最近在X上看到Eli Mernit(@mernit)的帖子,分享了一篇题为《Your Company is a Filesystem》的文章。这个观点乍看简单,却直击AI代理时代的核心痛点:企业数据该怎么组织,才能让AI真正高效地"工作"。
Eli的论点可以用一句话概括:公司就是一个文件系统。一切数据抽象成文件和文件夹,AI代理通过最熟悉的读/写/执行接口访问它们,而不是纠缠于成百上千的SaaS API。
这让我想到一个更宏大的历史轮回:从Unix时代的"一切皆文件",到关系型数据库的崛起,再到NoSQL的爆发,如今在AI代理的推动下,我们似乎又回到了文件系统的怀抱。
这不是倒退,而是螺旋上升。文件系统作为人类和机器最自然的交互抽象,正在以全新方式复苏。
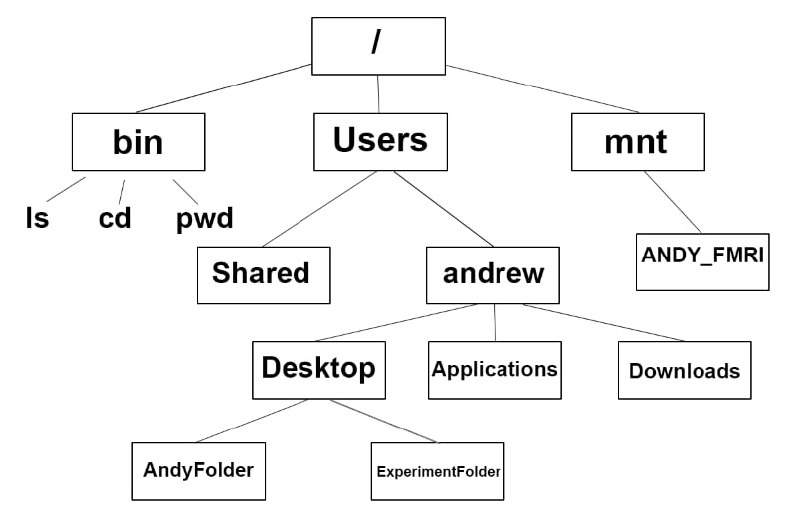
一、起点:Unix的"一切皆文件"哲学(1970s)
Unix诞生于1970年代,Dennis Ritchie和Ken Thompson提出的核心理念之一就是**“Everything is a file”**。设备、进程、网络、管道……统统通过文件接口访问。文件系统采用层次树状结构(hierarchical tree),根目录/下分支成/bin、/etc、/home等。
这种设计为什么强大?
| 特性 | 说明 |
|---|---|
| 统一接口 | 程序员只需学会open/read/write/close,就能操作几乎所有资源 |
| 简单可组合 | 管道(pipe)和重定向让命令行工具像积木一样拼接 |
| 人类直观 | 文件夹和文件是现实世界的隐喻,易于理解和导航 |
早期数据库其实也依赖文件系统:数据以平坦文件或简单层次存储,查询靠手动遍历。但随着数据规模和复杂度增长,文件系统的局限暴露:缺乏高效索引、事务一致性、并发控制。1970年Edgar F. Codd发表关系模型论文,标志数据库正式独立成体系。
二、数据库的黄金时代:从关系型到NoSQL(1970s–2010s)
1970年代后,数据库快速发展:
层次数据库 & 网络数据库(1960s–1970s)
如IBM的IMS,数据以树状或图状组织,但查询路径固定,灵活性差。
关系型数据库(RDBMS)(1970s起)
Codd的模型用表、行、列组织数据,SQL标准化查询。Oracle(1979)率先商用,MySQL、PostgreSQL等开源跟进。优势是规范化(normalization)、ACID事务、复杂JOIN查询。
1990年代起,面向对象数据库短暂兴起,但关系型主导企业级应用。
NoSQL崛起(2000s–2010s)
2000年代互联网爆炸,产生海量非结构化/半结构化数据:
- MongoDB(文档)
- Cassandra(列式)
- Redis(键值)
- Neo4j(图谱)
它们牺牲部分一致性,换取水平扩展和高吞吐,完美适配Web 2.0的大数据场景。
数据库为什么取代文件系统成为主流?
但代价是:数据被锁在黑盒中。每个数据库有自己的API、schema、驱动。开发者要学无数接口,AI代理更难直接"理解"。
三、轮回开始:AI代理时代,为什么又回到文件系统?
