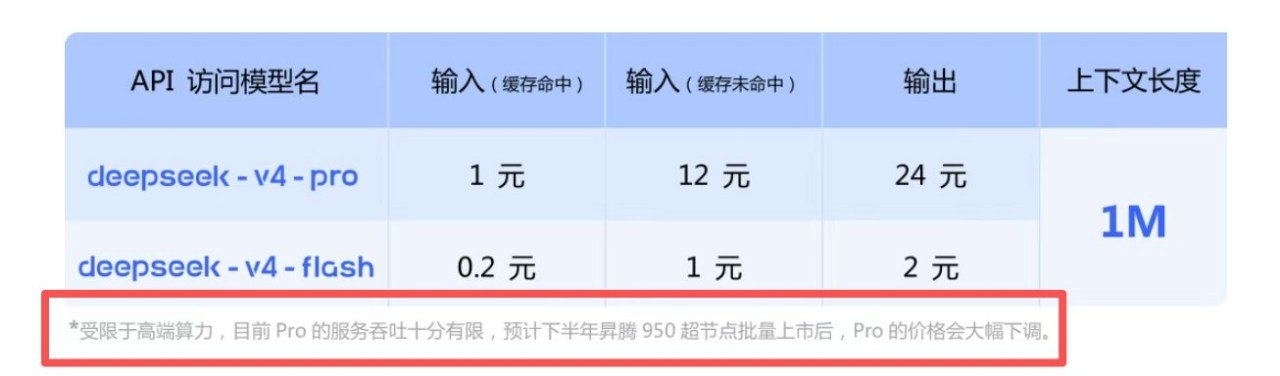
对于大多数日常使用场景,比如文本处理、问答、简单代码生成,Flash 版完全够用,而且 API 价格更友好。
这种"旗舰 + 经济"的双线布局,其实也是在回应市场上一个越来越明确的需求分化:不是所有场景都需要最强模型,但所有场景都需要足够好的模型。
Agentic Coding:一个值得注意的对标方式
这次发布里比较有意思的一个细节,是 DeepSeek 主动把自己的模型拿去和 Anthropic 做了对比。
根据 DeepSeek 内部员工的实际使用反馈,V4-Pro 在 Agentic Coding 场景下的表现,也就是让 AI 自主完成编程任务,整体体验已经超过了 Claude Sonnet 4.5,交付质量接近 Opus 4.6 在非思考模式下的水平。
但 DeepSeek 也坦率地承认,和 Opus 4.6 开启深度思考模式之后的表现相比,V4-Pro 还有差距。
这种"主动承认差距"的表述方式,在国内厂商的发布公告里并不常见。它至少说明两件事:
第一,DeepSeek 对自己模型的定位是清醒的,不是在做营销,而是在做工程判断。
第二,Opus 4.6 的思考模式,已经在事实上成为了行业里 Agentic Coding 能力的隐性天花板。能不能逼近这个天花板,正在变成衡量前沿模型实力的一个新标尺。
百万上下文标配:技术上怎么做到的
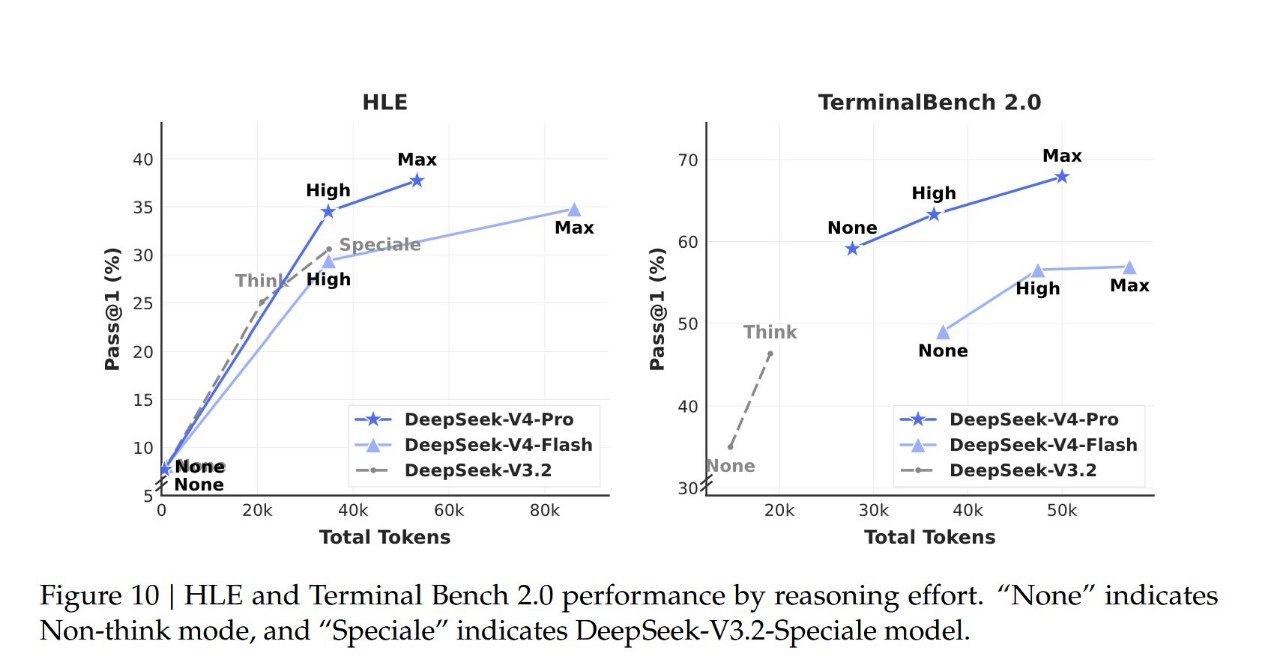
把百万 token 上下文从"能做但很贵"变成"标配且不加价",这不是靠降价就能实现的,背后需要架构层面的改变。
V4 在技术上引入了一种新的注意力机制,核心思路是在 token 层面做压缩。配合 DeepSeek 自研的 DSA(稀疏注意力)技术,百万级上下文所需要的计算量和显存占用都大幅下降。
这意味着什么?
对开发者来说,最直接的变化是:你可以把一整个代码仓库、一套完整的技术文档、甚至一个项目的全部上下文,一次性丢进模型里处理,不用再费心做切分、做摘要、做分段检索。
长上下文能力从"高端选配"变成"基础设施",这对 Agent 工作流、代码审查、文档分析这类场景的影响会非常大。
开发者迁移:几个实用信息
V4 在 API 层面也做了不少调整,开发者需要注意几件事。
Agent 工具适配
