如果把大语言模型(LLM)比作一个拥有博学知识但缺乏社会经验的"天才毕业生",那么现在的AI智能体(Agent)正处于从"只会动嘴"向"实际干活"转型的关键期。
近日,一份来自BenchFlow团队及其合作机构的重磅研究报告《SkillsBench》正式发布。这篇论文不仅构建了目前最系统的AI智能体"技能"评估体系,更用扎实的数据戳破了一个幻觉:即便最顶尖的大模型,目前也无法靠自己总结出真正好用的"工作指南"。
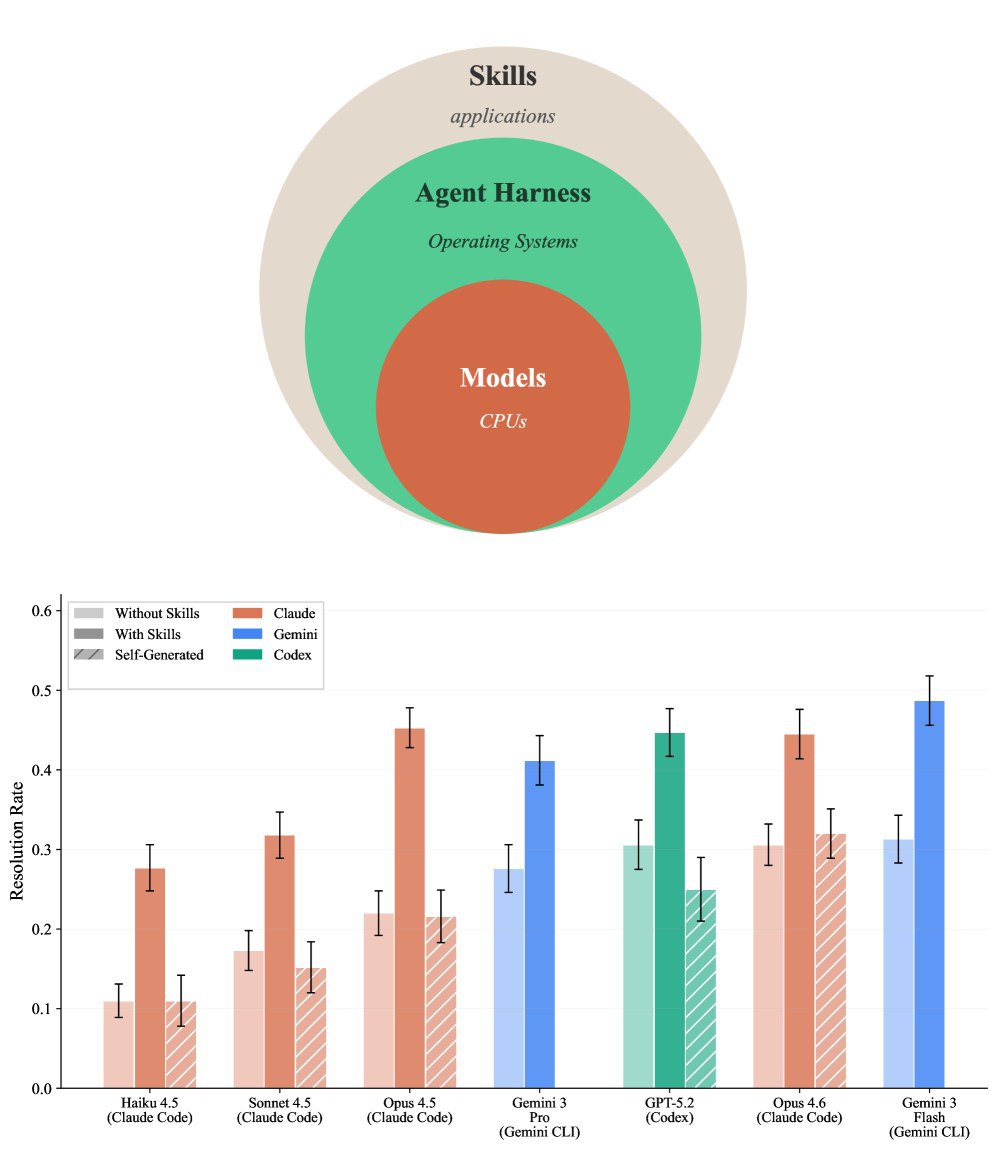
一、当模型变成CPU:什么是"智能体技能"?
