在人工智能爆发的今天,一场硬件革命正在悄然发生。从 ChatGPT 的实时对话,到手机上的 AI 图像生成,再到数据中心的万亿参数大模型,背后都离不开专用计算硬件的支撑。2026 年 3 月,AI 教育者 Avi Chawla 在 X(原 Twitter)上发布了一条爆款帖子,用一张视觉图表直观对比了 CPU、GPU、TPU、NPU 和 LPU 五种架构,强调它们在"灵活性、并行性和内存访问"上的核心权衡。这篇文章正是基于该帖子的深度扩展,我们将用通俗却不失技术深度的语言,带你拆解每一种芯片的内部逻辑、设计哲学、优缺点,以及真实应用场景。
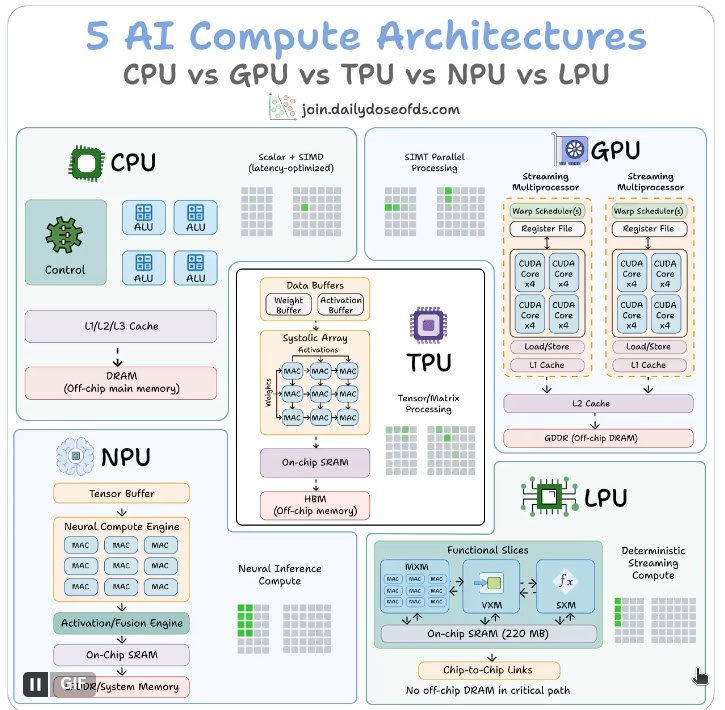
为什么 AI 需要专用硬件?传统 CPU 擅长"思考",却不擅长"重复计算"。神经网络的核心是海量矩阵乘法(matrix multiplication)和乘累加(MAC)操作——一次前向推理可能涉及数十亿次浮点运算。通用处理器在这种"并行、规则、可预测"的 workload 上效率低下,于是 GPU、TPU 等加速器应运而生。它们牺牲部分通用性,换来极致的吞吐量和能效比。
1. CPU:通用计算的"万金油",灵活性之王
CPU(Central Processing Unit,中央处理器)是计算机的大脑,设计初衷是处理复杂逻辑、分支判断和系统任务。它通常只有几个到几十个强大核心,每个核心配备深层缓存(L1/L2/L3 Cache)和复杂的控制单元,支持乱序执行、分支预测等高级特性。
架构特点:
- 灵活性极高:能运行操作系统、数据库、Web 服务,几乎无所不能。
- 并行性弱:核心数量少,SIMD(单指令多数据)宽度有限(AVX-512 也只有 512 位)。
- 内存访问:依赖多级缓存 + DRAM,缓存命中率高时速度快,但 AI 任务中频繁的矩阵数据搬运容易引发缓存缺失(cache miss)。
在 AI 场景中,CPU 适合数据预处理、模型部署前的原型验证、小规模推理(如边缘设备的轻量任务)。但训练一个 70B 参数的 Llama 模型?CPU 可能需要几天甚至更久,而 GPU 只要几小时。功率效率也较低,典型 TDP 在 100-300W 左右。
真实案例:Intel Core Ultra 或 AMD Ryzen 系列的集成 NPU 其实是 CPU+ 专用加速器的混合体,CPU 部分负责 orchestration(编排)。
2. GPU:并行计算的"大力士",AI 训练的绝对主力
GPU(Graphics Processing Unit,图形处理器)原本为游戏渲染而生,却意外成为 AI 的"黄金搭档"。NVIDIA 的 CUDA 生态更是让它一骑绝尘。
架构特点:
