摘要:深入剖析快速多极子方法(FMM)的历史渊源、数学原理及其在现代科学计算中的革命性影响,揭示这一被誉为"20世纪十大算法之一"的方法如何将多体相互作用的计算从O(N²)降至O(N)。
影响人类的50个最重要算法系列:7/50
想象你是一个天体物理学家,要模拟一个包含十亿颗恒星的星系演化。每颗恒星都在其他所有恒星的引力作用下运动。要计算某一时刻所有恒星受到的合力,你需要计算多少次引力?
答案是:N(N-1)/2 ≈ 5×10¹⁷次。即使用世界上最快的超级计算机,每秒执行10¹⁸次浮点运算,光算一个时间步的引力就要半秒钟。而一次有意义的模拟需要数百万个时间步。
这就是著名的N体问题(N-body problem):当粒子数量巨大时,两两之间的相互作用计算量以N²的速度爆炸增长,很快就超出任何计算机的能力。
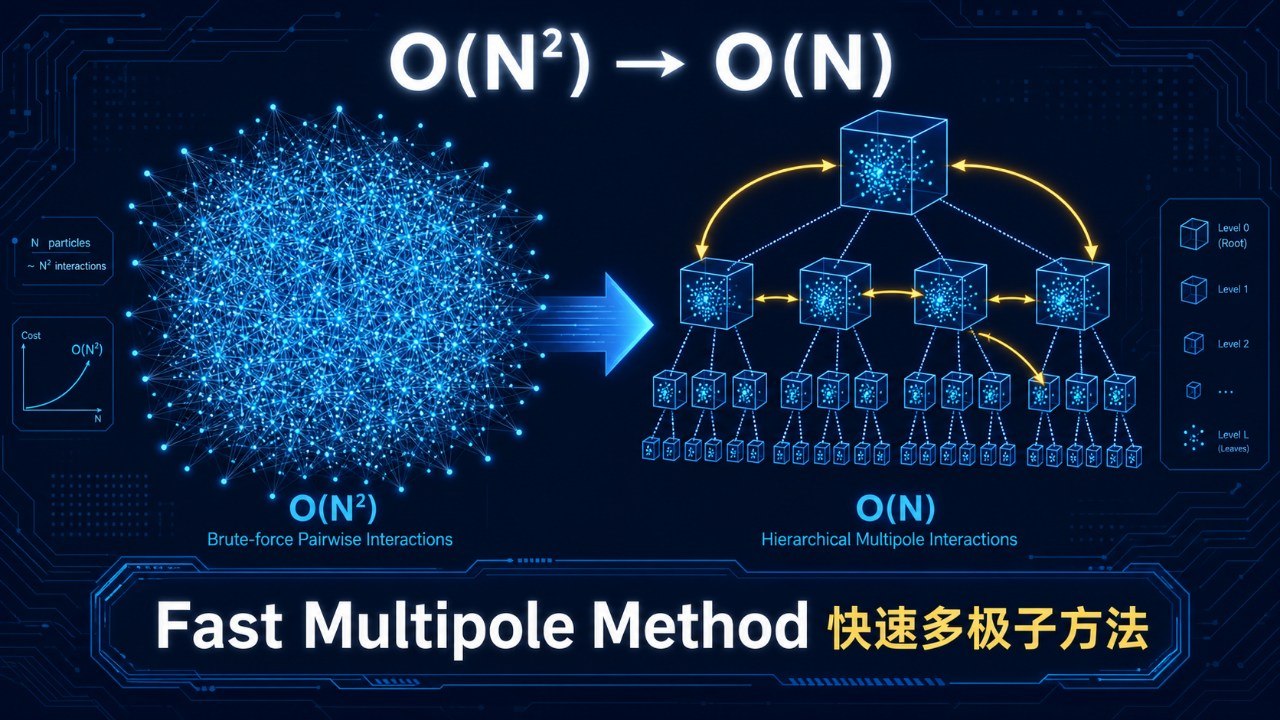
1987年,耶鲁大学的莱斯利·格林加德(Leslie Greengard)和弗拉基米尔·罗赫林(Vladimir Rokhlin)提出了快速多极子方法(Fast Multipole Method, FMM),一举将这个O(N²)的问题降到了O(N)。这不是常数倍的加速,而是复杂度级别的根本改变——粒子数翻倍,计算时间也只翻倍,而不是翻四倍。
一、N体问题:物理学中最古老的计算噩梦
N体问题的历史几乎和物理学一样古老。
牛顿在1687年发表《自然哲学的数学原理》时,就已经精确求解了两体问题(地球绕太阳的椭圆轨道)。但当他试图加入月球——变成三体问题时,就发现没有解析解了。据说牛顿曾抱怨,思考月球运动的问题"让他头疼"。
三体问题尚且如此,更别说真实的物理系统了:
- 天体物理:一个星系包含数千亿颗恒星,星系团包含数千个星系
- 分子动力学:一滴水包含约10²¹个分子,蛋白质折叠模拟涉及数百万原子
- 等离子体物理:核聚变反应堆中的等离子体包含数十亿带电粒子
- 流体力学:涡旋方法中每个涡旋粒子都与其他所有粒子相互作用
所有这些问题都有同一个数学结构:N个粒子,每对粒子之间有某种相互作用力(引力、库仑力、范德华力等),需要计算每个粒子受到的合力。
暴力计算的复杂度是O(N²)。当N = 10⁶时,需要10¹²次运算;当N = 10⁹时,需要10¹⁸次运算。这是一堵看似不可逾越的计算之墙。
二、Barnes-Hut树算法:FMM的前奏
在FMM之前,1986年Josh Barnes和Piet Hut提出了一个聪明的近似方法:树算法(Tree Code)。