在传统的计算机架构中,CPU提供算力,操作系统(OS)负责调度,而应用程序(Apps)则解决具体问题。论文提出了一个极具启发性的架构类比:
- 模型(Models):相当于CPU,提供基础的逻辑推理和通用能力。
- 智能体框架(Agent Harnesses):如Claude Code或Gemini CLI,相当于操作系统,负责环境管理和工具调用。
- 技能(Skills):则相当于应用程序,是专门为解决特定领域问题而打包的"过程性知识"。
所谓"技能",并不是简单的提示词(Prompt),也不是海量的检索增强生成(RAG)数据,而是一套包含指令、代码模板、参考资源和验证逻辑的结构化包。它告诉AI:面对某种特定任务(如分析财报或操作制造业ERP),标准的操作流程(SOP)是什么,有哪些容易踩的坑。
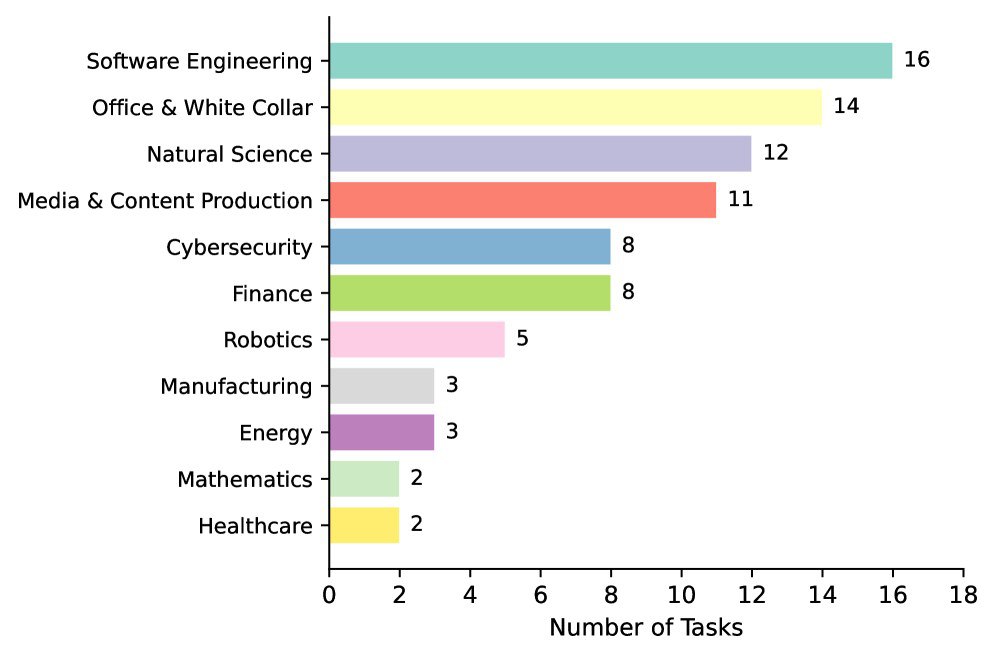
二、SkillsBench:为AI准备的84道"职场大考"
为了验证这些"技能"到底有没有用,研究团队推出了SKILLSBENCH。这是一个涵盖11个领域(从医疗卫生、制造业到网络安全)、包含84个复杂任务的基准测试。
这些任务不再是简单的"写段代码",而是极具挑战性的现实工作。例如:
- 金融领域:通过交叉引用PDF、Excel和CSV来检测发票欺诈。
- 医疗领域:跨医疗系统协调临床实验室数据单位。
- 制造业:根据手册数据回答回流焊机的维护问题。
研究者通过三个对照组进行实验:不提供技能(裸奔)、提供人工精选技能(给说明书)、让AI自创技能(自悟)。
三、核心发现:AI的"自省"能力可能被高估了
通过对7,308条任务轨迹的严密分析,SkillsBench给出了几个令人心惊(甚至对AI有点"无情")的结论:
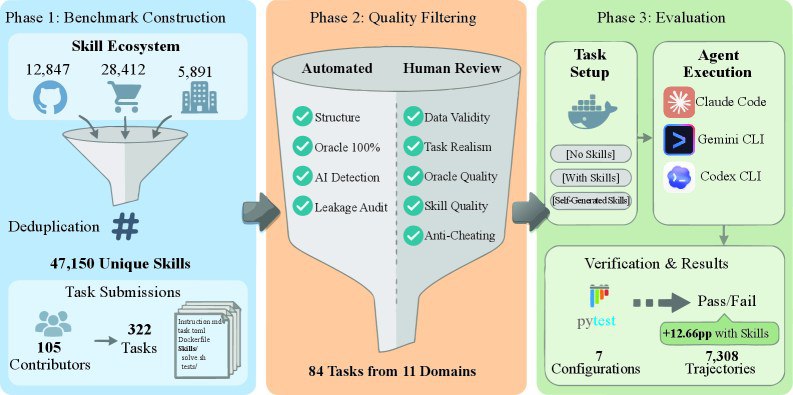
1. 人类经验是"降维打击"
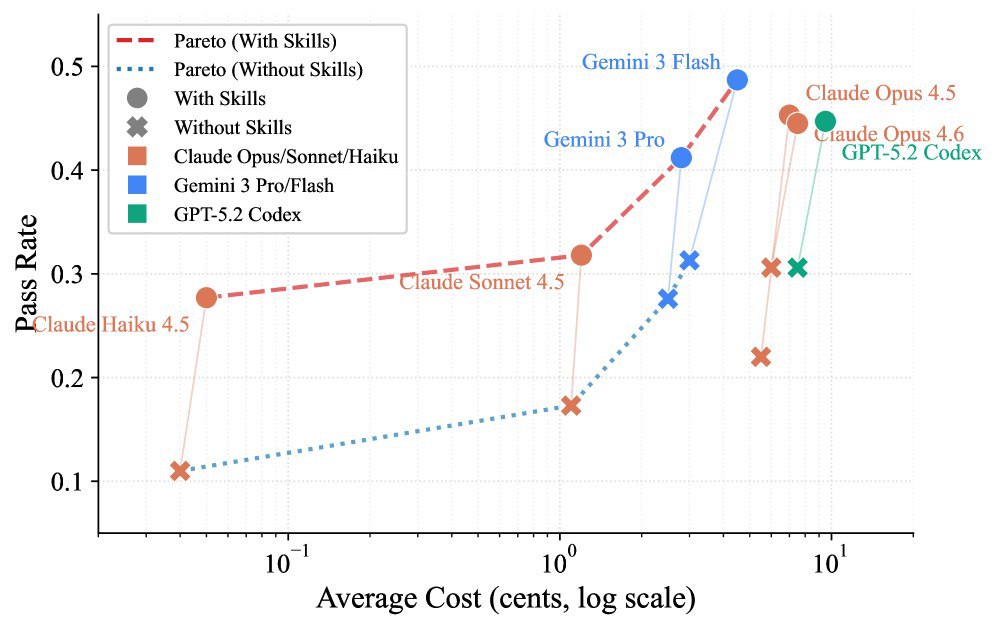
提供人工精选的技能后,智能体的平均任务成功率提升了16.2个百分点。在医疗卫生(+51.9%)和制造业(+41.9%)这两个高度专业化、且预训练数据较少的领域,提升效果最为惊人。这证明了:外挂的专业知识是弥补模型通用能力不足的最佳方案。
2. "自创技能"是一场灾难
这是论文中最具争议也最有趣的发现:当研究者要求大模型(如GPT-5.2或Claude Opus 4.6)在做题前"先给自己写份攻略"时,效果几乎完全消失,甚至出现了负增长(平均下降1.3个百分点)。
