摘要:深入剖析牛顿法及其拟牛顿变体(BFGS等)的历史渊源、数学原理与工程应用,揭示这一从17世纪延续至今的迭代思想如何成为现代优化理论和工程仿真的绝对底层驱动力。
影响人类的50个最重要算法系列:9/50
如果要选一个"最古老但至今仍在一线工作"的算法,牛顿法(Newton’s Method)几乎没有对手。
1669年,艾萨克·牛顿在一封私人信件中描述了这个方法的雏形。350多年后的今天,每当SpaceX的火箭引擎在飞行中实时调整推力、每当波音的工程师用有限元软件模拟机翼在极端载荷下的变形、每当你的手机GPS在毫秒内解算出你的精确位置——背后都在运行牛顿法或它的某个后代。
它的核心思想简单到令人难以置信:用直线(或曲面)来近似曲线(或曲面),然后解这个简单的近似问题,反复迭代直到收敛。
但正是这个简单思想,衍生出了现代优化理论中最强大的一族算法。
一、最原始的牛顿法:用切线找零点
牛顿法最初要解决的问题极其基本:给定一个函数f(x),找到使f(x) = 0的x值。
方法如下:
- 从一个初始猜测x₀开始
- 在点(x₀, f(x₀))处画函数的切线
- 这条切线与x轴的交点就是下一个猜测x₁
- 重复这个过程
用公式表达:
$$x_{n+1} = x_n - \frac{f(x_n)}{f’(x_n)}$$
几何直觉很清晰:如果函数在某一点附近"长得像"它的切线,那么切线的零点就是函数零点的一个好近似。每迭代一次,近似就更精确一些。
牛顿法最惊人的性质是它的二次收敛速度:一旦迭代值进入零点的"吸引域",每一步迭代都会让误差的有效数字翻倍。如果第n步有3位正确数字,第n+1步就有6位,第n+2步就有12位。
这意味着:从一个合理的初始猜测出发,通常只需要5-10次迭代就能达到机器精度(15-16位有效数字)。这种速度是线性收敛方法(如二分法)望尘莫及的。
二、从一维到多维:牛顿法解非线性方程组
一维求根只是开胃菜。牛顿法真正的威力在多维空间中展现。
考虑一个包含n个未知数、n个方程的非线性方程组 F(x) = 0,其中 F: ℝⁿ → ℝⁿ。多维牛顿法的迭代公式是:
$$x_{n+1} = x_n - J(x_n)^{-1} F(x_n)$$
其中 J(x) 是F的雅可比矩阵(Jacobian)——一个n×n的矩阵,第(i,j)个元素是 ∂Fᵢ/∂xⱼ。
实际计算中不会真的求逆矩阵(太贵了),而是解线性方程组 J(xₙ)·Δx = -F(xₙ),然后令 x_{n+1} = xₙ + Δx。
这就是为什么前面几篇讲的线性代数算法(Householder、QR分解等)如此重要——牛顿法的每一步迭代内部,都需要高效、稳定地求解一个线性方程组。
工程中的典型应用
