摘要:真正可靠的复杂Agent,不能只靠越来越长、越来越强硬的提示词来约束,而必须把关键逻辑写进确定性的程序结构里,比如循环、条件判断、状态机、检查点和验证机制。提示词负责表达意图,控制流负责保证执行。
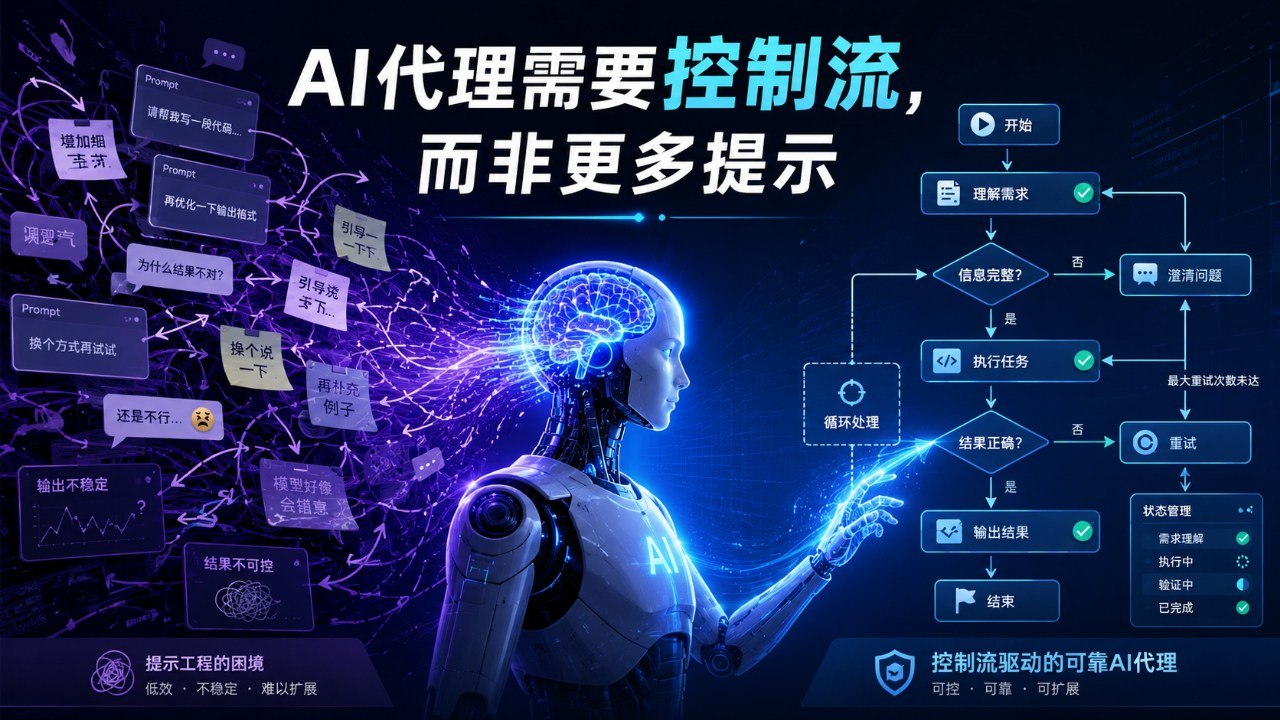
摘要:真正可靠的复杂Agent,不能只靠越来越长、越来越强硬的提示词来约束,而必须把关键逻辑写进确定性的程序结构里,比如循环、条件判断、状态机、检查点和验证机制。提示词负责表达意图,控制流负责保证执行。随着AI Agent从Demo走向企业落地,这条分工会越来越重要,因为真正的稳定性来自软件系统,而不是更像咒语的提示词。
一、AI Agent现在最常见的误区,不是模型不够强,而是系统设计不够稳
过去一年,AI Agent几乎成了技术圈最热的词。每家公司都在说自己要做智能体,每个产品都在说自己能自动完成任务,写代码、查资料、测试软件、整理文件、操作浏览器、调用工具、生成报告。听起来,AI Agent像是一个足够聪明的数字员工,只要给它一个目标,它就能自己规划、自己执行、自己检查,最后交付结果。
但最近一篇在 Hacker News 上引发热议的文章,给这个热潮泼了一盆很有价值的冷水。文章标题非常直接,Agents need control flow, not more prompts。作者的核心观点是,真正可靠的复杂Agent,不能只靠越来越长、越来越强硬的提示词来约束,而必须把关键逻辑写进确定性的程序结构里,比如循环、条件判断、状态机、检查点和验证机制。
这句话听上去像工程师的老生常谈,但它其实精准击中了当前AI Agent落地中的最大误区。很多团队在Agent不稳定时,第一反应不是改架构,而是改提示词。模型漏做一步,就在提示词里补一句“必须执行”;模型跳过文件,就写“严禁跳过”;模型输出不符合格式,就写“必须严格遵守JSON格式”;模型没有检查结果,就写“请认真自查”。提示词越来越长,语气越来越重,系统提示里充满了 MANDATORY、DO NOT SKIP、YOU MUST 这样的措辞。
问题是,当你开始依赖这种强命令式语气时,其实已经说明提示工程碰到了天花板。因为你正在试图用自然语言去模拟程序语言,用“请求”去替代“控制”。
二、提示词不是代码,这是很多Agent不稳定的根因
代码里的 for 循环会把200个文件逐个处理,提示词里的“请逐个处理200个文件”只是一个意图。代码里的 if 条件会在状态满足时进入某个分支,提示词里的“如果发现错误就重新检查”只是一个建议。代码里的函数返回值可以被类型系统、测试和日志验证,模型的自然语言输出则可能看起来像成功,实际上已经漏掉了关键步骤。
这就是为什么很多Agent在Demo里惊艳,在生产环境里却让人头疼。它们在开放任务、小规模试验、人工盯着看的场景里表现不错,但只要任务规模一大、状态一复杂、执行时间一长,问题就会集中爆发。漏步骤、重复执行、上下文漂移、状态混乱、失败不可恢复,几乎都是老毛病。