- 并行性爆炸:数千甚至上万个小型核心(CUDA Core / Tensor Core),采用 SIMT(单指令多线程)模型,所有线程执行相同指令但处理不同数据。
- 灵活性中等:支持图形、科学计算、AI 训练/推理,甚至通用 GPGPU 计算。
- 内存访问:高带宽内存(HBM)+ 大容量 GDDR,配合 Tensor Core 加速 FP16/INT8 矩阵运算。
GPU 在训练阶段无敌:Transformer 的 attention 计算、卷积层都能完美映射到并行核心上。H100 等旗舰卡单卡可达数千 TFLOPS。但缺点是功耗高(700W+)、调度开销大(硬件运行时调度线程),且对非矩阵任务(如复杂控制流)效率不高。
实际应用:几乎所有大模型训练(OpenAI、Meta)都依赖 GPU 集群。推理时,通过 vLLM、TensorRT 等框架也能实现高吞吐。但在手机或 IoT 上,GPU 功耗太高,无法"常驻"。
3. TPU:Google 的"矩阵工厂",编译器驱动的 ASIC
TPU(Tensor Processing Unit,张量处理器)是 Google 为 TensorFlow 量身定制的 ASIC(专用集成电路),从 v1(2016 年)到现在的 Ironwood,已迭代多代。
架构特点:
- 核心是 Systolic Array(脉动阵列):一个 128×128 或更大的 MAC 网格。数据像流水线一样"流动"——权重从一边输入,激活值从另一边输入,部分和在阵列内累加,无需反复访问内存。
- 并行性极高:专为矩阵乘法优化,吞吐量远超同功耗 GPU。
- 内存访问:编译器静态调度所有数据移动,执行完全确定性(deterministic),减少运行时开销。
- 灵活性低:强绑定 TensorFlow/JAX 生态,非矩阵任务几乎无法发挥优势。
TPU 特别适合大规模云训练和批量推理。Google 声称最新 TPU v6e 在某些 LLM 训练任务上,性价比是 H100 的 4 倍以上。缺点是只能在 Google Cloud 使用,生态封闭。
技术亮点:脉动阵列像"工厂流水线",数据一波波流过计算单元,中间结果直接传递,避免 DRAM 瓶颈。这正是 TPU 能效比高的关键。
4. NPU:边缘设备的"低功耗大脑",手机 AI 的标配
NPU(Neural Processing Unit,神经处理单元)是近两年最火的词,尤其在 PC 和手机领域。Apple Neural Engine、Qualcomm Hexagon、Intel NPU 都属于这一类。

架构特点:
- 专为推理优化:大量 MAC 阵列 + 大容量 on-chip SRAM,减少片外内存访问。
- 并行性中等:针对神经网络的 conv、attention 等算子设计专用 pipeline。
