摘要:大模型竞争越来越像一场全球统一命题的高考。每家公司都能讲自己的故事,但一旦进入公开测评、盲测榜单、数学证明、代码修复和长任务Agent场景,故事就会被压缩成一句话,你到底考了多少分。

摘要:大模型竞争越来越像一场全球统一命题的高考。每家公司都能讲自己的故事,但一旦进入公开测评、盲测榜单、数学证明、代码修复和长任务Agent场景,故事就会被压缩成一句话,你到底考了多少分。真正决定全球认知的,不是口号,而是答卷。
一、为什么今天看大模型,越来越像在看一场全球统一命题的高考
最近看大模型竞争,越来越像一场全球统一命题的高考。
每家公司都可以讲自己的故事,我参数更大、我算力更多、我生态更强、我更懂中文、我更懂行业、我更安全、我更便宜。但真正到了公开测评、盲测榜单、数学证明、代码修复、长任务 Agent 这些场景里,故事会被压缩成一句话,你到底考了多少分。
这也是为什么我越来越觉得,大模型竞争在某种意义上反而比很多产业竞争更公平。它当然不是绝对公平,训练数据、算力、人才、资金、渠道都不公平;但它有一个非常残酷的校准机制,只要你声称自己强,就必须到公共考场上接受检验。
传统软件可以靠渠道、销售、客户关系、定制项目慢慢积累口碑,但大模型的核心能力很难靠宣传长期遮掩。用户一问、一写代码、一做数学题、一跑 Agent,差距很快就会暴露。今天评价模型,已经不能只看厂商自己做的 PPT,也不能只看发布会上的关键词堆砌,而要看它在公共环境里是否真的站得住。
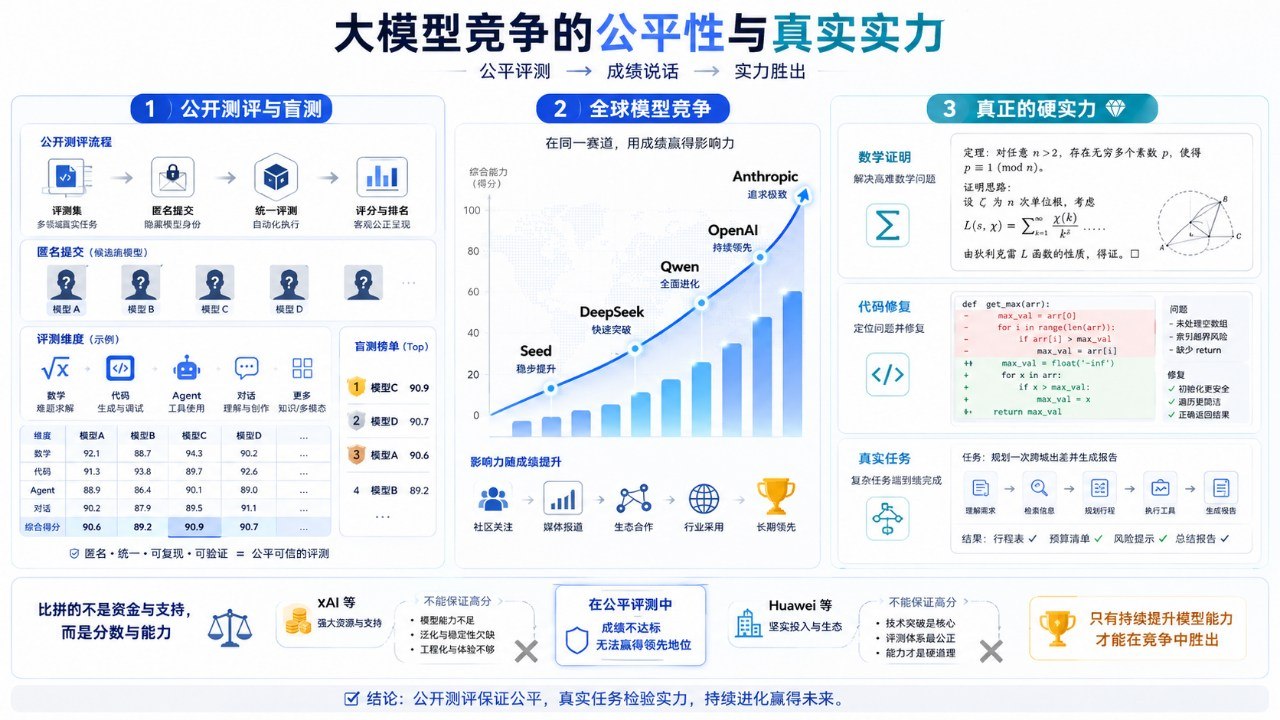
二、为什么“国际测评”会越来越重要
今天判断一个模型到底强不强,至少要看三类证据。
第一类,是静态 benchmark,比如数学、代码、科学问答、指令遵循、长上下文、Agent 任务等。它们的问题虽然预先定义,但好处是可重复、可比较、可长期跟踪。像 Artificial Analysis 的 Intelligence Index,就是把多个高难评测合成为一个综合指标,覆盖数学、科学、代码和推理等方向,本质上是在为模型能力建立一个可横向对比的坐标系。
第二类,是动态盲测,比如 LMArena。它的机制很简单,同一个问题交给两个匿名模型回答,用户不知道谁是谁,只选自己认为更好的那个。这样做最大的价值,是把品牌光环、发布会叙事和营销包装尽量剥离掉,让模型先靠输出内容说话。盲测不是完美真理,但它的杀伤力极大,因为它把“谁讲得更好”压缩成了真实用户的一票一票选择。
第三类,是现实任务成绩,比如 SWE-bench、Terminal-Bench、真实代码库修复、金融 Agent、数学证明、科研辅助。这类测试越来越重要,因为它们不再只是问模型“会不会回答问题”,而是在问它“能不能完成工作”。
这也是为什么,不去国际榜单测评越来越难有说服力。不是因为国际榜单天然神圣,而是因为它把模型放进了同一个可比较环境里。你可以不喜欢考试,但不能一边拒绝考试,一边宣称自己全班第一。