有限元分析中的非线性问题:当材料发生塑性变形、大变形或接触时,平衡方程是非线性的。工程师用牛顿法(在有限元语境中叫Newton-Raphson方法)来迭代求解每个载荷步的平衡状态。
计算流体力学:Navier-Stokes方程的稳态解通常通过牛顿法求得。每一步需要组装和求解一个巨大的稀疏线性系统。
电路仿真:SPICE等电路仿真器用牛顿法求解包含数百万个非线性器件方程的电路平衡点。
三、从求根到优化:牛顿优化法
牛顿法的另一个重大应用是无约束优化:找到使目标函数f(x)最小的x。
优化问题的一阶必要条件是梯度为零:∇f(x) = 0。这本身就是一个方程组!所以可以直接用牛顿法来解。
把牛顿法应用于梯度方程,得到优化版本的迭代公式:
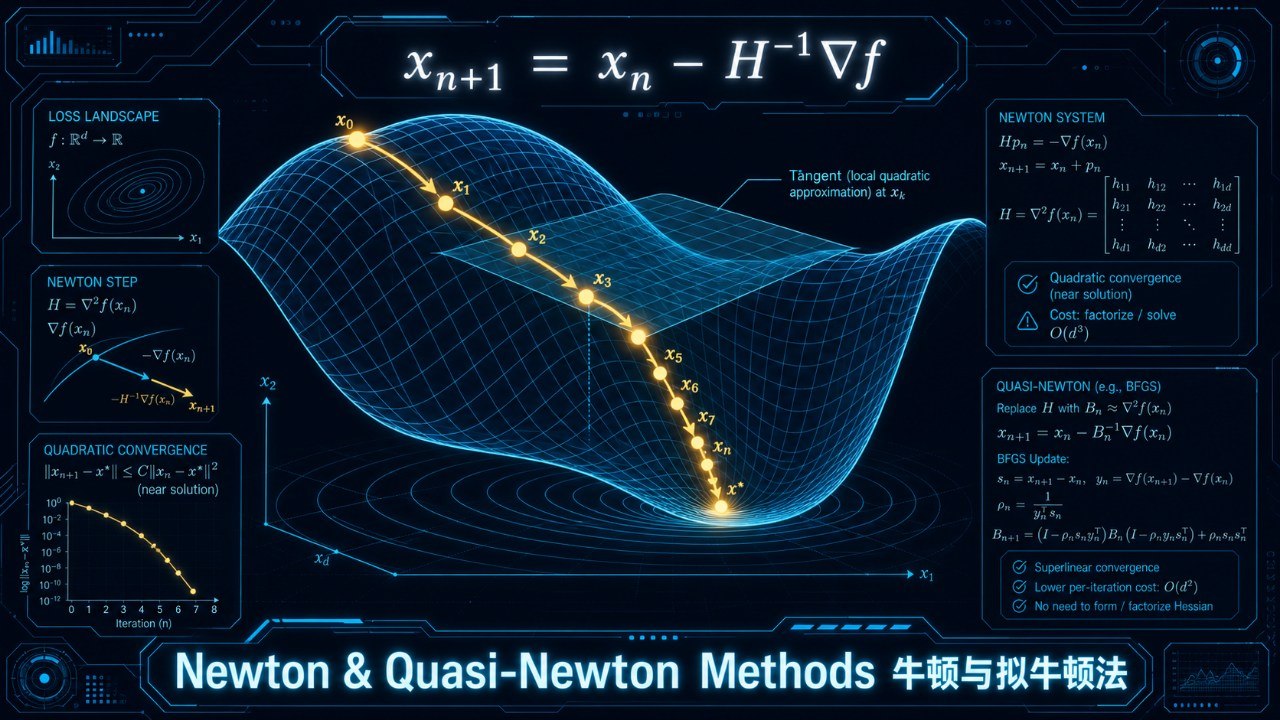
$$x_{n+1} = x_n - H(x_n)^{-1} \nabla f(x_n)$$
其中 H(x) 是海森矩阵(Hessian)——目标函数的二阶导数矩阵,第(i,j)个元素是 ∂²f/∂xᵢ∂xⱼ。
直觉上:梯度告诉你"下坡方向",海森矩阵告诉你"地形的曲率"。牛顿法综合这两个信息,不仅知道往哪走,还知道该走多远——它能"看到"山谷的形状,直接跳到谷底附近。
这就是为什么牛顿法比梯度下降快得多:梯度下降只用了一阶信息(方向),牛顿法用了二阶信息(方向+曲率)。在一个狭长的山谷中,梯度下降会来回震荡,而牛顿法一步就能切到谷底。
四、牛顿法的致命弱点
牛顿法虽然收敛极快,但有三个严重的实际问题:
第一,海森矩阵太贵。 对于n个变量的问题,海森矩阵有n²个元素,每个都需要计算二阶偏导数。当n = 10⁶(大规模优化问题中很常见)时,存储海森矩阵就需要8TB内存——这显然不现实。
第二,每步需要解线性方程组。 即使你有了海森矩阵,每步迭代还需要解一个n×n的线性系统,复杂度O(n³)。
第三,可能不收敛。 如果初始点离最优解太远,或者海森矩阵不正定(函数局部不是凸的),牛顿法可能发散或跑到鞍点。
这三个问题催生了一个庞大的算法家族:拟牛顿法(Quasi-Newton Methods)。
五、BFGS:拟牛顿法的王者
拟牛顿法的核心思想是:不精确计算海森矩阵,而是用梯度信息逐步"学习"它的近似。
1970年,四位数学家几乎同时独立提出了同一个算法:Broyden、Fletcher、Goldfarb、Shanno。这就是著名的BFGS算法。
BFGS的精妙之处在于:
- 维护一个海森矩阵的近似 Bₙ(或其逆的近似 Hₙ)
- 每步迭代后,利用新旧梯度的差值来更新这个近似
- 更新公式保证 Bₙ 始终是对称正定的(确保搜索方向总是下降方向)