- 内存访问:使用低功耗系统内存 + SRAM,目标是单-digit watt(几瓦)功耗。
- 灵活性低:高度专用,但支持 ONNX、CoreML 等框架。
NPU 的使命是"端侧 AI"——人脸解锁、实时翻译、照片美化、语音助手,全都在设备本地完成,无需云端,保护隐私且延迟极低。Apple M 系列 Neural Engine 最高可达 38 TOPS,Qualcomm Snapdragon X Elite 的 Hexagon NPU 更是 45 TOPS 级。
实际场景:iPhone 的 Live Text、Pixel 手机的 Magic Editor、Windows Copilot+ PC 的本地 AI 功能,都靠 NPU 驱动。未来,NPU 将成为"AI PC"的标配,93% 的新 PC 预计都会集成它。
5. LPU:Groq 的"确定性推理引擎",LLM 时代的黑马
LPU(Language Processing Unit,语言处理单元)是 Groq 公司(注意不是 xAI 的 Grok)推出的最新架构,专为大语言模型(LLM)推理而生,被称为"推理速度最快的芯片"。
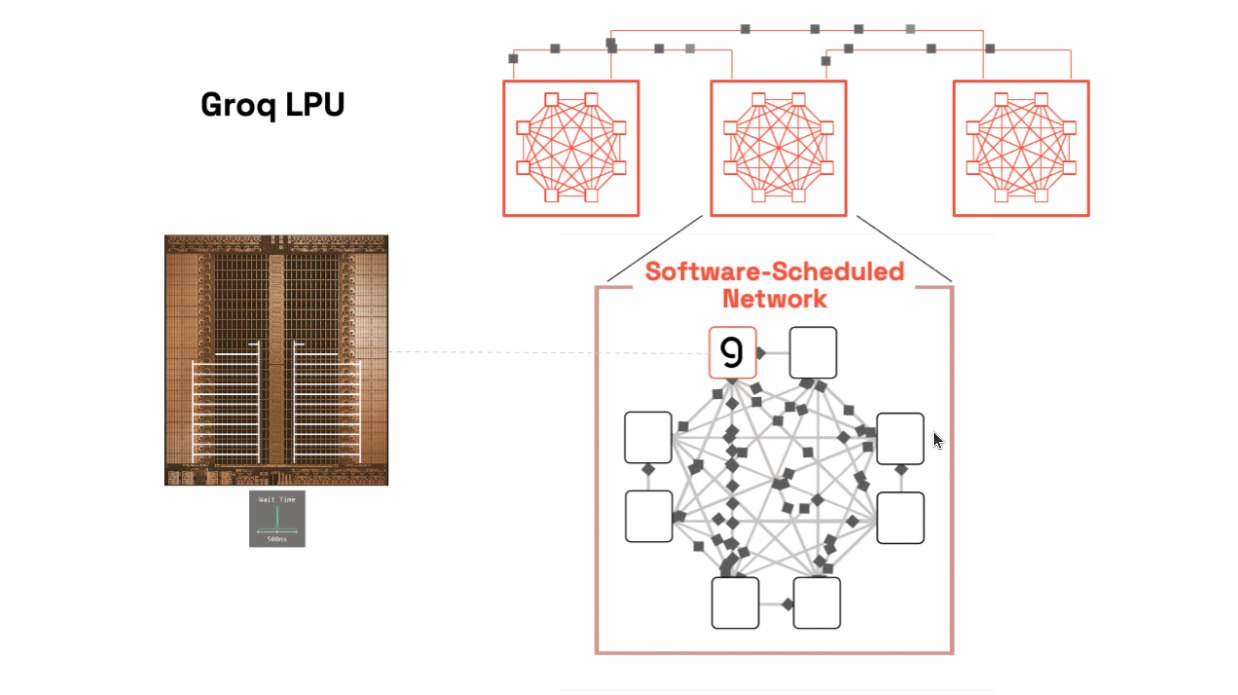
架构革命:
- 彻底消除片外内存瓶颈:所有权重存储在片上 SRAM(数百 MB),不再依赖 HBM/DRAM 的高延迟访问。
- 完全确定性执行:编译器(而非硬件)静态调度每一周期的数据流和计算,零缓存缺失、零运行时调度开销。
- 软件定义的"装配线":把 token 生成想象成工厂流水线,每一步数据流动都提前规划。
- 多芯片互联:单芯片内存有限,因此用数百颗 LPU 组网,通过高速 chip-to-chip 链路(C2C)像一个巨型核心一样工作。
性能表现:Groq 宣称 LPU 在 LLM 推理上比 GPU 快数倍、能效高 10 倍以上,适合实时 API(如 GroqCloud)。缺点是生态新、单芯片容量小,必须大规模集群才能跑超大模型。
为什么 LPU 这么"极端"?因为 LLM 推理是高度顺序、token-by-token 的过程,传统 GPU 的动态调度反而成了累赘。LPU 把"不确定性"全部交给编译器,实现了极致确定性和低延迟。
五大架构横向对比(一图胜千言)
| 架构 | 灵活性 | 并行性 | 内存访问方式 | 功耗定位 | 最佳场景 |
|---|---|---|---|---|---|
| CPU | ★★★★★ | ★☆☆☆☆ | 多级缓存+DRAM | 中 | 通用任务、预处理 |
| GPU | ★★★☆☆ | ★★★★★ | HBM 高带宽 | 高 | 训练、大规模并行 |
| TPU | ★★☆☆☆ | ★★★★★ | Systolic 流水线 | 低 | 云端 TensorFlow 训练 |
| NPU | ★★☆☆☆ | ★★★☆☆ | SRAM+低功耗内存 | 极低 | 边缘推理(手机/PC) |
| LPU | ★☆☆☆☆ | ★★★★☆ | 全片上 SRAM | 低 | LLM 实时推理 |
(数据来源于公开对比与 Groq/Google 官方资料)
未来趋势:硬件感知的 AI 栈
这场硬件演进远未结束。2026 年的趋势是"软硬件协同设计":
-
编译器越来越重要:从 XLA、TVM 到 MLIR,编译器负责把模型映射到最优硬件指令。未来,模型训练时就会考虑目标硬件特性(如 Groq 的确定性调度)。
-
异构计算成主流:没有单一芯片能通吃所有任务。未来的 AI 系统会是 CPU(控制)+ GPU(训练)+ NPU(边缘推理)+ LPU(云端推理)的组合,通过统一软件栈(如 OpenXLA)调度。
-
内存墙倒逼创新:HBM 带宽增长已跟不上模型规模。Cerebras 的晶圆级引擎(Wafer Scale Engine)、Groq 的全片上 SRAM,都是试图绕过内存瓶颈的激进方案。
-
端云协同:手机 NPU 跑小模型,云端 LPU/GPU 跑大模型,通过模型压缩(quantization、pruning)和动态卸载(dynamic offloading)实现无缝体验。
结语
从 CPU 的通用灵活,到 GPU 的并行暴力,再到 TPU 的脉动阵列、NPU 的端侧低功耗、LPU 的确定性推理,每一种架构都是对 AI 计算瓶颈的针对性回应。没有"最好"的芯片,只有"最适合"的场景。
对于开发者而言,理解这些硬件差异至关重要:选错硬件,可能意味着数倍的成本或延迟;选对硬件,则能在同等预算下实现指数级性能提升。未来十年,AI 硬件将继续分化与融合,而掌握"硬件感知"的 AI 工程能力,将成为核心竞争力。
AI 计算正从"通用→专用"演进。未来不会是"谁取代谁",而是异构计算(heterogeneous computing):CPU 管控制、GPU/TPU 管训练、NPU 管边缘、LPU 管超低延迟推理。开发者需要"硬件感知"(hardware-aware)的优化技巧——量化、剪枝、编译器调度等。
正如帖子作者所说:"AI 计算已从通用灵活性走向极致专业化。"无论你是开发者、产品经理还是 AI 爱好者,理解这些权衡,才能在 2026 年的硬件浪潮中抢占先机。
参考来源:
- Avi Chawla (@_avichawla) on X, March 2026
- Groq 官方技术白皮书
- Google TPU 架构论文
- NVIDIA CUDA 文档
- Intel/Qualcomm/Apple NPU 技术规格