三、盲测榜单并不完美,但它依然是最有公共约束力的信号之一
LMArena 的公平性,很大程度来自两个设计,匿名和实时。模型先进入盲测,积累足够投票后才上榜;有些未正式发布的模型,也会先以匿名代号进入 Arena,等成绩稳定后再公开身份。这套机制给了新玩家真正的机会,因为它在一定程度上打破了“大厂天然占据话语权”的结构。
这也是为什么后来很多中国模型能被海外开发者认真讨论,不是因为它们自称“国产领先”,而是因为它们真的进入了第三方榜单、开源社区、API 平台和真实开发者工作流,能够被全球用户直接试、直接比、直接吐槽。
但榜单当然也并不完美。静态 benchmark 容易有数据污染问题,训练数据可能已经覆盖了部分题目;动态众包投票也不是完全没有操纵风险。有人可以组织投票,有人可以利用提示偏好,有人也可能故意优化“Arena 风格”的回答方式。
所以,榜单不能迷信,但也不能轻视。它不是终局真理,却是目前最有公共约束力的信号之一。它最大的价值,不是保证绝对公平,而是逼迫所有模型都接受外部校准。
四、中国模型真正的崛起,不是靠情绪价值,而是靠分数
中国模型这两年的进步,最值得尊重的地方,不是情绪动员,而是它们真的开始拿分。
DeepSeek 是一个典型案例。它真正震动硅谷,不是因为“国产大模型”这几个字,而是因为低成本、高性能、开放权重和开发者实际可用性形成了组合拳。全球开发者之所以认真讨论它,不是出于政治正确,而是因为它的输出质量和成本效率真的改变了原本对大模型市场结构的预期。
阿里的 Qwen 也是类似路径。Qwen 能在国际开发者社区建立尊重,不是因为阿里是大厂,而是因为它长期开放模型、持续刷榜、进入真实 API 使用和开发者工具链。资源是基础,但资源不会自动转化为口碑,真正转化口碑的,是持续交出看得见的成绩。
字节的 Seed 系列也一样。如果它只在国内发布会上说自己“面向复杂真实任务、支持多模态理解、长程任务能力更强”,影响力其实有限。真正有用的是,它是否进入全球可测、可试、可比较的环境,是否被开发者放进真实工作流里反复使用。
反过来看,一些资源同样雄厚的公司,虽然有算力、有客户、有行业场景,也不等于通用大模型前沿能力已经建立全球说服力。行业项目能力、政企部署能力、国产替代能力,和“通用前沿大模型是否真的领先”,并不是同一个问题。在大模型这场考试里,不能用“我有考场”去代替“我考得好”。
五、国外头部模型为什么仍然强,因为它们已经从答题走向了做题外题
再看 Anthropic 和 OpenAI,今天它们的强势也不是靠品牌情怀,而是因为它们持续在更难的题上交卷。
Claude 的影响力,不只是因为它“会聊天”,而是因为它在代码、Agent、长上下文、复杂推理这些高难度场景里持续拿出了结果。越往前走,真正拉开差距的能力,不再是写一段通顺答案,而是能不能在大代码库里稳定调试,能不能在复杂任务里长时间保持一致性,能不能在开放问题上给出真正有价值的思路。
