2026年3月25日,一个看似低调的基准测试悄然上线,却在AI圈掀起轩然大波。GPT-5仅得0.26%、Claude 0.25%、Grok直接0%,而旧金山街头随机找来的普通人类测试者,却拿到了100%满分。这不是炒作,而是ARC Prize基金会推出的ARC-AGI-3基准测试——史上首个真正交互式的代理智能基准。
它直指当前前沿大模型的核心痛点:在完全陌生的环境中,没有任何指令、规则或目标提示的情况下,AI能否像人类一样探索、推理、适应并高效完成任务?
本文将全面介绍ARC-AGI-3的来龙去脉、设计理念、评估机制、当前表现、挑战与未来影响。作为一篇深度博客,我会结合官方技术报告、arXiv论文、Kaggle竞赛数据和Chollet等创始人的理念,为你抽丝剥茧地剖析这个"AGI残差差距"的测量工具。

一、从ARC-AGI-1到ARC-AGI-3:Chollet的"智力测量革命"
要理解ARC-AGI-3,必须先回溯它的起源。2019年,Google前AI研究员François Chollet在《On the Measure of Intelligence》一文中痛批当时的主流基准(如ImageNet、GLUE):“它们奖励的是记忆海量数据,而不是真正的智能。”
他提出ARC-AGI(Abstraction and Reasoning Corpus for Artificial General Intelligence),核心理念是流体智能(fluid intelligence):在极少样本下,快速抽象规则、泛化到新任务的能力。
ARC-AGI-1:静态网格谜题
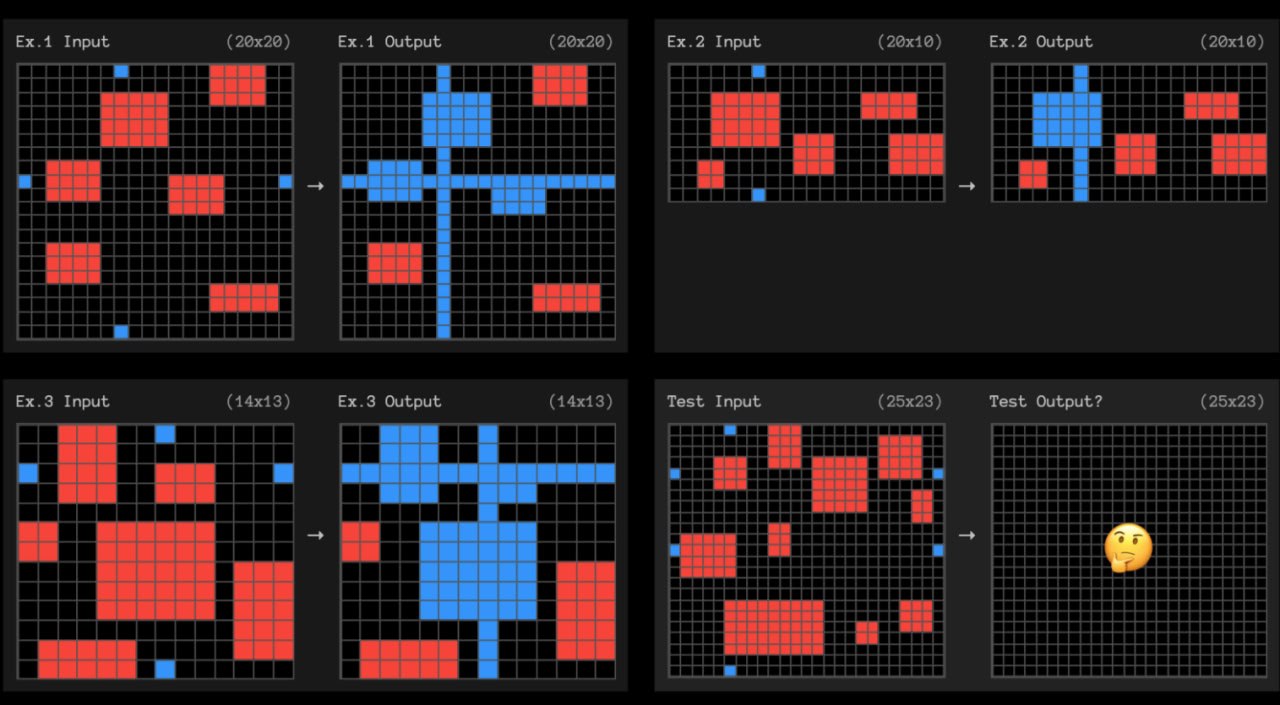
给AI几对输入-输出彩色网格(3x3到30x30),让它推断隐含规则并生成新网格。任务基于人类"核心知识先验"(Core Knowledge Priors),如物体性(objectness)、几何、物理、直观因果等,无需语言或文化知识。人类轻松100%,早期AI接近0%。