模型往往能意识到需要哪些知识,但它们生成的流程要么太笼统(如"请使用Pandas处理数据"这种废话),要么在关键的API细节上出现偏差。这说明:模型可以学习知识,但它们目前还无法可靠地生产出它们自身受益的"程序性经验"。
3. “小模型+技能"可胜过"大模型裸奔”
实验显示,Claude Haiku 4.5(较小模型)在拥有技能辅助后的表现(27.7%),超过了不带技能的最强模型Claude Opus 4.5(22.0%)。这意味着对于企业而言,与其追求极致昂贵的超级模型,不如为轻量级模型配备一套精准的"业务技能包",这在成本和效率上可能更具性价比。
四、避坑指南:给智能体写说明书,千万别太啰嗦
研究团队还通过实验总结出了高质量技能的"设计准则":
- 2-3个模块最合适:并不是给的资料越多越好。当技能包超过4个模块时,性能反而会下降。太多的信息会造成"认知负荷",让AI在推理时分散注意力。
- 拒绝"百科全书":那种详尽到极致、甚至带有一丝沉闷的"综合性文档"表现最差(成功率甚至会下降2.9%)。相反,紧凑(Compact)和详细但侧重流程(Detailed)的技能包表现最好。
- 结构化是王道:必须包含具体的步骤、代码示例和验证检查点。
五、失败分析:AI到底在愁什么?
即便有了技能,AI仍会失败。SkillsBench对5,171次失败进行了"尸检":
- 质量达标难(49.8%):最常见的失败。AI能跑通流程,但最后算出的数值超出了误差范围(比如算错地震波距离)。
- 超时(17.8%):任务太复杂,AI在反复探索中耗尽了额度。
- 执行错误(17.7%):包括根本没产出文件或违反了特定的格式要求。
六、结语:通往成熟智能体之路
SkillsBench的出现标志着AI评估从"智力测试"向"职业技能考核"的跨越。它告诉我们,智能体的未来不在于让它闭门造车地"自省",而在于如何更高效地继承人类积累的程序性经验。
对于开发者和企业来说,这份研究是一个清晰的信号:投资于领域专属的"技能库"建设,其价值远高于盲目追求更大参数的模型。
AI也需要它的"蓝领技能说明书",而这份说明书,目前还得由人类来写。
论文信息:
- 标题:SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
- 作者:BenchFlow团队及合作机构
- 发布时间:2026年2月
- 核心贡献:构建了首个系统性的AI智能体技能评估基准,涵盖11个领域84个复杂任务
对工业智能的启示:
- 制造业等专业领域更需要结构化技能支持
- 企业应优先投资领域知识库而非单纯追求大模型
- 技能设计需要平衡信息密度和可操作性
- AI在工业场景的成功依赖于人类经验的系统化传承