Hacker News讨论区里有个非常典型的案例。一位开发者分享,他们做了一个QA Agent,要在浏览器会话中检查大约200个Markdown需求文件。最初他们尝试直接让模型管理整个高层流程,进入目录、逐个读取需求文件、为每个需求创建待办项,再判断应用是否满足要求。但这个方案在处理到大约30个文件后开始失控,有时漏掉文件,有时重复测试同一批文件,有时因为一个文件出错又无端回头重测之前的文件,耗时也变得不可预测。
最后,他们在模型外面套了一个非常简单的确定性框架。程序负责遍历文件、触发测试、存储结果、写入文件;模型只负责单个测试项的判断。结果系统可靠性大幅提升。这个例子真正重要的地方在于,它不是“把Agent做小了”,而是重新定义了Agent和程序的分工边界。
三、模型擅长的是判断,不是记账
这个案例其实揭示了Agent工程化里最核心的一条原则,不要让大模型管理所有事情,而要让大模型只做它擅长的事情。
LLM最擅长的,是理解语义、解释文本、处理模糊输入、生成候选方案、做开放式判断。它在面对含糊的需求、自然语言材料、不完整信息和复杂语义关系时,表现出远高于传统规则系统的灵活性。
LLM最不擅长的,则是长时间记账、精确计数、稳定遍历、无遗漏执行、可重复状态管理。换句话说,模型适合做“大脑的一部分”,但不适合独自承担整个系统的“神经系统”和“骨架”。Agent不是一个大提示词,而应该是一个软件系统。提示词只是这个系统里的一个组件,而不是整个系统本身。
这一点非常重要,因为它把Agent从“玄学提示工程”重新拉回了“软件工程”。你不是在和一个神秘黑箱许愿,而是在设计一个包含不确定智能组件的可控系统。模型负责推理和判断,程序负责流程和保障,这种分工才是可持续的。
四、主流框架其实早就在提醒这件事
这并不是少数工程师的偏执观点。Anthropic 在 Building effective agents 中就明确区分过两类系统。一类是工作流,也就是LLM和工具沿着预定义代码路径运行;另一类才是更动态的Agent,由LLM自行决定流程和工具使用。Anthropic 同时提醒,构建LLM应用时应优先选择最简单的方案,只有在确实需要时才增加复杂度。对于定义明确的任务,工作流通常能带来更好的可预测性和一致性。
LangGraph 的文档用了几乎一模一样的说法。文档明确写到,workflows have predetermined code paths and are designed to operate in a certain order,而 agents are dynamic and define their own processes and tool usage。这个区别看似抽象,其实非常实际。凡是需要“必须做完、不能漏、能恢复、能审计”的任务,都应该尽量把流程交给代码,而不是交给模型的临场发挥。