它成功预测了2024-2025年推理模型的突破:o1、Claude 3.5等在ARC-AGI-1/2上从个位数飙升到80%以上。
ARC-AGI-2:更复杂的多步推理
2025年的ARC-AGI-2进一步升级:更多关卡、更复杂多步推理。但本质仍是被动的——AI一次性看到所有示例,无需实时交互。
ARC-AGI-3:主动代理智能的跃迁
ARC Prize基金会,2024-2025年已投入数百万美元奖金,吸引全球上千团队。Kaggle竞赛中,顶级方案开始使用测试时训练(test-time training)和链式思考,但仍依赖大量并行采样。
ARC-AGI-3的推出,标志着从"被动流体智能"向主动代理智能的跃迁。2026年3月25日正式发布,隶属ARC Prize 2026(总奖金超200万美元)。它不再是静态图片,而是数百个原创回合制环境、数千个游戏式关卡,全部由专业人类游戏设计师手工打造。
为什么叫"交互式"?
AI代理必须实时探索:每回合接收64x64彩色网格帧(16色),选择动作(离散动作空间,如选中坐标、Undo等),环境即时反馈新帧。无教程、无提示、无目标描述。代理需自行摸索"这是什么游戏?赢的条件是什么?如何高效通关?"。技术报告明确:随机策略胜率<1/万,非平凡关卡几乎不可能靠蛮力。
二、ARC-AGI-3的核心设计:四大代理智能支柱 + 效率评分
ARC-AGI-3的创新在于四大核心功能组件(官方技术报告定义):
1. 探索(Exploration)
信息不会被动给出,必须主动互动获取。AI需像人类婴儿一样"试错",高效采样环境。
2. 世界建模(Modeling)
从原始观察构建可泛化的内部模型,预测未来状态。支持长时序规划和稀疏反馈下的信念修正。