V4 专门针对 Claude Code、OpenClaw 等主流 Agent 工具做了适配优化。如果你正在用这些工具,切换到 V4 的成本会比较低。
双格式兼容
V4 的 API 同时支持 OpenAI 和 Anthropic 两种接口格式。切换只需要改 model 参数,不需要重写调用逻辑。
这个设计很实用。现在很多开发者的工具链里同时依赖多家模型,接口格式兼容能省掉大量适配工作。
旧接口迁移时间表
旧的 deepseek-chat 和 deepseek-reasoner 接口名还能继续使用三个月,7 月 24 日之后将停止服务。
如果你的项目里还在用这两个旧接口名,现在就可以开始迁移了,不用等到最后一刻。
这次发布真正重要的是什么
如果把 V4 放到更大的背景里看,这次发布真正值得关注的,不是某一项能力又提升了多少。
而是三件事。
第一,长上下文从竞争优势变成了基础能力
当百万 token 上下文成为全线标配,它就不再是一个"卖点",而是一个"底线"。这会倒逼其他模型厂商跟进,也会改变开发者构建应用的方式。
以前你设计一个 AI 应用,第一步往往是"怎么把上下文压缩到模型能处理的范围内"。现在这个约束正在消失。
第二,Agentic Coding 正在成为模型能力的核心战场
DeepSeek 这次主动拿 Agentic Coding 来对标 Anthropic,说明这个方向已经不是"未来趋势",而是"当下竞争焦点"。
谁的模型能更好地自主完成编程任务,谁就能在开发者生态里占据更有利的位置。
第三,中国模型公司的产品成熟度在快速提升
从双线产品布局、到主动承认差距、到 API 格式兼容、到给出明确的迁移时间表,这些都不是技术问题,而是产品运营和开发者生态建设的问题。
V4 这次发布的整体完成度,已经和国际一线厂商的发布节奏非常接近了。
写在最后
DeepSeek V4 的发布,标志着国内前沿模型竞争进入了一个新阶段。
不再只是比谁的参数大、谁的跑分高,而是开始比:
- 谁的产品线更清晰
- 谁的开发者体验更好
- 谁能把前沿能力真正变成可用的基础设施
- 谁对自己的能力边界更诚实
从这个角度看,V4 不只是 DeepSeek 的一次版本升级。
它更像是中国大模型行业从"追赶期"进入"产品化竞争期"的一个标志性节点。
参考资料:
- DeepSeek 官方发布公告,2026-04-24
- DeepSeek V4 系列模型技术文档
- 行业公开评测与开发者社区反馈