在工业界,2026 年被公认为「数据还债年」。过去十年中,全球制造商在工业 4.0 的旗帜下部署了数以亿计的传感器,但这却制造了一个尴尬的现实:数据总量爆炸,但有效洞察贫瘠。
根据最新的行业数据,工业企业收集的数据中有近 88% 处于闲置状态。更糟糕的是,SCADA(数据采集与监视控制系统)与 MES(制造执行系统)之间的代沟,让数据在车间层就被锁死在了互不往来的「信息孤岛」中。
然而,随着 Industrial DataOps(工业数据操作)市场的爆发——预计 2026 年市场规模将突破 77 亿美元,年复合增长率超过 30%——这场关于数据的「圈地运动」正在演变为一场深度的「架构革命」。
一、孤岛之殇:为什么传统的「集成」失灵了?
要理解 DataOps 为什么爆发,必须先看清传统工业架构的崩塌。
在经典的 ISA-95 模型中,企业数据被严格地划分为层级:底层的 PLC/传感器数据喂给 SCADA,SCADA 汇报给 MES,MES 再汇总到 ERP。这种烟囱式的结构在「稳定生产」时代运作良好,但在「实时优化」时代却成了致命伤。
-
缺乏上下文的「数据流」:一个来自二号机组的温度传感器读数「85.5」本身毫无意义。除非你将其与 MES 中的「工单编号」、ERP 中的「钢材批次」以及环境湿度关联起来。传统的 ETL(抽取、转换、加载)过程由于是批量进行的,往往在数据汇聚到云端时,其宝贵的时间上下文(Temporal Context)已经丢失。
-
脆弱的管道:传统的集成方案大多是「点对点」的硬编码。一旦车间增加了一台新设备或修改了一个 PLC 参数,整个下游的数据看板就会「熄火」。
-
IT 与 OT 的技术断层:操作技术(OT)专家懂工艺但不懂 Python;信息技术(IT)专家懂算法但没见过机床。DataOps 的出现,本质上是为了在两者之间建立一条「高速公路」。
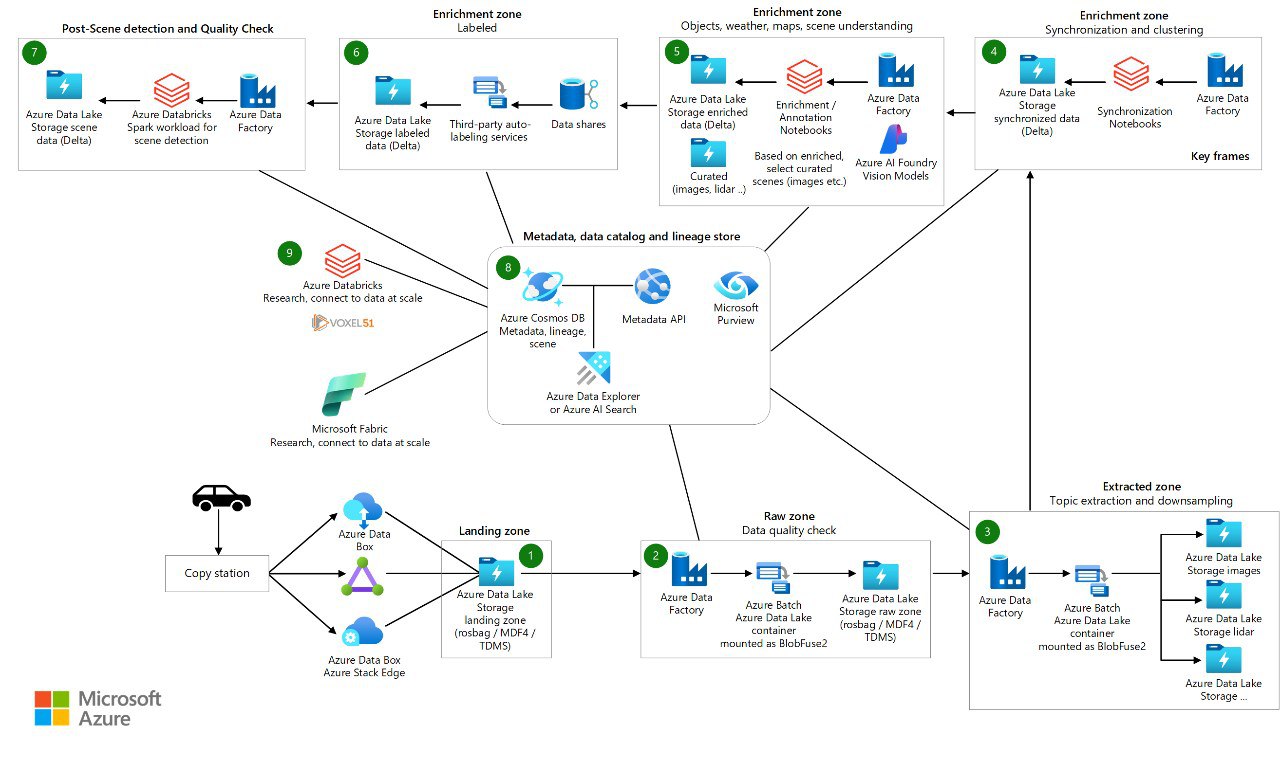
