摘要:r/LocalLLaMA 上一位 OpenYabby 作者把原本依赖 Claude 的推理层换成单张 RTX 3090 上本地运行的 Qwen3.6-27B,并用 47 个多步骤编码工作流做了两周对比。结果显示,本地模型已经可以承担规划、记忆和部分审查,但工具调用、长上下文稳定性与执行安全仍需要系统闸门。

过去一年,多智能体系统的讨论常常围绕一个问题展开:真正昂贵的到底是“会说话的模型”,还是能够稳定规划、调用工具、审查结果并在失败后重规划的“推理层”?
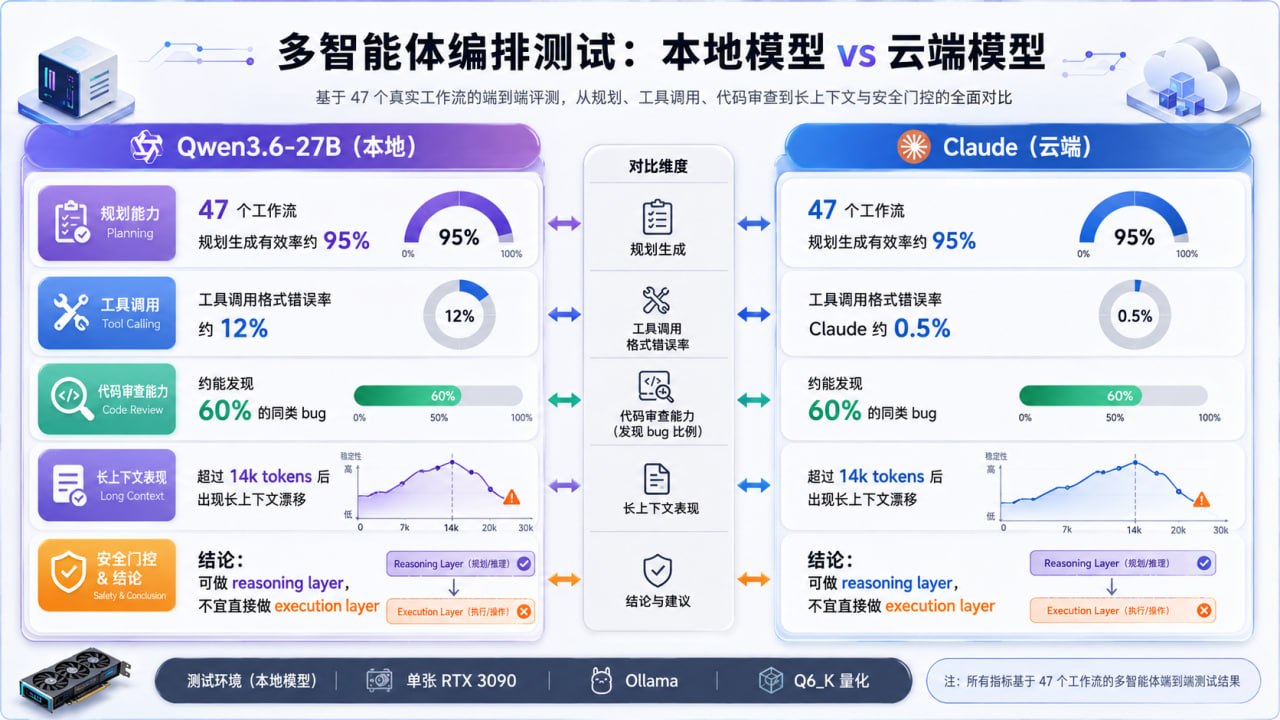
近日,r/LocalLLaMA 上一个来自 OpenYabby 作者的两周实测,为这个问题提供了一个很有价值的工程样本:他把 OpenYabby 中原本依赖 Claude 的推理层,替换成了本地运行的 Qwen3.6-27B,并在 47 个多步骤编码工作流中进行对比。测试环境是单张 RTX 3090 24GB,Qwen3.6-27B 使用 Q6_K 量化,约 22GB 驻留 GPU,通过 Ollama 运行,标称有效上下文约 32k tokens。(Reddit)
这个案例之所以值得关注,不是因为它证明“本地模型已经全面替代云端模型”,而是因为它把多智能体系统中的能力拆开了:规划、记忆、审查、工具调用、长上下文维持、失败恢复。结论也因此更细:Qwen3.6-27B 已经可以作为本地多智能体系统的“推理层”参与真实工作流,但还不适合作为不加防护的“执行层”。
OpenYabby 是什么:不是聊天机器人,而是执行系统
OpenYabby 官方将其描述为一个开源的 AI 助手和智能体编排系统。它可以把用户的语音或聊天请求转成结构化工作流,分配给多个协同智能体,调用工具,在本机执行任务,并在项目生命周期内维护上下文。其底层包括 OpenAI Realtime API、CLI task runners、层级式多智能体编排、Mem0 + Qdrant 持久记忆,以及连接器和 MCP 支持;默认 CLI runner 包含 Claude Code。(GitHub)
这意味着,OpenYabby 的核心难点不只是“生成一段代码”,而是让一个 lead/manager/sub-agent 架构持续运转:主管智能体要生成计划,经理智能体要分派任务,子智能体要执行,审查智能体要检查输出,系统还要在失败时重新规划。OpenYabby 官方文档中也强调了它的项目级编排、计划审批、任务执行、自动 review 和 QA 流程。(OpenYabby)
在这种架构里,模型的角色更像“调度大脑”而不是“问答接口”。如果它写错一个字段名、误解一个工具 schema,或者在子任务失败后继续假设任务已经成功,错误就会被后续智能体放大。这正是这次测试最有意思的地方:本地模型在“想清楚怎么做”上已经很接近,但在“可靠地把想法变成安全动作”上仍有明显缺口。
Qwen3.6-27B 为什么被选中
Qwen3.6-27B 是 Qwen 团队在 Qwen3.5 系列之后发布的首个 Qwen3.6 开源权重变体之一,模型卡称其重点面向稳定性、真实开发效用和 agentic coding。官方模型卡列出的语言模型参数规模为 27B,原生上下文长度为 262,144 tokens,并可扩展到约 1,010,000 tokens;Hugging Face 页面显示其许可证为 Apache-2.0。(Hugging Face)
从部署角度看,Qwen3.6-27B 也正好落在“消费级硬件可尝试”的边界上。GGUF 量化仓库中,Qwen3.6-27B 的 Q6_K 文件大小约 23.68GB,Q6_K_L 约 24.29GB,这解释了为什么单张 24GB RTX 3090 可以勉强承载这类测试,但也意味着运行时几乎没有太多余量留给长上下文 KV cache 和高吞吐推理。(Hugging Face)