更关键的是数学。数学证明是大模型能力最硬的试金石之一,因为它要求模型不仅会说,还要能推理、构造、验证。代码可以部分依赖模板,写作可以部分依赖风格,但证明不行。证明要的是链条闭合,要的是中间每一步都经得起追问。
这也是为什么,最近关于模型参与数学研究、解决开放问题、给出形式化证明的讨论越来越多。这里当然要非常谨慎,很多突破并不是“模型单独坐在那里自动成为数学家”,而是人类提出问题、设计提示、筛选思路、形式化验证、修补证明共同完成。但即便如此,这个趋势已经足够清晰,最强模型正在从“会回答问题”逐步进入“能参与知识生产”的阶段。
这件事的意义非常大。因为一旦模型能在数学、代码、科研这些高约束任务里稳定贡献价值,它的竞争就不再只是产品层面的聊天体验之争,而会直接进入知识生产力和高端工作流重构。
六、大模型竞争像高考,残酷,但相对公平
所以,大模型竞争真的有点像高考。
高考当然不是绝对公平。家庭背景、教育资源、城市差异都存在。但它仍然比“谁家关系硬、谁嗓门大、谁广告多”公平得多。大模型榜单也是如此。它不能衡量一切,却会持续制造一种外部压力,你不能长期只讲叙事,不交答卷。
这也是为什么,哪怕是最有流量、最有资源、最有个人光环的玩家,也不能自动统治这场比赛。创始人是谁、发布会多热闹、融资额多夸张,都不能直接决定你在榜单上排第几,更不能直接决定开发者愿不愿意把真实任务交给你。
中国公司也是一样。谁能起来,最终不看宣传口径,而看它能不能持续在开源、代码、Agent、国际榜单和开发者采用上连续交卷。谁如果不参加同一套公开考试,或者参加之后成绩不够亮眼,就很难获得真正的国际说服力。
这也是我觉得大模型产业最有意思的一点。它一方面极度不公平,因为资源差距客观存在;另一方面又极度公平,因为最终每个人都得面对同一批用户、同一类任务、同一套越来越公开的比较机制。
七、不要逃避考试,也不要迷信考试
今天评价大模型,最危险的态度其实有两种。
一种是榜单崇拜。看到某个模型某一周登顶,就宣布世界格局已定。大模型迭代太快,榜单永远只是某个时刻的快照。参数在变,训练在变,推理策略在变,产品化能力也在变,没有任何一张榜单能一次性宣布永久胜负。
另一种是榜单虚无。只要成绩不好,就说榜单不公平、评测不懂中文、国外平台有偏见、用户不理解本地场景。这种态度更危险,因为它会让企业失去外部校准,最后活在自己的发布会和自我表扬里。
真正健康的态度应该是,承认测评不完美,但必须参加测评;承认榜单有噪声,但必须尊重榜单;承认模型有本地场景差异,但不能用本地叙事去逃避全球比较。
大模型时代,宣传口号的保质期越来越短。模型好不好,最终要看它能不能在盲测里赢,在代码库里修 bug,在数学里给出新证明,在企业里完成真实任务,在开发者手里被反复调用。
这就是这场竞争最残酷也最令人兴奋的地方。它让天才创业公司、大厂实验室、国家级平台、超级富豪项目,最后都坐进了同一个考场。
铃声一响,名字不重要,背景不重要,故事不重要。
答卷才重要。