摘要:国家数据局发布的行业高质量数据集建设行动,真正指向的不是“多建一些数据集”,而是把数据、模型、场景和价值释放组织成产业智能化的新闭环。
国家数据局 6 月发布《关于推进行业高质量数据集建设行动的实施方案》,表面上看是一份数据集建设文件,实际上它切中了人工智能产业落地的关键瓶颈:大模型已经证明了通用能力,但要进入工业制造、能源、交通、医疗、政务等真实场景,缺的往往不是又一个通用模型,而是能让模型理解行业、执行任务、持续迭代的高质量数据。
过去几年,人工智能讨论的中心常常是算力、参数规模和模型榜单。企业也容易把智能化理解成“接入一个大模型”。但当模型进入实际业务,就会遇到三类问题:行业知识不够深,现场数据不够干净,应用反馈无法回流。于是模型看起来很聪明,真正落到生产系统里却不稳定、不可信、不经济。国家数据局这次强调行业高质量数据集,本质上是在把人工智能竞争从“模型单点能力”推向“场景、数据、模型、应用”的系统能力。
一、AI-Ready:不是有数据就能训练模型
政策里一个重要关键词是“人工智能就绪”,也就是 AI-Ready。它提醒我们,数据资源和模型可用数据之间隔着一整套工程过程。
企业手里有大量业务数据,但原始数据往往分散在设备、系统、表格、文档、图片、日志和人工经验里。它们格式不统一、口径不一致、噪声多、权限复杂,也缺少面向模型任务的标注、质检和评测。如果直接拿这些数据训练模型,结果很可能是成本高、效果不稳定,还会把错误经验放大。
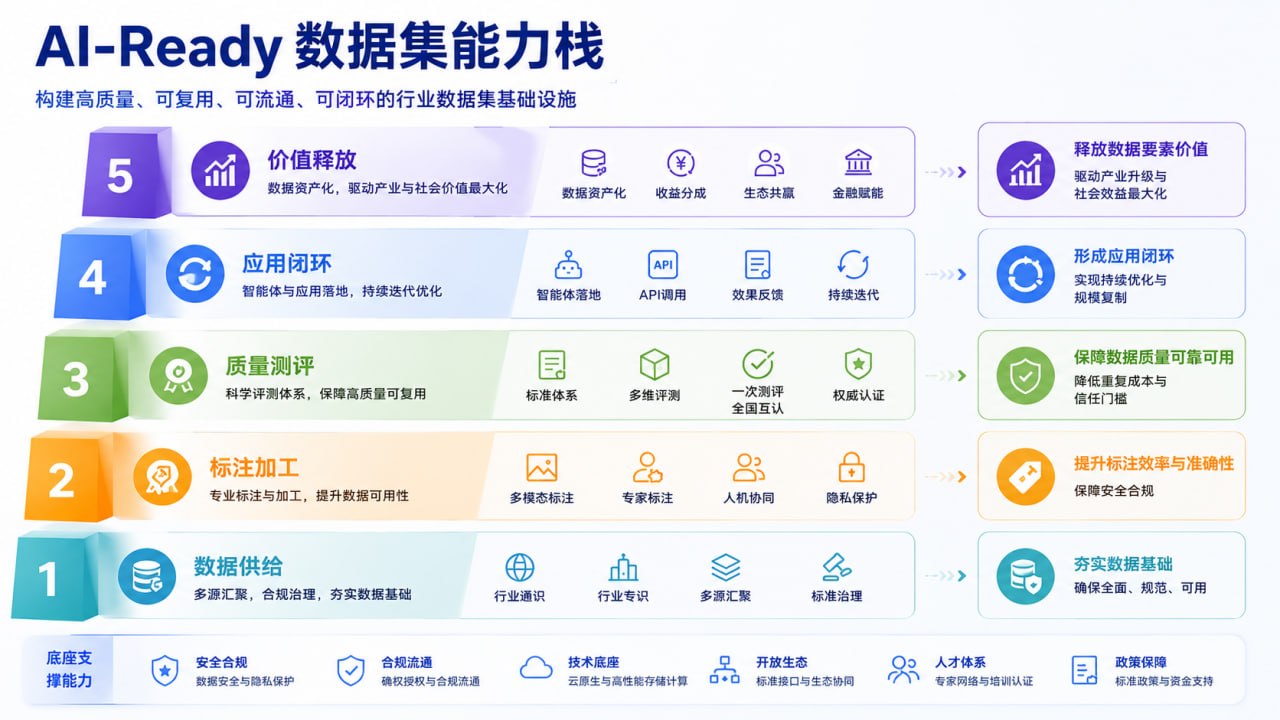
AI-Ready 数据集要解决的就是这个问题。它不是简单的数据打包,而是经过采集、清洗、增强、标注、对齐、质检、测评和迭代之后,能够支撑预训练、指令微调、强化学习、能力评测和智能体应用的数据体系。换句话说,高质量数据集不是数据库的副产品,而是面向模型能力生产的基础设施。
二、从“数据供给”到“数据飞轮”
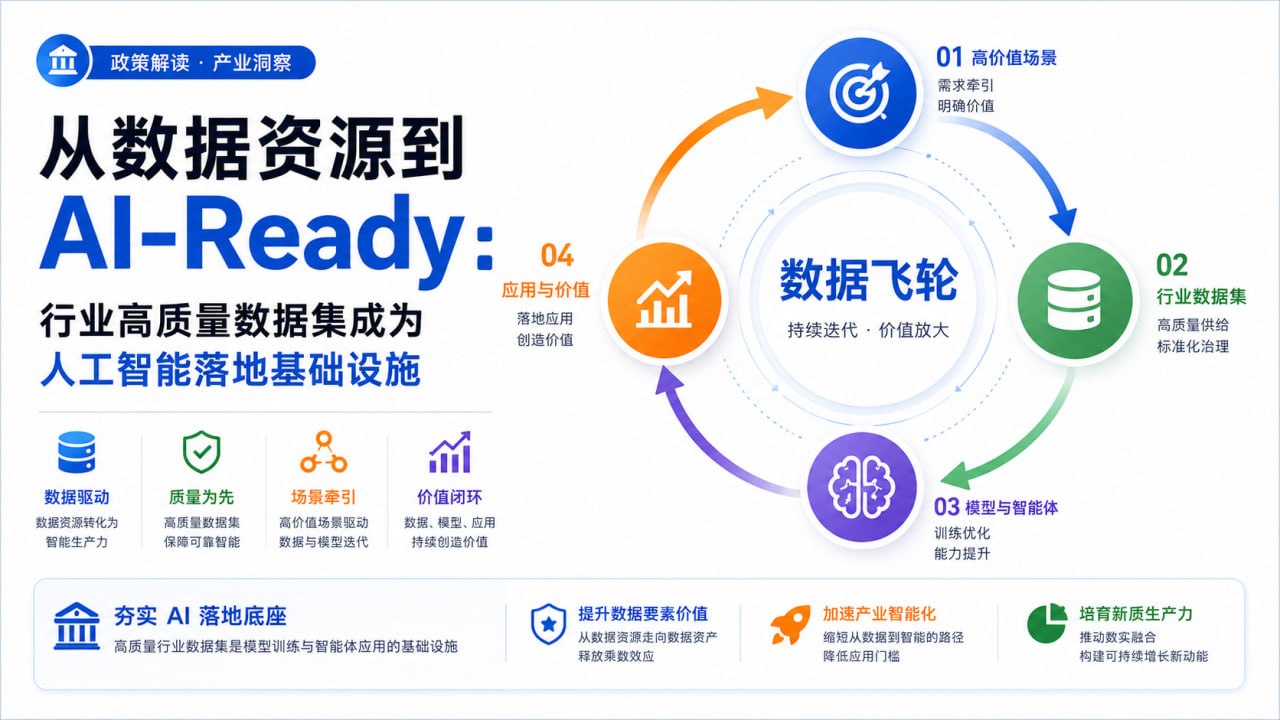
这份方案最值得关注的,不是单独提出建设多少数据集,而是提出了一个闭环逻辑:场景牵引数据,数据驱动模型,模型赋能应用,应用创造价值。