2025–2026年,AI代理(Agentic AI)爆发。代理不再是聊天机器人,而是能自主规划、多步执行、长期记忆的系统。但它们面临两大瓶颈:
瓶颈1:上下文窗口有限
即使Claude有200k token,也无法塞下整个企业数据。
瓶颈2:状态管理缺失
LLM是无状态的,每次调用从零开始。需要外部"记忆"来实现跨会话连续性。
文件系统在这里重新胜出
| 优势 | 说明 |
|---|---|
| LLM天生熟悉 | 模型在训练中见过无数代码和文档,知道ls、cd、cat、grep、echo等操作。文件接口是"零学习成本"的抽象 |
| 无限扩展 | 不像上下文窗口有上限,文件系统可外挂到本地磁盘、云存储,甚至分布式(如S3) |
| 持久与可审计 | 文件天然支持版本(Git)、权限(chmod)、日志。代理写中间结果到文件,下次唤醒直接读取 |
| 简化集成 | 不用为每个SaaS写适配器,只需把数据"物化"为文件夹 |
社区实践
- Dust.tt:把Slack频道、Notion页面、GitHub仓库抽象成虚拟文件系统
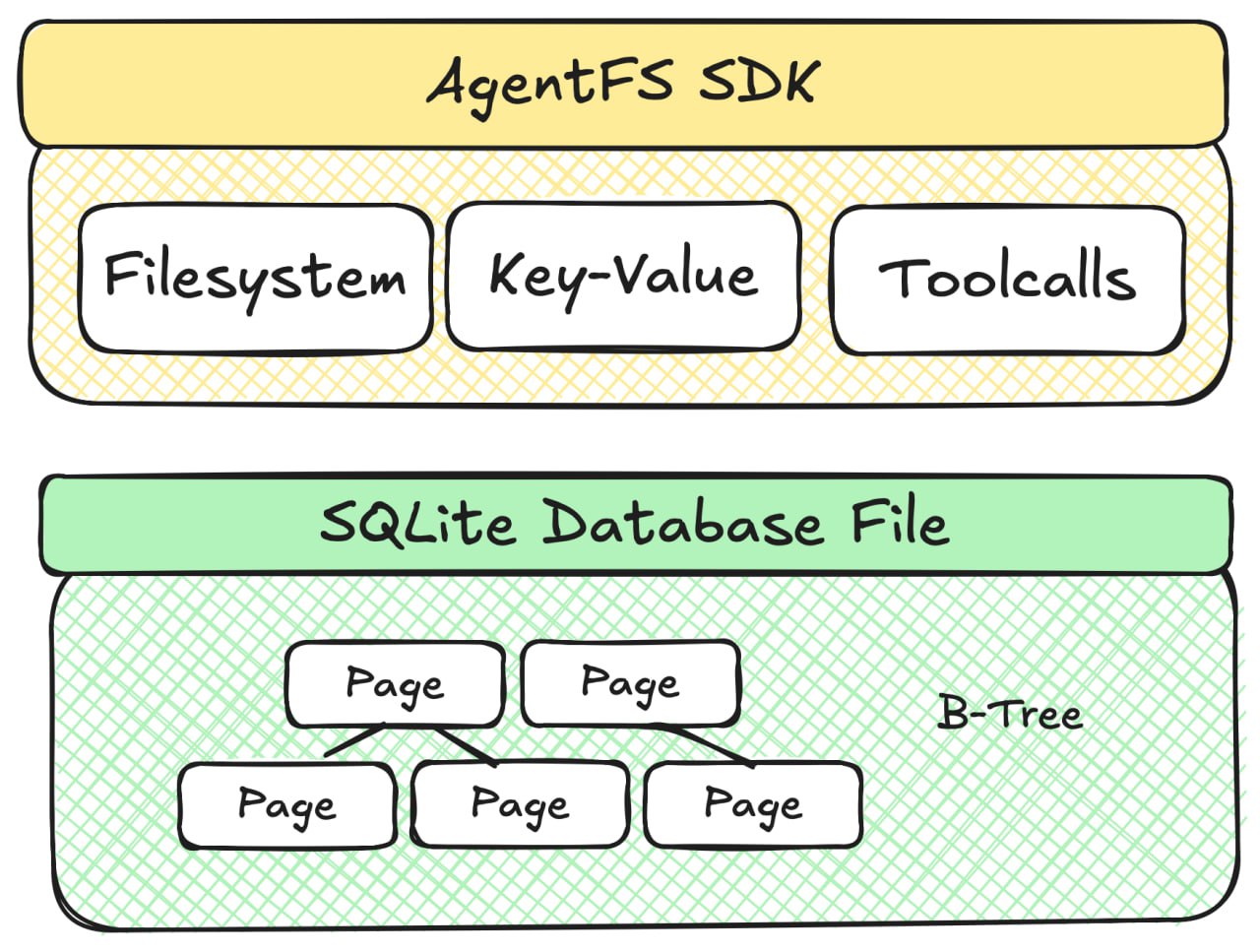
- Turso的AgentFS:基于SQLite的文件系统抽象,提供POSIX-like接口+工具调用追踪
- Oracle博客讨论:文件系统胜在接口友好,数据库胜在底层保证(并发、语义搜索)。最佳是混合:数据库做substrate,文件系统做interface
Eli在文章中强调,权限即治理:Unix的rwx映射到公司角色(员工只读写特定项目,合伙人有root)。这比数据库的RBAC更直观,也更易让AI遵守。
四、Airstore.ai:从理念到落地的桥梁