LangGraph 之所以强调 persistence、debugging 和 deployment,也是在强调一件事,Agent系统最终要面对的是工程可靠性,而不只是模型能力。它不是只回答“模型聪不聪明”,而是要回答“系统能不能稳定跑下去”。
五、企业场景里的Agent,天然会走向控制流工程
这也是为什么Agent一旦进入企业环境,就会自然走向“控制流工程”。因为企业场景最怕的不是Agent不够聪明,而是它出错时没有边界。
比如客户服务Agent,不能只靠提示词说“遇到退款问题要谨慎”。它需要明确的权限边界、金额阈值、审批流程和异常升级机制。比如代码审查Agent,不能只靠提示词说“请认真检查安全漏洞”。它需要固定的检查清单、测试套件、静态分析工具、结构化输出和人工复核入口。再比如工业场景里的运维Agent,更不能只靠提示词说“请安全操作设备”。它必须依赖状态机、白名单工具、风险分级、回滚机制、审计日志和多级确认。否则,一个看似聪明的Agent,很快就会变成一个不稳定的自动化风险源。
所以,未来真正有价值的Agent工程,绝不是把提示词写得越来越像咒语,而是把系统拆成清晰的三层。
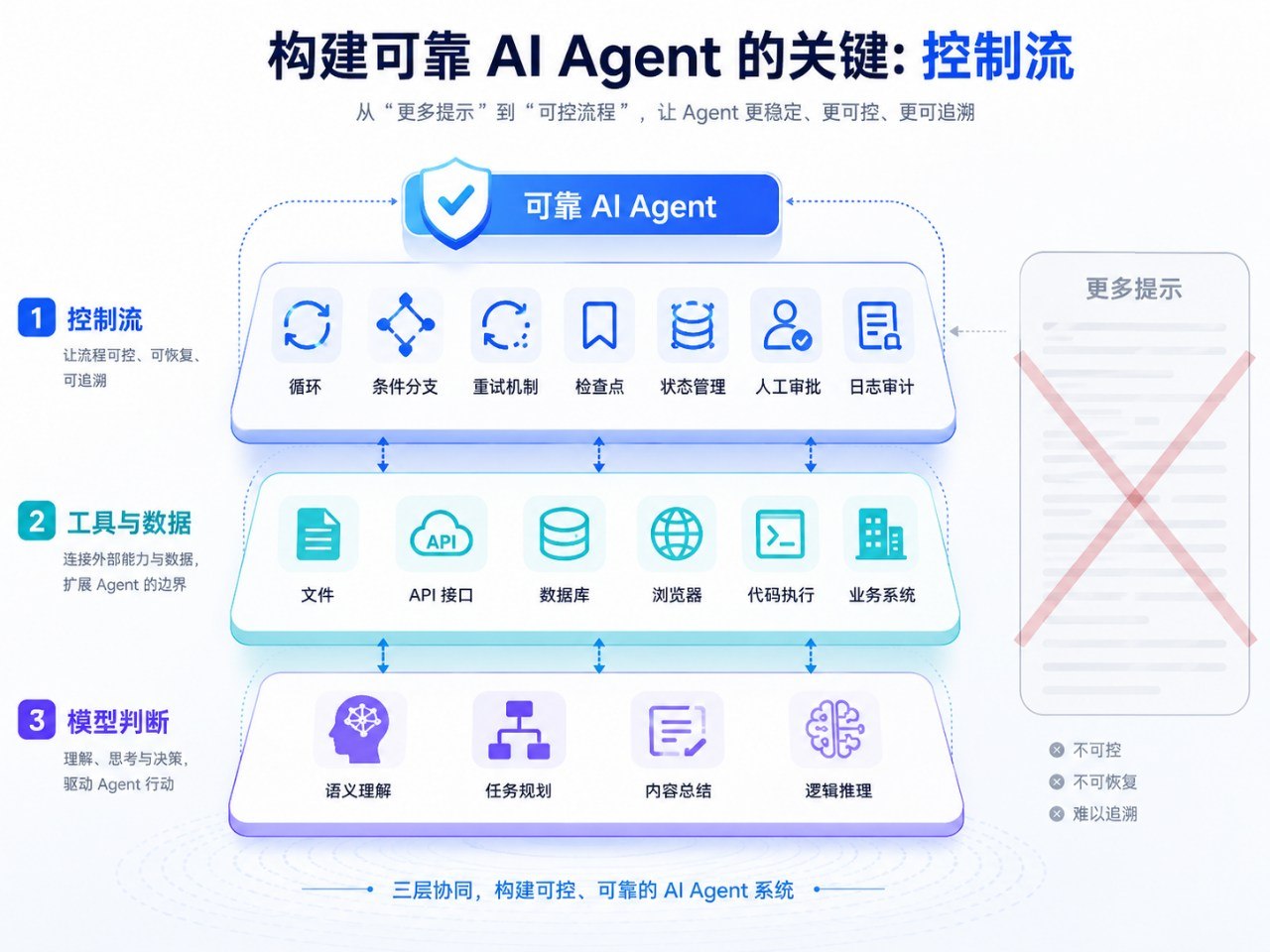
第一层,是确定性控制层。它负责循环、分支、状态、重试、超时、权限、日志和恢复。它回答的是,下一步做什么,做完没有,失败怎么办,能不能重跑。
第二层,是工具与数据层。它负责文件、数据库、API、浏览器、代码执行环境、检索系统和业务系统连接。它回答的是,模型能调用什么,能看见什么,能改动什么。
第三层,才是模型判断层。它负责语义理解、归纳总结、模糊判断、生成候选方案和解释原因。它回答的是,这段文本是什么意思,这个异常像不像风险,这个需求是否被满足,下一步建议是什么。
很多失败的Agent,本质上就是把这三层混在了一个超长提示词里。
六、OpenAI 和 LangGraph 都在把这件事写进产品结构里
OpenAI 的 Agents SDK 文档其实已经体现出同样趋势。文档明确说,当你的服务器拥有 orchestration、tool execution、state 和 approvals 时,就应该走 SDK 这条代码优先的路径。也就是说,当你的系统需要自己管理编排、工具执行、状态和审批时,提示词已经不够,必须进入工程控制层。
同样,OpenAI 关于 Guardrails 和 human review 的文档强调,应该给SDK工作流加入自动验证和人工审批,而不是只让模型“自觉遵守规则”。Guardrails 的思路不是靠提示词拜托模型守规矩,而是在输入、输出和工具调用的边界上增加检查、拦截和批准机制。尤其在 managers、handoffs 或多专家工作流里,文档还特别提醒应使用工具级 Guardrails 来覆盖每一次函数调用,而不是只依赖Agent级别的输入输出约束。