3. 目标推理(Goal-setting)
无显式指令,靠环境线索和内在驱动力自主推断"理想终态"。
4. 规划与执行(Planning and Execution)
从当前状态规划动作序列,并根据反馈灵活纠偏。
评分机制:相对人类动作效率(RHAE)
评分机制是最大亮点:不是"是否通关",而是相对人类动作效率(Relative Human Action Efficiency, RHAE)。每关先由10名普通人类(非专家)测试,取第二好人类首次通关动作数h作为基准。AI动作数a的单关得分:S = min(1, (h/a)^2),上限100%。
环境得分是加权平均(权重随关卡递增),总分是环境均值。100%意味着AI在每个游戏中都匹配甚至超越人类效率。这惩罚了"刷动作"的低效策略,真正考量智能。
三、当前表现:人类 vs AI的"鸿沟"数据
上线仅一周,成绩已足够震撼。
人类:100%满分
普通测试者在浏览器玩几分钟就能通关,效率基准由真实人类动作确立。
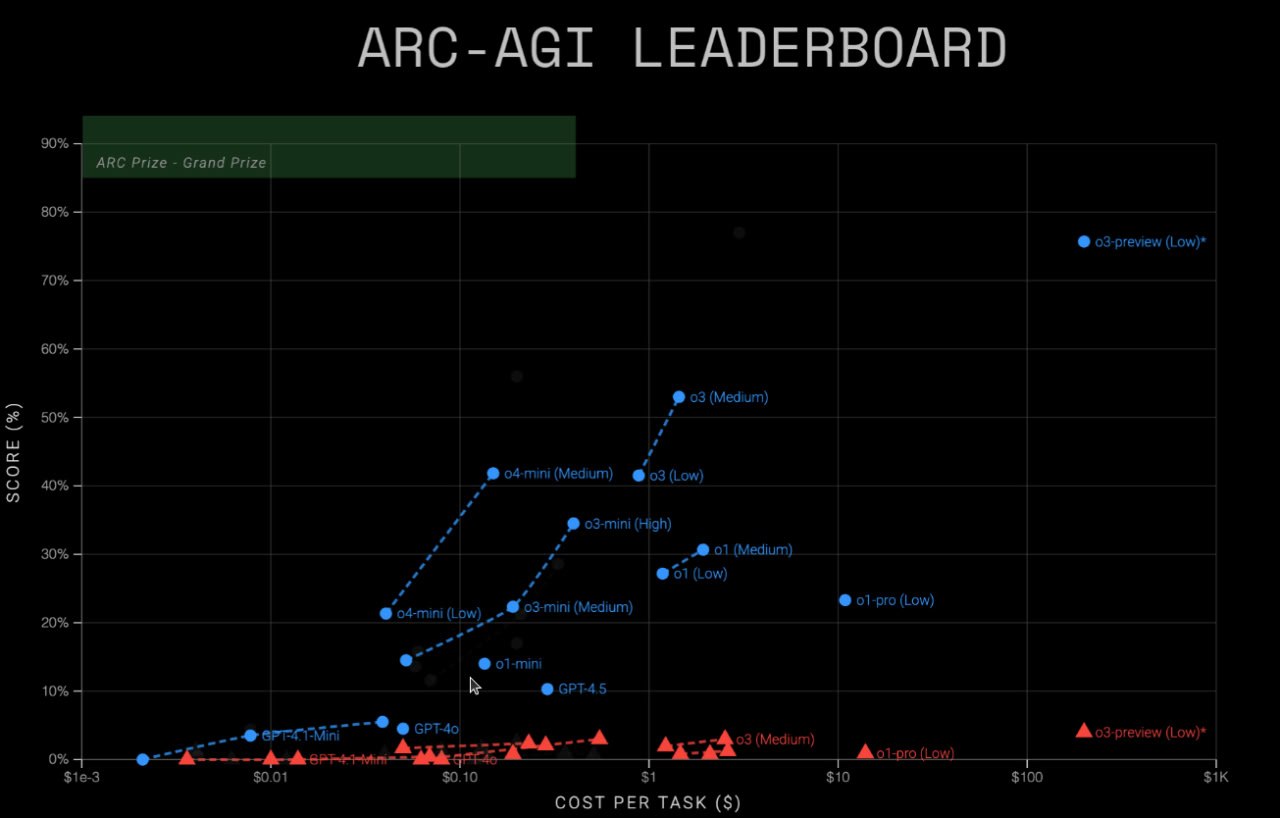
前沿大模型(官方/社区评测):
- GPT-5:0.26%
- Claude(Opus 4.6等):0.25%
- Grok 4.20:0%
- Gemini 3.1 Pro:0.37%(预览)
- OpenAI o3(高算力测试时缩放):最高1.69%(5000并行采样)
- Claude 3.5 Sonnet:0.95%
- Gemini 2.0 Flash:0.52%
Kaggle ARC Prize 2026-ARC-AGI-3竞赛(50%测试数据榜):首位Sergei Fironov 0.50%,前五均<0.31%。验证榜(私有三游戏):开源代理最高StochasticGoose 12.58%(255k动作,2游戏18关),但仍远低于人类。
为什么AI"翻车"?