二、DataOps 并非工具,而是一场「工业敏捷」运动
什么是 Industrial DataOps?简单来说,它是 DevOps、敏捷开发和精益制造原则在数据领域的交叉应用。
它的核心目标不是「存储数据」,而是「交付高质量的数据产品」。在 2026 年的领先工厂里,DataOps 包含以下三个核心支柱:
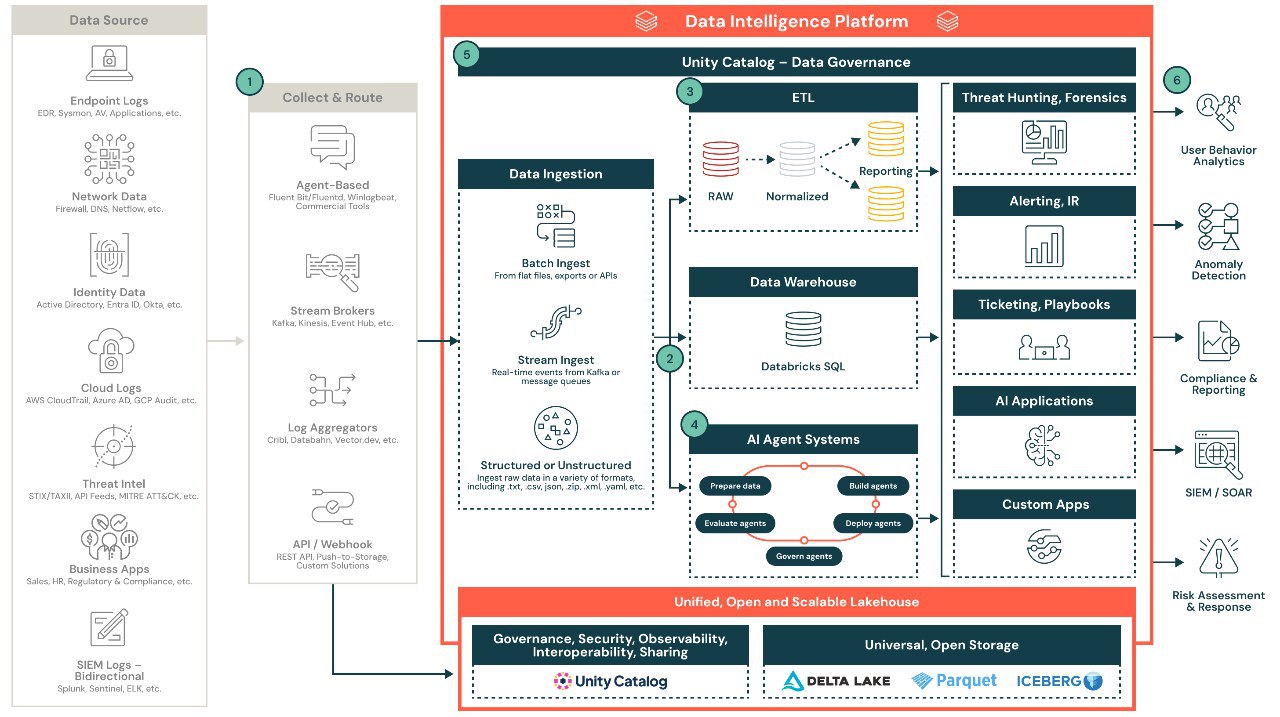
三、湖仓一体(Lakehouse):工业数据的「终极归宿」
在 DataOps 的推动下,工业软件的架构正集体转向 Lakehouse(湖仓一体)。
传统的做法是:要么存在 Data Lake(数据湖,便宜但乱),要么存在 Data Warehouse(数据仓库,好用但贵且死板)。Lakehouse 结合了两者的优点,并在 2026 年通过梅达利恩架构(Medallion Architecture)在制造业落地:
| 层级 | 状态 | 工业应用场景 |
|---|---|---|
| 铜牌层 (Bronze) | 原始数据 | 存储所有 PLC 的原始高频振动信号,作为事故溯源的「黑匣子」。 |
| 银牌层 (Silver) | 过滤与对齐 | 剔除异常值,将不同品牌的变频器数据标准化为统一物理单位。 |
| 金牌层 (Gold) | 业务就绪 | 形成「OEE 实时分析表」或「设备健康评分卡」,供高层看板调用。 |
为什么 Lakehouse 对工业至关重要?工业数据绝大多数是时间序列数据。Lakehouse 通过 Parquet 或 Delta Lake 格式,实现了对海量历史数据的高性能压缩,同时支持 SQL 实时查询。这意味着,你可以在同一个平台上,既让数据科学家训练「预测性维护」模型,又让财务经理查询上一季度的能耗报表。

四、从试点到规模化:跨越「死亡之谷」
2026 年,DataOps 市场的爆发点在于「规模化」。