核心思想很直观:当你计算某个粒子受到的引力时,远处的一大团粒子没必要逐个计算——你可以把它们"合并"成一个等效的质点,用这个质点的引力来近似整团粒子的合力。
具体做法是:把空间递归地分成越来越小的格子(四叉树或八叉树),每个格子记录其中所有粒子的总质量和质心位置。计算某个粒子的受力时,如果某个格子离它足够远(格子的角直径小于某个阈值θ),就直接用格子的质心来代替其中所有粒子。
Barnes-Hut算法把复杂度从O(N²)降到了O(N log N)。这已经是巨大的进步——对于N = 10⁶,从10¹²次运算降到了2×10⁷次。
但格林加德和罗赫林想要更多。他们问:能不能做到O(N)?
三、FMM的核心思想:多极展开与层级传递
FMM的天才之处在于,它不仅把远处的粒子"合并"成一个点,而是用**多极展开(Multipole Expansion)**来精确描述一团粒子产生的场。
什么是多极展开?
回忆一下高中物理:一个点电荷产生的电场是1/r²。但如果有一团电荷分布在某个区域内,它在远处产生的场可以用一系列"多极矩"来描述:
- 单极矩(Monopole):总电荷量——最粗略的近似,把整团电荷当成一个点
- 偶极矩(Dipole):电荷分布的"偏心程度"——第一级修正
- 四极矩(Quadrupole):电荷分布的"椭圆度"——第二级修正
- 更高阶矩:越来越精细的修正
保留的阶数越多,近似越精确。关键是:对于远处的观察点,只需要很少几阶就能达到机器精度。
FMM的层级结构
FMM把空间组织成一棵树(类似Barnes-Hut),但做了两件额外的事:
向上传递(Upward Pass):从最细的层级开始,计算每个格子中粒子的多极展开系数。然后把子格子的多极展开"合并"到父格子——这在数学上是多极展开的平移操作。一路向上,直到根节点拥有了整个系统的多极展开。
向下传递(Downward Pass):从根节点开始,把远场的多极展开"翻译"成每个格子内部的局部展开(Local Expansion)。局部展开描述的是"外部所有远处粒子在这个格子内产生的场"。一路向下,直到最细的层级,每个粒子都能从其所在格子的局部展开中直接读出远场的贡献。
近场直接计算:对于距离太近的粒子(在同一个格子或相邻格子中),多极展开不够精确,就直接暴力计算。但由于树结构的设计,每个粒子的"近邻"数量是O(1)的常数。
三步加起来,总复杂度就是O(N)。
四、为什么FMM能做到O(N)而Barnes-Hut只能O(N log N)?