技术报告指出:当前LLM擅长插值(已见模式),却在外推+探索上瓶颈。它们需要显式指令、大量采样才能勉强推理,一旦进入"未知未知"(unknown unknowns),就陷入随机游走或死循环。无指令环境让prompt engineering失效,交互反馈又要求实时世界模型构建——这正是Transformer架构的结构性弱点。

四、为什么ARC-AGI-3如此重要?
Chollet反复强调:主流基准已被"饱和"。SOTA模型在MMLU、GPQA上逼近人类,却在ARC系列上暴露本质——它们是超级模式匹配器,而非自主学习者。ARC-AGI-3直接测试"代理范式":从指令跟随者(LLM)到自主探索者(AGI)的跨越。
现实意义巨大:
-
AGI路径指引:它量化"残差差距",推动混合架构(神经+符号)、强化学习、测试时训练、记忆增强等方向。
-
产业影响:机器人、自主Agent、游戏AI、科学发现都依赖代理智能。ARC-AGI-3低分说明:当前"AI Agent"多为"脚本化工具链",真自主性仍遥远。
-
伦理与安全:只有当AI能在无指导环境中高效学习,我们才需认真讨论对齐、控制问题。
-
开源社区活力:要求全开源+计算限制,鼓励集体智慧。GitHub harness已上线,开发者可立即测试代理。
五、如何参与?竞赛、工具与社区
ARC Prize 2026-ARC-AGI-3 Kaggle竞赛已启动:
- 时间线:6月30日Milestone #1、9月30日#2、10月26日截止
- 奖金:850K美元(ARC-AGI-3轨道),其中700K大奖给首支100%代理(未达则滚入下年)。Top Score 75K + Milestone 75K
- 要求:全开源、无网、遵守算力限。提交代理在私有集评测
- 入门:浏览arcprize.org/competitions/2026,下载工具包,玩公开游戏ls20、ar25等练手
社区已有"StochasticGoose""Blind Squirrel"等探索型方案分享。未来可能融合LLM规划 + RL探索 + 符号世界模型。
六、展望:ARC-AGI-3会如何塑造下一代AI?
短期内,ARC-AGI-3将加速"代理革命":2026年底前,预计开源方案突破10-20%。长期看,它可能像ImageNet之于视觉一样,成为代理智能的"北极星"。
Chollet在发布会上与Sam Altman的炉边谈(YC HQ直播)已点明:“衡量智能的正确方式,不是参数量或基准饱和度,而是人类级学习效率。”
当然,批评者会说"又一个基准会被攻破"。但ARC Prize的设计哲学是持续进化:私有集防过拟合,新环境保持新鲜度。就像人类智力测试永远有新题,ARC-AGI系列也将伴随AGI一同成长。
结语:人类直觉 vs AI"经验主义"的分水岭
ARC-AGI-3不是在"难为"AI,而是在提醒我们:真正的智能,是在完全陌生的世界里,靠探索与适应活下去的能力。人类天生具备,AI仍在襁褓。0.26% vs 100%,不是耻辱,而是机会——它为开发者指明了方向,为投资者划清了边界,为全人类点亮了AGI的路标。
如果你是开发者,马上打开浏览器玩一局ls20,感受那份"人类本能"的美妙;如果你是研究者,加入Kaggle,贡献你的探索代理;如果你只是好奇,关注arcprize.org——历史正在书写。
未来已来,但智能的真正黎明,或许就在下一个100%被攻克的时刻。
参考文献
- Chollet, F. (2019). On the Measure of Intelligence. arXiv:1911.01547
- ARC Prize Foundation. (2026). ARC-AGI-3 Technical Report. docs.arcprize.org
- ARC Prize 2026 Competition. arcprize.org/competitions/2026
- Kaggle ARC-AGI-3 Leaderboard. kaggle.com/competitions/arc-prize-2026
- GitHub: arcprize/arc-agi-3-benchmarking
发布日期:2026年3月31日
发布机构:中国高技术产业发展促进会新质生产力工作委员会