过去,一家拥有 20 个工厂的企业,往往只能在其中一个工厂做一个漂亮的 AI 试点(Pilot)。但当他们想推广到全集团时,会发现每个工厂的 PLC 品牌、网络协议、甚至工艺流程都完全不同。
DataOps 解决了这一「不兼容」危机:
- 标准化模型:通过建立统一的「设备影子」或「资产管理壳(AAS)」,DataOps 将不同工厂的差异性屏蔽在底层。
- 低代码部署:现在的工业软件允许通过拖拽式界面,在几分钟内克隆一套数据管道到新厂区,而不是像过去那样耗费数月的工程服务。
ROI 洞察:根据市场调研,成功部署 DataOps 的企业,其数据产品的交付周期从数周缩短至不到 48 小时,运维成本平均下降 40%。
五、未来 24 小时之后的 2026:Agentic AI 的燃料
为什么现在(2026 年初)这个话题如此火爆?因为 Agentic AI(智能体 AI)正在敲门。
如果没有 DataOps 提供的干净、带上下文的数据,那些能够自主决策的 AI 智能体就会变成「满口胡言」的幻觉机器。工业 DataOps 实际上是为未来的「无人工厂」构建数字血液循环系统。
当 AI Agent 询问:「为什么 3 号生产线的废品率突然上升?」DataOps 支撑的 Lakehouse 会瞬间反馈:
「根据银牌层对齐的数据,3 号线在 10 分钟前的环境湿度超过了阈值,且当前批次的原材料来自去年曾有过质量投诉的供应商 B。」
这种跨维度的实时推理,正是工业 DataOps 爆发的终极逻辑。
结语
工业 DataOps 的市场爆发,标志着制造业正从「信息化」跨向「数据化」。这不是简单的系统升级,而是思维方式的彻底转变:不再把数据看作生产的副产品,而将其看作最核心的工业资产。
在这场变革中,谁先打破 SCADA 与 MES 的壁垒,建立起敏捷的湖仓一体架构,谁就握住了通往未来自治生产的入场券。
您是否对具体的工业 DataOps 平台感兴趣?我可以为您深度对比主流工具的技术架构与适用场景。