官方模型卡建议,在生产或高吞吐场景下使用 SGLang、KTransformers 或 vLLM 等专门 serving 引擎,并指出 Qwen3.6 默认上下文长度为 262,144 tokens;如果遇到 OOM 可降低上下文窗口,但为了保留复杂任务中的 thinking 能力,建议至少维持 128K tokens。官方给出的 vLLM tool-call 示例还包含 --enable-auto-tool-choice 和 --tool-call-parser qwen3_coder。(Hugging Face)
这为后面的问题埋下了伏笔:Reddit 这次实测使用的是 Ollama、单卡 3090、Q6_K 量化和 32k 有效上下文。它测试的是一个非常实用、非常贴近个人开发者的配置,但并不是 Qwen3.6-27B 的最理想 serving 配置。
测试结果:计划像 Claude,工具调用不像
根据原帖,Qwen3.6-27B 在计划生成上表现相当强。经过几轮 prompt 调整后,结构化 JSON 计划的 schema 有效率约为 95%;剩下约 5% 的问题可以通过一次 re-prompt 修复。记忆抽取也基本可用:OpenYabby 每 6 轮进行一次类似 Mem0 的事实抽取,Qwen 能把用户偏好等信息抽出并写入 Qdrant。(Reddit)
更有意思的是 review 环节。作者让第二个 Qwen 实例审查第一个 Qwen 实例生成的代码,结果它大约能抓住 Claude 在同一组任务中发现 bug 的 60%。这不是“完全替代 Claude reviewer”的水平,但已经足以说明一个事实:本地模型不仅能当生成器,也能在多智能体链路里承担部分审查角色。(Reddit)
真正拉开差距的是工具调用。原帖称,在 47 个任务中,Qwen3.6 的 JSON tool-call 输出格式错误率约为 12%,而 Claude 在同一工作负载中的错误率约为 0.5%。这些错误并不主要是 JSON 语法坏掉,而是更危险的工程错误:字段名不对、类型不对、幻觉出不存在的工具签名。Outlines 或 strict-output mode 可以降低问题,但没有完全消除。(Reddit)
这正是 agent 系统里最昂贵的错误类型。聊天模型说错一句话,最多让用户困惑;执行型 agent 写错一个 tool call,可能会误改文件、误跑脚本、误删资源,或者让下游智能体基于错误状态继续推进。
长上下文漂移:标称上下文不等于可用上下文
原帖还记录了一个很典型的本地 agent 痛点:当累积 session context 超过约 14k tokens 后,Qwen 开始误记早先的决策,例如把用户明确说过的技术选择记反。作者给出的实践结论是,把可用上下文硬限制在约 12k tokens,然后进行激进的 summarization and reset。(Reddit)
这与 Qwen3.6 官方模型卡中的长上下文能力并不矛盾。官方写的是模型能力和推荐 serving 条件:原生 262k,上下文不足时可下调,但复杂任务建议至少 128K。Reddit 实测是在单张 3090、Ollama、Q6_K 量化、32k 有效上下文下完成的。换句话说,这个案例更像是在回答:“个人开发者用一张消费级卡跑本地多智能体系统,真实体验如何?”而不是在回答:“Qwen3.6-27B 在理想推理集群上能力上限如何?”(Hugging Face)
评论区也有人把问题指向上下文与 KV cache 配置,认为复杂 agent 使用至少应考虑更长、未量化或更稳的 KV cache;另一些评论则质疑 Ollama 在这类高要求 agent 场景下是否是最佳 runtime。无论是否完全同意这些判断,它们都指向同一个工程事实:本地模型替代云端模型,不只是换一个模型名,还涉及量化、上下文、runtime、tool parser、schema enforcement 和失败恢复机制。(Reddit)