关键区别在于粒子-粒子交互和格子-格子交互的处理方式。
Barnes-Hut算法中,每个粒子独立地遍历树结构,决定哪些格子可以用质心近似、哪些需要继续细分。每个粒子的遍历深度是O(log N),所以总复杂度是O(N log N)。
FMM则完全不同:它不是让每个粒子去"找"远处的格子,而是让格子之间直接"对话"。通过多极展开的层级传递,远场信息被系统地从粗到细地分发到每个格子。每个粒子只需要在最后一步从自己所在格子的局部展开中"读取"结果,不需要自己去遍历树。
这就像邮政系统:Barnes-Hut是每个人自己去全国各地取信,FMM是邮局系统帮你层层分拣、送到家门口。
五、精度控制:想要多精确就多精确
FMM的另一个优美之处是:精度完全可控。
多极展开保留的阶数p决定了近似精度。p越大,精度越高,但每次多极展开操作的计算量也越大(大约是p²或p³,取决于维度)。
在实践中:
- p = 5-10:单精度浮点精度(约6-7位有效数字)
- p = 15-20:双精度浮点精度(约15-16位有效数字)
- p = 30+:超越机器精度
这意味着FMM不是一个"近似算法"——在给定足够的展开阶数后,它的结果与暴力O(N²)计算的结果在机器精度内完全一致。它是一个精确算法的快速实现。
六、改变世界的应用
天体物理:模拟宇宙演化
FMM让天体物理学家能够模拟包含数十亿粒子的宇宙大尺度结构形成。著名的Millennium Simulation(千禧年模拟)使用了超过100亿个暗物质粒子来追踪宇宙从大爆炸到今天的演化历史。没有FMM(及其变体TreePM),这类模拟根本不可能实现。
分子动力学:药物设计的加速器
在计算生物学中,模拟蛋白质与药物分子的相互作用需要计算数百万原子之间的静电力。FMM让这些模拟从"需要数月"变成"数天"甚至"数小时"。这直接加速了新药研发的计算筛选过程。
电磁场计算:天线和芯片设计
计算复杂天线阵列或集成电路中的电磁场分布,本质上也是N体问题(电荷/电流之间的相互作用)。FMM让工程师能够精确模拟包含数百万未知量的电磁问题,这对5G天线设计和纳米级芯片验证至关重要。
流体力学:涡旋方法
在涡旋方法(Vortex Method)中,流体被离散化为大量涡旋粒子,每个粒子的速度由其他所有粒子的涡量决定。FMM让涡旋方法能够处理包含数百万涡旋粒子的复杂流动问题。
七、FMM的历史地位
2000年,美国工业与应用数学学会(SIAM)评选"20世纪十大算法",FMM名列其中——与FFT、蒙特卡洛方法、单纯形法等并列。
这个评价并不夸张。FMM解决的不是某一个具体问题,而是一整类问题的计算瓶颈。任何涉及长程相互作用(引力、库仑力、弹性力)的大规模模拟,都能从FMM中获益。
格林加德在2006年的一次演讲中说过一句话:“FMM的核心思想其实很简单——远处的东西可以用少量信息来描述。但把这个直觉变成一个严格的、可控精度的、O(N)复杂度的算法,需要非常仔细的数学工作。”
这句话也许是对FMM最好的总结:伟大的算法往往基于简单的直觉,但从直觉到实现之间的距离,就是科学的全部意义。
📥 系列回顾: