在人工智能的发展史中,Embedding(向量化)始终是连接人类感知与机器计算的"隐形桥梁"。从早期的 Word2Vec 将单词映射为空间坐标,到 BERT 让机器理解上下文,再到 OpenAI 的 text-embedding-3 实现的大规模语义索引,我们一直在完善文本的数字化表达。
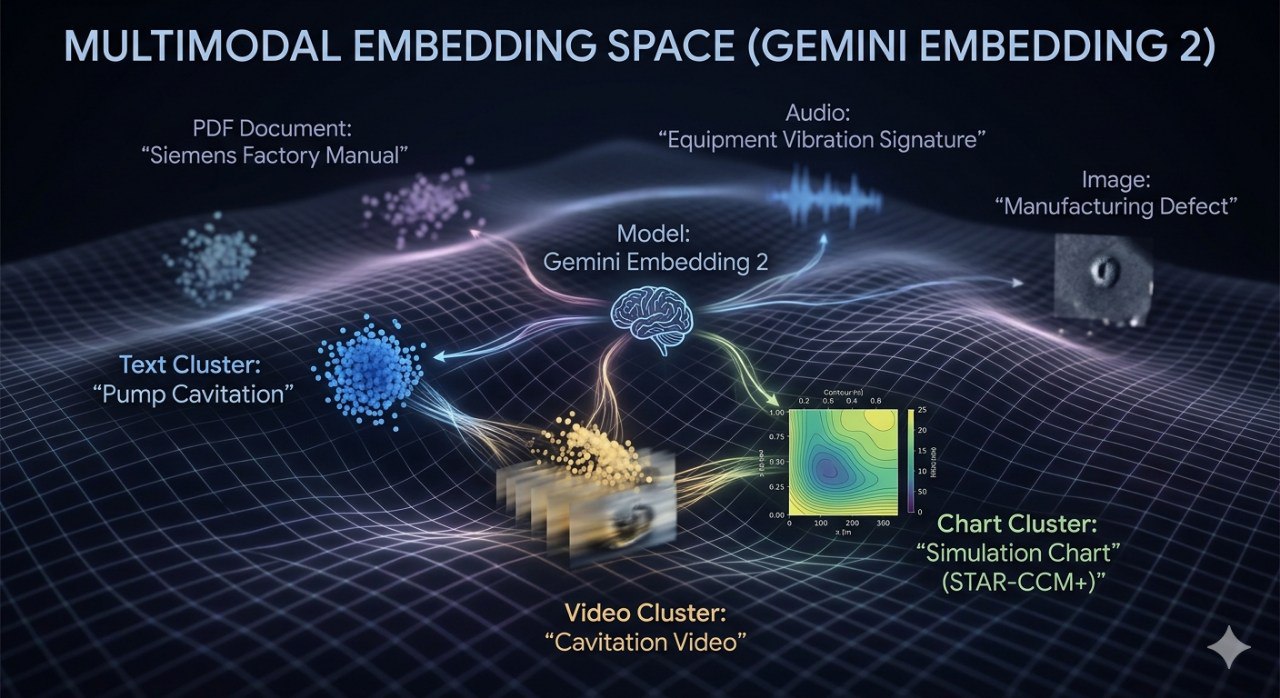
然而,真实的工业场景和物理世界并非由纯文本构成。它是西门子工厂里精密设备的运行视频,是 STAR-CCM+ 仿真出的复杂流体云图,是设备故障时刺耳的摩擦声,更是长达数百页、图文混排的技术手册。
2026年3月,谷歌发布的 Gemini Embedding 2 正式宣告了一个新时代的到来:原生多模态向量化时代。它不再仅仅是文字的搬运工,而是将文字、图像、视频、音频和 PDF 统一映射进同一个数学流形。本文将深度解析这一技术突破及其在工业 AI 领域的颠覆性应用。
一、什么是"原生多模态"?
在 Gemini Embedding 2 之前,业界实现"图文搜索"通常采用双塔架构(Two-Tower Architecture),如经典的 CLIP 模型。其逻辑是训练两个独立的编码器(一个看图,一个识字),然后强行让它们的向量在空间中靠近。
这种方案虽有效,但存在"语义断层":图像编码器看不懂视频的动态逻辑,文本编码器无法理解复杂的 PDF 布局。
Gemini Embedding 2 的突破在于"原生":
它是基于 Gemini 大模型的统一架构训练而成的。这意味着模型在"胚胎阶段"就同时接受了各种模态的训练。在它的隐向量空间(Latent Space)里,一段描述"泵机叶片气蚀现象"的文字,与一段记录该现象的高速摄像视频,以及一张显示压力骤降的仿真图表,在数学上是近邻的。
二、核心技术深度解析
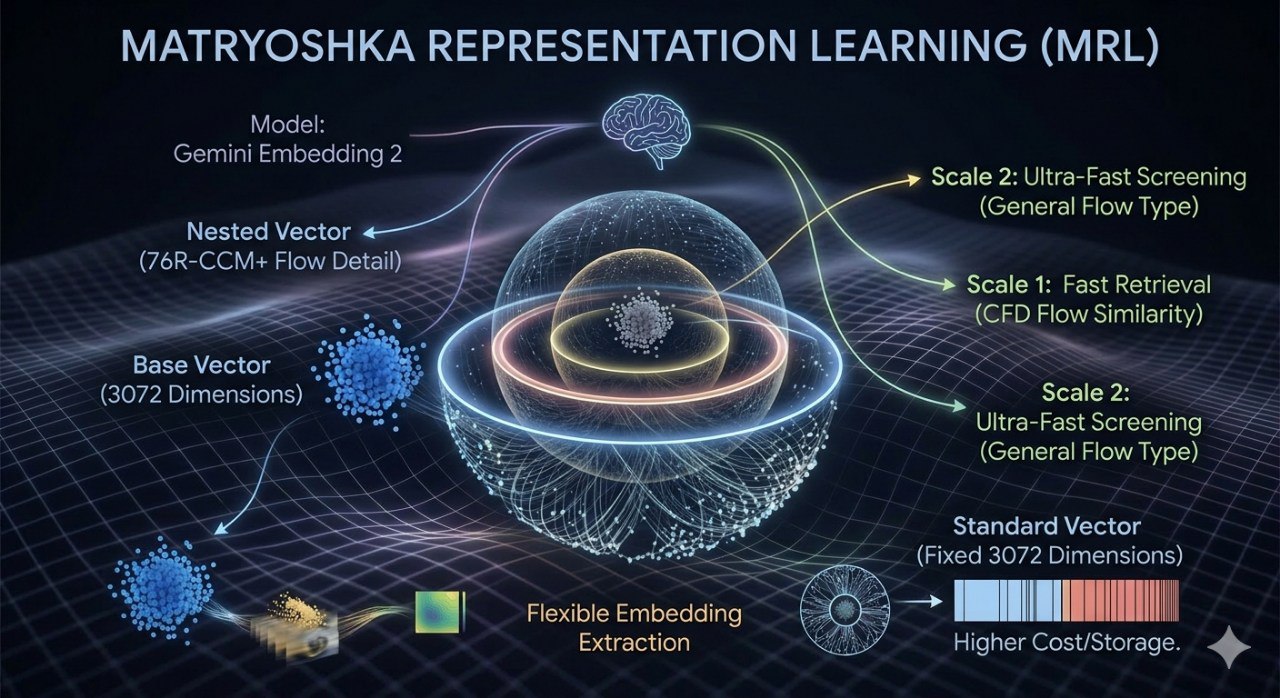
1. 维度的魔法:Matryoshka Representation Learning (MRL)
Gemini Embedding 2 引入了"俄罗斯套娃"表征学习(MRL)。这是一项极具工业落地价值的技术。
在处理数以亿计的工业传感器数据或文档时,存储成本和检索延迟是巨大的挑战。传统的 Embedding 维度是固定的(如 3072 维),如果你想降维,通常需要重新训练模型或牺牲大量精度。
MRL 技术允许模型在一个大向量中"嵌套"小向量:
- 弹性部署:在进行初步的大规模筛选时,你可以只提取前 768 维,牺牲极小的精度换取 4 倍的检索速度。
- 精细比对:在进入重排(Rerank)阶段时,再调用全量的 3072 维进行精准匹配。
2. 视频与动态感知的飞跃
Gemini Embedding 2 支持长达 120 秒 的视频向量化。这不再是简单的"抽帧叠加",而是模型能够理解视频中的时间一致性(Temporal Consistency)。
例如,在分析自动化产线的机械臂动作时,它能区分"顺时针旋转"与"逆时针旋转"的语义差异,这对于工业场景下的行为识别和故障回溯至关重要。
3. 复杂 PDF 的结构化理解
对于工程师而言,最头疼的是非结构化文档。Gemini Embedding 2 能够直接向量化 PDF 的视觉布局。它不仅"读"到了文字,还"看"到了公式的位置、表格的行列关系以及插图的标注。
三、工业 AI 的新质生产力:应用场景展望
作为工业 AI 的从业者,我们最关心的不仅是参数,而是这些技术如何转化成新质生产力。
1. 智能仿真(CFD)的"以图搜图"