这其实是产业智能化的“数据飞轮”。先从高价值场景出发,明确模型要解决什么问题;再倒推需要哪些行业通识数据和行业专识数据;随后用这些数据训练、微调或评测行业模型和特色智能体;模型落地后,应用过程又产生新的交互数据、反馈数据和评测结果,反过来优化数据集和模型能力。
如果没有这个闭环,数据集很容易变成一次性项目:建完、验收、沉睡。如果有闭环,数据集就变成可持续运营的资产,模型也不再是一次性采购的软件,而是可以随着业务反馈不断进化的能力系统。
三、智能体让数据集价值进一步放大
政策中特别提到复杂任务规划、长程推理、人机交互、决策执行等数据集建设,并明确指向智能体等新型智能应用形态。这一点很关键。
传统模型更多回答问题,智能体则要完成任务。它需要理解业务状态,调用工具,规划步骤,处理异常,并在多轮交互中保持目标一致。要训练和评测这类能力,光有问答语料不够,还需要流程数据、操作数据、工具调用轨迹、异常处置案例、专家标注和场景反馈。
因此,未来真正有价值的行业数据集,可能不只是“文档库”或“知识库”,而是包含任务流程、决策逻辑、操作记录和评测标准的复合型数据资产。谁能把行业经验转化成可训练、可评测、可复用的数据集,谁就更接近智能体落地的核心位置。
四、企业机会不只在做模型
这份政策也给企业指出了不少新的产业机会。
第一是数据治理和数据工程。企业需要梳理数据资源清单和数据集需求清单,把沉睡在业务系统里的数据变成可加工、可授权、可追溯的资源。
第二是专业数据标注。政策强调人机协同和专家深度参与,说明低端标注会继续被自动化工具压缩,真正有价值的是懂行业、懂知识结构、懂模型任务的专家型标注。
第三是数据集测评。数据质量不能只靠主观判断,必须通过标准、质检、模型反馈和评测数据集来验证。未来“数据集好不好”会变成一个可测量、可认证、可互认的问题。
第四是行业智能体解决方案。工信部和国家数据局此前联合推动“模数共振”行动,已经把行业模型、专用模型、特色智能体和高质量数据集放在同一个框架里。对产业服务商来说,单卖模型会越来越难,围绕“数据集 + 模型 + 工具 + 场景应用”的全栈方案会更有竞争力。
第五是数据资产化和商业模式。政策提出探索订阅、商场、定制、API 调用、模型化解决方案等多元服务形态,也提到数据集资产盘点、登记、评估和融资创新。这意味着高质量数据集有机会从成本中心变成可运营、可交易、可融资的生产资料。
五、对产业智能化的真正启示
如果把这份政策放到更大的背景里看,它释放了一个清晰信号:人工智能落地正在从“模型驱动”转向“数据—模型—场景协同驱动”。
未来企业竞争的分水岭,不是有没有接入大模型,而是有没有把自己的行业数据、专家知识、业务流程和应用反馈组织成可持续进化的数据飞轮。通用模型会越来越强,但行业差异不会消失。越是接近真实生产、真实设备、真实决策的场景,越需要高质量行业数据集来补齐模型和业务之间的最后一公里。
这也是这份政策适合被长期关注的原因。它不是一个单独的数据工程文件,而是把数据要素市场、人工智能+、智能体、行业模型和产业智能化连接了起来。下一阶段,真正的机会很可能不在“谁喊出更大的模型口号”,而在“谁能把行业数据变成模型可以学习、可以评测、可以执行、可以创造价值的基础设施”。
两张图的生成提示词
图一提示词:
生成一张 16:9 横版中文科技政策解读封面图,主题为“从数据资源到 AI-Ready:行业高质量数据集成为人工智能落地基础设施”。画面中心是“数据飞轮”,四个节点分别为“高价值场景、行业数据集、模型与智能体、应用与价值”,用清晰箭头形成闭环。风格为现代产业咨询报告,白底,蓝绿橙紫多色搭配,干净、专业、可读性强,不要人物,不要复杂背景,适合博客首图。
图二提示词:
生成一张 16:9 横版中文信息图,主题为“AI-Ready 数据集能力栈”。用五层阶梯展示:数据供给、标注加工、质量测评、应用闭环、价值释放。每层配简短关键词,如行业通识、行业专识、多模态、专家标注、人机协同、一次测评全国互认、智能体落地、API 调用、数据资产化。风格为政府政策解读与产业研究结合的清爽图表,浅色背景,扁平化设计,文字清楚。
参考资料
-
国家数据局:《关于推进行业高质量数据集建设行动的实施方案》
https://www.nda.gov.cn/sjj/zwgk/tzgg/0608/20260608172117399715004_pc.html -
工业和信息化部办公厅、国家数据局综合司:《关于联合实施2026年“模数共振”行动的通知》
https://www.nda.gov.cn/sjj/zwgk/tzgg/0428/20260428215540161552208_pc.html