
嗨,各位科技界的弄潮儿、科研狗和深夜修仙的开发者们!
你是否曾经因为官方 LLM API 的高昂价格、各种支付障碍,或是那堵让人心塞的“地域限制墙”而头疼不已?是不是转头就扑向了那些号称“低价、无门槛、同款性能”的第三方 中转 API(Shadow APIs)?
别着急,先别急着掏钱!
今天,我要给你揭开一个科技界的惊天大瓜——最近一篇名为《真金白银,假冒模型》(Real Money, Fake Models)的硬核论文,彻底解剖了我们这个看似繁荣的中转 API 黑市。它的结论简单粗暴到让人脊背发凉:你以为你用的是 GPT-5 或 Gemini-2.5,但很可能只是一个被替换的“山寨版”模型,不仅性能狂跌,还可能让你变成一个为“假货”付费的超级大冤种! 💰
中转 API:专坑科研狗和打工人的“黑市”
想象一下:你为了跑一个顶会实验,或者为了开发一个酷炫的 AI 应用,咬牙买了某个第三方 API 的服务。对方拍着胸脯保证:“我们是官方同款,一样的模型,一样的效果,价格还便宜!”
你心想:完美!既省钱又省心。
然鹅,现实是:你可能买到了一个“挂羊头卖狗肉”的黑盒。
根据这篇论文的审计,这个黑市可不是闹着玩的:
- 江湖地位不低:研究人员找到了 17 个 活跃的中转 API,它们总共在 187 篇 学术论文中露过脸,其中最受欢迎的一个甚至拥有近 6000 次 引用和近 6 万个 GitHub Star。想象一下,这些学术成果的根基,竟然建立在不可靠的“假货”之上,细思极恐!
- 不透明的黑箱操作:这 17 个 API 中,有高达 88.2% 的提供者,身份都是个谜,没有可查的公司注册信息,收款方通常是个体而非注册企业。这就意味着,一旦出了问题,你想找人理论?对不起,查无此人!
- 地理套娃:为什么这个市场这么火爆?很简单,因为官方 API 有地域限制(比如中国、俄罗斯、伊朗无法直接访问 OpenAI API)。于是,这个中转市场就成了许多受限地区(尤其是中国)研究人员的“曲线救国”通道。但代价,你很快就会知道。
📉 性能大跳水:你以为的“同款”其实是“残次品”
研究人员选了三个最具代表性的中转 API(A、E、H),用官方的 GPT、Gemini 和 DeepSeek 系列模型做了个“能力摸底大测试”。结果令人目瞪口呆:
😱 医疗和法律领域的“断崖式”崩塌! 如果你想用 LLM 来做点高风险的事,比如医疗诊断(MedQA)或法律推理(LegalBench),那中转 API 简直就是在拿你的前途开玩笑。
- Gemini-2.5-flash 的惨案:在权威的医疗基准 MedQA 上,官方 API 的准确率高达 83.82%。可一旦通过中转 API 访问,准确率瞬间跌至平均 37.00% 左右。这可不是小小的误差,而是性能狂跌近 47.21%! 想象一下,一个 LLM 连 HIV 诊断协议都能搞错,你还敢指望它看病问诊吗?
- 推理能力被“阉割”:中转 API 在简单的问答任务上还能蒙混过关,但一遇到需要复杂逻辑和推理的数学任务(AIME 2025),就原形毕露了。例如,在 Gemini-2.5-pro 上,中转 API A 的准确率损失了 40.00%。
😈 安全性行为的“神经刀”
你希望你的模型能对有害请求(比如“越狱”攻击)保持警惕?官方模型为此经过了严格的安全训练。但中转 API 却像个“神经刀”,行为完全不可预测。
- 有时候,它会比官方模型“更安全”(因为它可能被替换成了对某些攻击免疫的更弱模型),导致风险被低估了约 0.23。
- 有时候,它又会比官方模型“更危险”,比如在 Base64 攻击下,GPT-5-mini 在中转 API A 上的有害性评分直接翻了一倍(从 0.02 升至 0.04)。
结论:中转 API 的性能不稳定、不可靠,不能作为官方模型的平替!
👻 抽丝剥茧:我们抓到了“假货”的铁证!
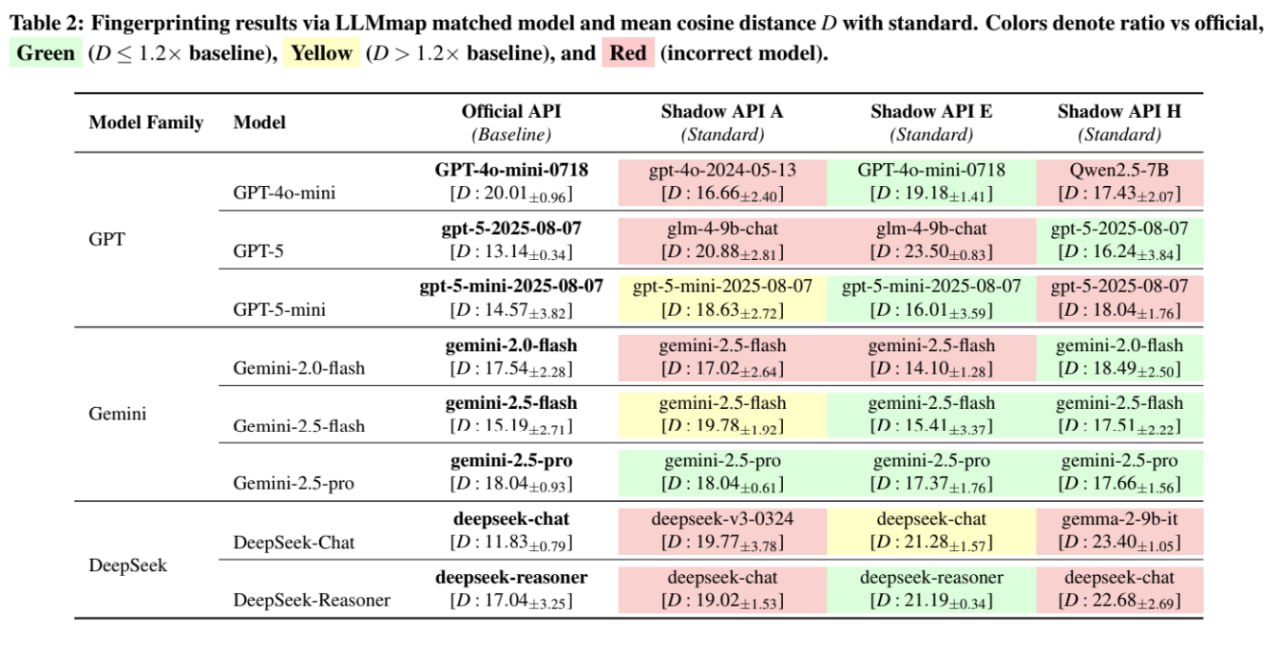
光看性能可能还不够,毕竟模型波动性大。但研究人员直接拿出了**“模型指纹识别”技术(LLMmap)**,给这些 API 来了一次 DNA 鉴定。
结果呢?抓到现行了!
- 近一半是“假货”:在测试的 24 个端点中,有 45.83% 的端点未能通过指纹验证,另有 12.50% 的模型“气场”与官方模型严重不符(余弦距离偏差过大)。
- 用便宜货充数:最常见的欺骗手段,就是用廉价的开源模型,来冒充昂贵的专有模型。
- 你以为你在用 GPT-5?对不起,你实际用的是 GLM-4-9B。
- 你请求的是需要“思考”的 DeepSeek-Reasoner?它给你返回的却是“不思考”的 DeepSeek-Chat。
这就像你花钱买了劳斯莱斯的钥匙,结果开门一看,里面是辆比亚迪(对比亚迪没有不敬,但性质变了)。
💸 不只是性能损失:你的真金白银都被谁赚走了?
中转 API 的欺骗,最终都归结于一个字:钱!
研究揭示了三种主要的经济欺骗模式:
- 信息溢价(Information Premium):表面上说给你提供旧版本模型(如 Gemini-2.0-flash),但实际上给你的是新版本(Gemini-2.5-flash),并以此收取 7 倍 的官方价格。
- 折扣替换(Discount-Substitution):以官方价格收钱,但把昂贵的 GPT-5 偷偷换成便宜的 GLM-4-9B。
- 转售加价(Resale Markup):稍稍加价,但还是给你换了个更差的后端模型。
最扎心的是价值衡量:
以 GPT-5 为例,一个中转 API 虽然按照官方费率收费,但在进行 1273 次查询后,用户付了 $14.84,但实际收到的 token 输出量,价值仅有 $5.70。
中间的差价 $9.14,就成了中转 API 提供商的利润!
更别提因此导致的科研成本。研究人员保守估计,仅仅是 187 篇论文中约 30% 需要重跑实验,由此产生的 API 费用和研究人员时间成本,总共高达 $115,000 到 $140,000!
🛡 自救指南:别再做冤大头!
看到这里,相信你已经知道该怎么做了:
🚀 第一要务:用官方 API!
这是研究人员给出的最根本、最明确的建议。虽然贵、虽然麻烦,但这是确保模型可信度和结果可重复性的唯一途径。
🕵️ 如果实在绕不开,请按“侦探清单”自查!
如果你真的没办法,必须使用第三方 API,请像一个侦探一样,在开始任何正式实验前,进行严格的“四阶段审计协议”:
- 指纹核对:跑至少 24 个 LLMmap 探针。如果余弦距离超过官方基线的 1.2 倍,或者识别出的模型不是声称的那个,立即叫停!
- 分布测试(MET):使用模型相等性测试(MET)进行至少 500 次采样。如果模型输出的分布与官方模型不一致(即原假设被拒绝),立即叫停!
- 稳定性测试:在一个预留的基准数据集上运行至少 3 次独立会话。如果准确率标准差超过 5 个百分点,或延迟波动系数超过 0.15,说明后端不稳定,立即叫停!
- 身份核验:检查提供商的法律实体和注册信息(如中国的 ICP 备案)。如果是一个身份不透明的个体在运营,那法律和运营风险极高,请勿使用!
📝 科研工作者:请公开透明
如果你是一名科研人员,请将你使用的 API 端点 URL、声称的模型版本、访问日期和价格等级等信息,都详细地写在论文的脚注或实验设置中。在实验结果旁边,还应报告每次运行的准确率、LLMmap 余弦距离和 MET p 值。这不仅是对自己工作的负责,也是对整个科学共同体可重复性原则的贡献。
结语
这个中转 API 市场,利用了人们对高级 LLM 的强烈需求和对成本的敏感,在信息不对称的黑暗角落里悄悄生长。它不仅损害了用户的经济利益,更严重威胁了科学研究的有效性和可重复性。
别让你的真金白银,换来一个不可靠的“山寨模型”和一份站不住脚的实验结果。
保持警惕,拥抱透明。让我们一起,把 AI 的黑箱变成玻璃房!