更进一步,OpenAI 关于 running agents 的文档把 approval request 视作 paused run,而不是 new turn。这种表述非常关键,因为它说明成熟Agent系统关注的是运行状态的连续性,而不是一次次对话表演。系统要知道自己暂停在哪里、恢复到哪里、历史和上下文怎么延续,这已经完全是控制流和运行时管理的问题了。
七、持久执行会成为下一代Agent的基本能力
如果再往前看一步,真正成熟的Agent系统还必须具备持久执行能力。LangGraph 强调 durable execution 的意义,是让工作流在关键节点保存进度,遇到中断、错误或人工介入之后,可以从记录状态恢复,而不是从头重跑。这要求工作流尽量确定性、幂等,并把有副作用的操作包裹起来,避免恢复时重复执行。
这听起来很像传统后端工程、分布式任务系统和工业控制软件里的要求,没错,本质上就是同一类问题。Agent不是漂浮在聊天界面里的“智能幻觉”,它一旦要做真实工作,就必须进入真实系统的可靠性要求。断点恢复、错误重试、状态持久化、可审计日志、人类审批、权限隔离,这些不是可选增强包,而会逐渐成为Agent系统的基本构件。
所以,“AI代理需要控制流”背后的真正变化其实是,Agent开发正在从“会不会写提示词”,进入“会不会设计系统”。早期Agent像一个聪明实习生,你给它一句话,它给你一个惊喜。生产级Agent更像一条自动化产线,每个节点做什么、失败怎么处理、结果如何验证、谁有权限放行,都必须有结构。
八、未来的好Agent,不是提示词最长,而是边界最清楚
这并不意味着提示词不重要。提示词仍然是模型行为的重要接口,它定义局部任务、说明判断标准、约束输出格式、提供上下文。但提示词的职责应该收缩,而不是膨胀。它负责表达意图,控制流负责保证执行。
这会成为未来Agent产品竞争的一个真正分水岭。只会做聊天框式自动化的Agent,看起来很智能,但很难稳定。懂得把模型嵌入业务流程里的Agent,看起来没那么炫,却更可能真正落地。在企业里,最有价值的Agent不会是一个“万能大脑”,而是一组被控制流组织起来的智能组件,能调用工具,能保存状态,能分解任务,能验证结果,能在不确定时停下来,能在人类需要介入时把完整上下文交出来。
这听起来有点像是在“重新发明编程”。某种意义上,确实是。但这恰恰说明,AI Agent不是软件工程的替代品,而是软件工程的新阶段。过去我们写程序,是把确定性逻辑写给机器执行;现在我们写Agent,是在确定性软件结构中嵌入不确定的智能判断。
未来的好Agent,不是提示词最长的Agent,而是边界最清楚、流程最稳、失败最可控的Agent。真正的问题已经不是“怎么让模型更听话”,而是我们能不能重新学会,把智能放进可靠的系统里。