最重要的结论:本地模型可以规划,但工具调用必须上闸门
原帖作者给出的核心判断很清楚:Qwen3.6-27B 今天已经可以作为本地多智能体系统的 reasoning layer,但还不适合作为 execution layer;更具体地说,可以让它生成计划,但每一个工具调用都必须经过 gate。作者建议的防护包括结构化输出强制、计划审批、以及模型自身之外的 re-plan-on-failure 逻辑。(Reddit)
这句话值得展开。所谓“reasoning layer”,是让模型负责拆任务、定顺序、提出假设、总结上下文、审查结果。所谓“execution layer”,则是把模型输出变成文件写入、命令执行、API 调用和跨工具自动化。前者可以容忍一定比例的修正;后者必须接近确定性。
因此,真正可落地的本地 agent 架构不应该是“把 Claude 换成 Qwen 然后直接跑”,而应该是:
- 让本地模型做计划生成,而不是直接执行敏感动作。
- 所有 tool call 都通过 schema 校验、类型校验、工具白名单和 dry-run。
- 写文件、跑 shell、调用外部 API 前设置 plan approval 或 human-in-the-loop。
- 子智能体失败后,由系统状态机触发 re-plan,而不是完全依赖模型自己发现失败。
- 上下文超过阈值后主动 summarize、checkpoint、reset,而不是等模型漂移。
- 单独记录 tool-call error rate,把它当作 agent 系统的核心指标,而不是只看代码 benchmark。
OpenYabby 自身也保留了计划审批流,并在限制说明中强调,自主执行在敏感任务上仍需要人的判断。这一点与这次测试结论是对齐的:多智能体系统可以越来越自动化,但不能把模型输出直接等同于可信动作。(GitHub)
这次测试真正说明了什么
这个案例最有价值的地方,不是“Qwen 输给 Claude”或“Qwen 接近 Claude”这种简单标签,而是它给了一个更细的替代路线图。
在计划生成上,Qwen3.6-27B 已经足够接近云端强模型,可以支撑真实 multi-step coding workflow。约 95% 的 schema-valid plan 说明,本地模型已经能够理解较复杂的项目分解逻辑。记忆抽取和二次 review 也说明,它可以在多智能体链路里承担不止一个角色。(Reddit)
但 12% 的工具调用格式错误率也说明,当前差距不在“会不会写计划”,而在“能不能稳定地把计划转换成正确、可执行、可验证的动作”。在 agent 系统里,这个差距比普通聊天场景更致命。作者认为,当这类本地模型的 tool-call error rate 能降到约 2% 时,云端推理在 agent loop 中的优势会迅速削弱。(Reddit)
这也是本地模型替代云端模型的现实路线:先替代高成本、低风险的推理和规划;再替代可校验、可回滚的执行;最后才是无人值守的端到端自动化。换句话说,本地模型的胜利不会以“完全无感替换 Claude”的形式到来,而会以一层层闸门、一套套校验器、一个个更可靠的 tool parser 逐步到来。
结语:本地 agent 的瓶颈,从智力变成可靠性
Qwen3.6-27B × OpenYabby 的两周实测,给本地多智能体系统打了一针强心剂:单张 3090 上的 27B 模型,已经能完成相当一部分规划、记忆和审查工作。它也给所有 agent 开发者提了醒:模型聪明不等于系统可靠,能生成计划不等于能安全执行。
未来本地 agent 能否真正替代云端推理,关键指标可能不是某个榜单分数,而是更工程化的几件事:工具调用错误率、长上下文稳定性、失败恢复能力、状态机设计、审计日志和回滚机制。
这次案例的最佳解读不是“Claude 已经可以被抛弃”,而是“Claude 不再是唯一可用的大脑”。本地模型已经能坐上规划席;但在它接管执行按钮之前,系统工程必须先把护栏装好。