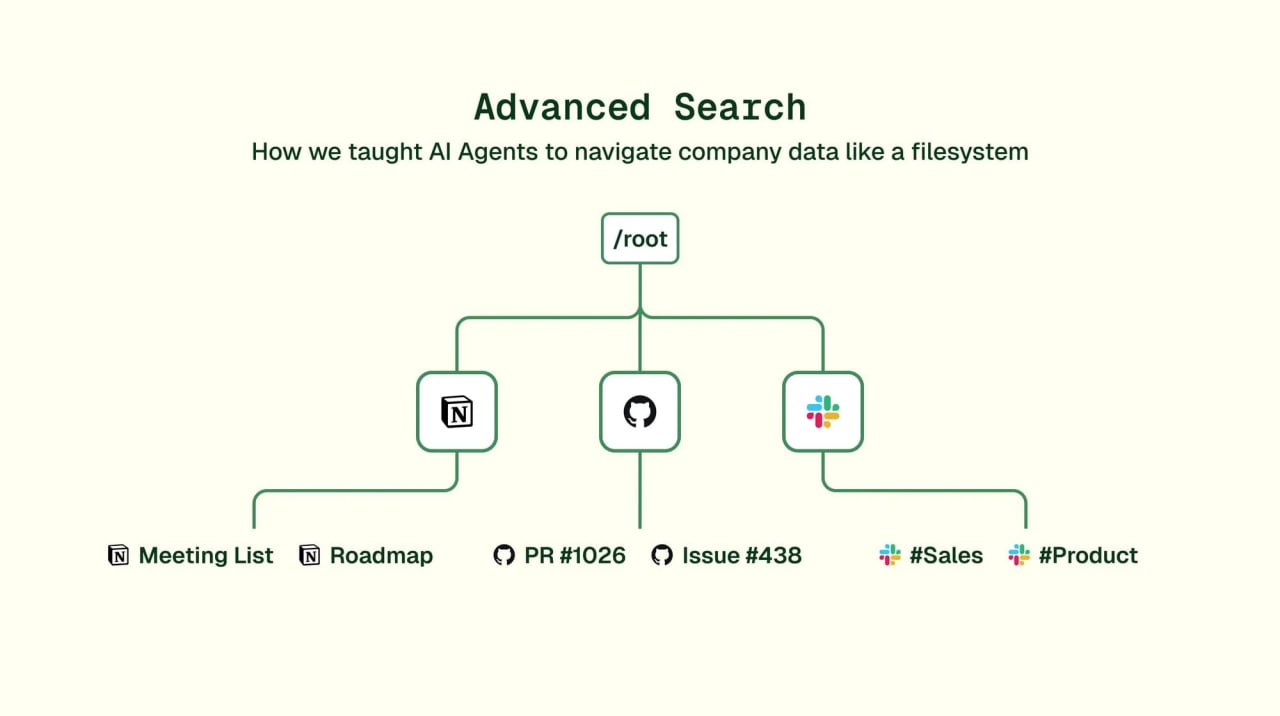
Eli的文章直接服务于他的产品Airstore.ai:
- 核心:虚拟文件系统,将多源数据转为本地文件夹
- 用法:自然语言描述需求 → LLM生成视图 → 后台同步 → 代理读取精确上下文
- 优势:解决记忆孤岛。代理如OpenClaw/Claude Code可跨会话"回忆",因为状态持久在文件里
- 例子:
- PR审查机器人读
/github/open-prs/diffs - 邮件分类器操作
/gmail/inbox/labels
- PR审查机器人读
这不是取代数据库,而是补位:在需要强一致性时用DB做后端,暴露文件接口给AI。
五、未来展望:螺旋上升的存储范式
这个轮回不是简单回归,而是融合:
文件系统 + 数据库混合
文件做前端接口(人类/AI友好),数据库做后端(事务、索引、向量搜索)。
AI-native抽象
未来可能出现"Agent Filesystem",内置:
- 工具调用追踪
- 自动版本
- 语义查询(如"找所有提到’Q4目标’的文件")
企业转型
护城河从SaaS API转向"业务文件夹"组织。咨询公司的TOM模型,以后或许就是一堆.md + 文件夹结构。
挑战依然存在
- 大文件同步慢
- 噪声控制
- 隐私
但方向清晰——当AI成为主要"用户"时,最自然的接口往往是最古老的。
结语
Eli的帖子获数百点赞,不是因为新奇,而是戳中了痛点:我们花了50年把数据从文件搬到数据库,现在又要搬回来,只为让AI更好地"工作"。
你的公司准备好当一个"文件系统"了吗?
或许,从今天开始,让AI代理cd到你的/root试试。
参考链接:
本文基于公开资料整理,由工业智能算网发布。