在 Simcenter STAR-CCM+ 的应用中,工程师每年会产生海量的仿真结果。
- 痛点:过去想找一个"类似雷诺数下、具有相似旋涡结构的流场案例",只能靠文件名或人工备注。
- Gemini 方案:直接将仿真生成的压力标量图或速度矢量视频向量化。新项目的工程师只需上传一张草图,AI 即可从数据库中秒级检索出历史相似案例及对应的优化参数。
2. 多模态 RAG:构建工厂的"超级大脑"
目前的检索增强生成(RAG)大多局限于文本。有了 Gemini Embedding 2,我们可以构建全模态知识库。
- 场景:现场工人戴着 AR 眼镜询问:“这个联轴器异响正常吗?”
- 流程:系统录制 5 秒音频和视频,通过 Gemini Embedding 2 转化为向量,在向量数据库中检索历史维修记录(包含声音样本、视频演示和 PDF 手册)。
- 输出:AI 结合实时检索到的视频教程,指导工人进行排查。

3. 跨模态数据治理(Data Elements)
在数据要素市场化背景下,如何评估工业数据的价值?
通过统一向量空间,我们可以量化不同模态数据之间的信息冗余度。例如,通过计算视频数据与对应的传感器日志之间的向量距离,我们可以发现哪些视频提供了日志之外的"增量信息",从而实现更高效的数据脱敏、压缩与定价。
四、局限性与挑战
尽管 Gemini Embedding 2 展现了强大的统治力,但在实际部署中仍需保持理性思考:
- 私有化部署难题:作为闭源 API,对于一些涉及核心机密的工业仿真数据,如何在满足数据安全合规的前提下利用 Google 的能力,仍是一个博弈过程(如使用西门子专有的加密网关或混合云架构)。
- 向量漂移:在极高精度的物理场景下(如纳米级制造),多模态向量是否存在"语义模糊"?这需要我们在特定的工业垂域进行微调(Fine-tuning)。
- 计算成本:虽然 MRL 降低了检索成本,但多模态输入的预处理(尤其是 120 秒高清视频)对边缘侧的算力依然提出了挑战。
五、结语:向量即世界
从数学的角度看,世界是高维的;从 AI 的角度看,世界是向量的。
Gemini Embedding 2 的出现,标志着我们终于拥有了一把能够同时度量文字、光影与声浪的"尺子"。对于致力于工业 AI 的我们来说,这不仅仅是一个工具的更新,它是在物理世界与数字孪生(Digital Twin)之间,建立起了一套更加深邃、更加直觉的映射机制。
新质生产力的核心在于全要素生产率的提升。当我们能够把工厂里的每一帧视频、每一页图纸、每一段波形都转化为可搜索、可计算、可推理的向量时,真正的"工业智能化"才真正拉开了序幕。