- 只需要存储和更新一个n×n矩阵,不需要计算任何二阶导数
BFGS的收敛速度是超线性的——比梯度下降快得多,虽然不如纯牛顿法的二次收敛,但在实践中已经足够快,而且每步的计算代价低得多。
L-BFGS:大规模问题的救星
当n很大时(比如深度学习中的数百万参数),即使存储n×n的近似海森矩阵也不现实。
1980年,Jorge Nocedal提出了L-BFGS(Limited-memory BFGS):只存储最近m步(通常m = 5-20)的梯度差和步长信息,用这些信息隐式地表示海森近似。存储量从O(n²)降到O(mn),而收敛速度几乎不受影响。
L-BFGS至今仍是大规模无约束优化的首选算法之一。在机器学习出现深度学习之前的时代(2000-2012年),几乎所有的大规模机器学习模型(逻辑回归、CRF、最大熵模型)都用L-BFGS训练。
六、牛顿法家族的现代演化
信赖域方法(Trust Region)
为了解决牛顿法可能不收敛的问题,信赖域方法在每步迭代中限制步长不超过一个"信赖半径"。如果模型预测与实际下降吻合得好,就扩大信赖域;如果预测不准,就缩小。这让牛顿法在远离最优解时也能稳定收敛。
截断牛顿法(Truncated Newton)
对于超大规模问题,即使L-BFGS也可能不够。截断牛顿法的思路是:用共轭梯度法(CG)来近似求解牛顿方程 H·Δx = -∇f,但不求精确解——只迭代几步就停下来。这样每步的代价是O(n),同时保留了牛顿法的二阶信息优势。
高斯-牛顿法与Levenberg-Marquardt
在非线性最小二乘问题(如曲线拟合、计算机视觉中的BA优化)中,海森矩阵可以用雅可比矩阵的乘积 J^T J 来近似。这就是高斯-牛顿法。Levenberg-Marquardt算法在此基础上加入了阻尼项,兼具高斯-牛顿的快速收敛和梯度下降的全局稳定性。
七、为什么牛顿法350年不过时?
牛顿法的生命力来自一个深刻的数学事实:在最优解附近,几乎所有光滑的非线性问题都"长得像"二次函数。
二次函数的最小值可以一步精确求得(解线性方程组)。牛顿法本质上就是在每一步把非线性问题近似为二次问题来求解。只要你离最优解足够近,这个近似就足够好,收敛就是二次的。
这个性质不依赖于问题的具体形式——无论是流体力学方程、结构力学方程、电磁场方程还是优化问题,只要函数足够光滑,牛顿法就能以二次速度收敛。
这就是为什么,从1669年到2026年,从手工计算到超级计算机,牛顿法始终是非线性计算的终极武器。它的后代(BFGS、L-BFGS、信赖域、Levenberg-Marquardt)可能在细节上各有不同,但核心思想从未改变:用局部的线性(或二次)近似来征服全局的非线性。
📥 系列回顾: