摘要:深入剖析自动微分(AD)的历史渊源、数学原理及其在现代科学计算与深度学习中的核心地位,揭示这一被长期低估的技术如何成为PyTorch、TensorFlow等框架的灵魂,以及整个AI革命的隐形基石。
影响人类的50个最重要算法系列:10/50
在上一篇中,我们讲了牛顿法如何用导数信息来加速优化。但有一个被刻意回避的问题:导数本身是怎么算出来的?
对于一个简单的函数 f(x) = x² + sin(x),你可以手动求导得到 f’(x) = 2x + cos(x)。但现实中的函数长什么样?
一个典型的深度学习模型有数十亿个参数,损失函数是这些参数经过数百层非线性变换后的复合结果。一个航空发动机的CFD仿真代码有几十万行,输出(推力)对输入(叶片几何参数)的导数隐藏在无数次循环、条件分支和数值积分之中。
对这些函数手动求导?不可能。数值差分?精度太差。符号微分?表达式会爆炸。
**自动微分(Automatic Differentiation, AD)**是第四条路——也是唯一真正可行的路。它能对任意计算机程序精确计算导数,精度达到机器精度,而且计算代价仅为原函数求值的常数倍。
没有自动微分,就没有现代深度学习。这不是夸张。
一、三种求导方式的对比
在理解自动微分之前,先看看它的两个"竞争对手"为什么不行。
数值微分(Finite Differences)
最直觉的方法:用差商近似导数。
$$f’(x) \approx \frac{f(x+h) - f(x)}{h}$$
问题在于h的选择是一个两难困境:
- h太大:截断误差大(差商不等于导数)
- h太小:舍入误差大(两个几乎相等的数相减,有效数字大量丢失)
最优的h大约是 √ε ≈ 10⁻⁸(ε是机器精度),此时能得到约8位有效数字的导数。听起来还行?但对于需要高精度导数的应用(如优化算法的收敛判断、灵敏度分析),8位远远不够。
更致命的是:对于n个变量的函数,计算完整梯度需要n+1次函数求值。当n = 10⁸(大模型参数量)时,这完全不可接受。
符号微分(Symbolic Differentiation)
让计算机像人一样,用求导法则(乘法法则、链式法则等)对数学表达式做符号运算。Mathematica和Maple就是这么做的。
问题是表达式膨胀。考虑一个简单的例子:
$$f(x) = (x + 1)(x + 2)(x + 3) \cdots (x + n)$$
对x求导后,用乘法法则展开会得到n项,每项都是n-1个因子的乘积。如果再对结果求二阶导数,表达式会进一步爆炸。
对于真实的工程代码(包含循环、条件分支、子程序调用),符号微分根本无法处理——它需要一个封闭的数学表达式作为输入,而不是一段程序。
自动微分:第三条路
自动微分既不近似(像数值微分),也不操作符号表达式(像符号微分)。它的核心洞察是:
任何计算机程序,不管多复杂,都是由有限个基本运算(加减乘除、sin、cos、exp、log等)组合而成的。每个基本运算的导数是已知的。通过链式法则把这些基本导数组合起来,就能精确计算整个程序的导数。
关键词是"精确"——自动微分的结果在机器精度内与解析导数完全一致,没有任何近似误差。
二、前向模式:跟着计算走
自动微分有两种模式。先看比较直觉的前向模式(Forward Mode)。
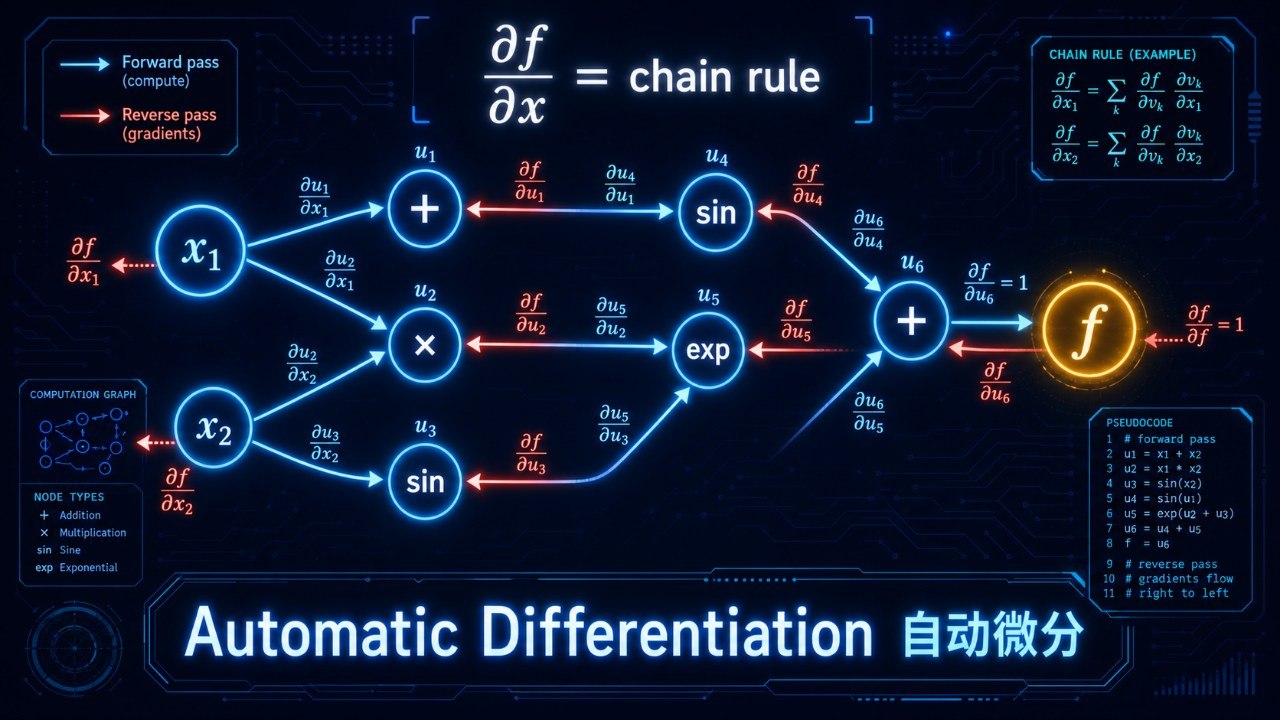
考虑函数 f(x₁, x₂) = x₁·x₂ + sin(x₁),要计算 ∂f/∂x₁。
前向模式的做法是:在计算f的值的同时,"顺便"计算每个中间变量对x₁的导数。
1 | 计算过程: 导数传播: |
每个中间变量都携带一个"导数伴侣"(叫做切线向量或对偶数),随着计算一步步向前传播。
前向模式的代价:计算一个方向导数(∂f/∂xᵢ)的代价约等于一次函数求值。要计算完整梯度(所有n个偏导数),需要n次前向传播。
所以前向模式适合:输入少、输出多的情况(n小,m大)。
三、反向模式:从结果倒推原因
现在考虑深度学习的典型场景:n = 10⁸个参数,但只有1个标量输出(损失函数值)。用前向模式需要10⁸次传播——不可接受。
**反向模式(Reverse Mode)**解决了这个问题。它的思路是:先正向计算函数值(记录所有中间变量),然后从输出开始,反向传播导数。
还是同一个例子 f(x₁, x₂) = x₁·x₂ + sin(x₁):
1 | 正向计算(记录计算图): |
一次反向传播就同时得到了 ∂f/∂x₁ 和 ∂f/∂x₂!
反向模式的代价:计算完整梯度(所有n个偏导数)的代价约等于一次函数求值的3-5倍,与n无关。
这就是为什么反向模式是深度学习的命脉:不管模型有多少参数,计算损失函数对所有参数的梯度只需要常数倍的额外代价。
四、反向传播 = 反向模式自动微分
如果你学过深度学习,你一定知道"反向传播算法(Backpropagation)"。
事实上,反向传播就是反向模式自动微分在神经网络计算图上的特例。它不是一个独立的发明,而是AD的一个应用。
历史上,这两个社区长期互不知晓:
- 1964年,Robert Wengert发表了自动微分的基本思想
- 1970年,Seppo Linnainmaa在硕士论文中描述了反向模式
- 1986年,Rumelhart、Hinton和Williams发表了反向传播在神经网络中的应用
直到2000年代,深度学习社区才逐渐意识到"反向传播"和"反向模式AD"是同一件事。这个认识的统一直接催生了现代深度学习框架的设计哲学:不要为神经网络专门写反向传播代码,而是实现通用的自动微分引擎,让任何可微计算都能自动求导。
PyTorch的autograd、TensorFlow的GradientTape、JAX的grad——这些都是通用自动微分引擎,不是"神经网络专用反向传播器"。
五、实现方式:运算符重载 vs 源代码变换
自动微分有两种主要的实现策略:
运算符重载(Operator Overloading)
在支持运算符重载的语言(C++、Python)中,定义一种新的"对偶数"类型,重载所有基本运算符(+、-、*、/、sin、cos等),让它们在计算值的同时自动计算导数。
优点:对用户代码的侵入性最小,几乎不需要修改原始程序。
缺点:运行时开销较大(每次运算都有额外的对象创建和方法调用)。
PyTorch就是这种方式:你用普通的Python/NumPy风格写前向计算,PyTorch在背后自动构建计算图并记录所有操作。
源代码变换(Source Code Transformation)
直接分析源代码,生成一个新的程序来计算导数。
优点:生成的导数代码可以被编译器深度优化,运行效率极高。
缺点:实现复杂,需要处理语言的所有特性(循环、条件、递归等)。
Fortran领域的Tapenade、C/C++领域的ADIC,以及新兴的JAX(通过tracing实现类似效果)都属于这一类。
六、超越深度学习:AD在科学计算中的应用
自动微分的价值远不止训练神经网络。
气象预报中的伴随方法
现代数值天气预报使用"四维变分同化"(4D-Var)来融合观测数据和模型预测。这需要计算气象模型(数百万行Fortran代码)的伴随(adjoint)——本质上就是反向模式AD。欧洲中期天气预报中心(ECMWF)的IFS模型就依赖AD工具生成的伴随代码。
航空航天中的形状优化
设计最优的机翼形状需要计算气动性能(升力、阻力)对几何参数的灵敏度。通过对CFD求解器做AD,工程师可以高效地计算这些灵敏度,驱动梯度优化算法找到最优形状。
计算金融中的风险度量
金融衍生品的定价模型(如蒙特卡洛模拟)需要计算价格对市场参数的敏感度(Greeks:Delta、Gamma、Vega等)。AD比数值差分快几个数量级,且精度更高。
机器人学中的运动规划
机器人的逆运动学和轨迹优化需要计算关节角度对末端执行器位置的雅可比矩阵。AD让这些计算变得自动且精确。
七、AD的深层意义:可微编程
自动微分正在催生一个更大的范式转变:可微编程(Differentiable Programming)。
传统编程中,程序是"写死"的逻辑。可微编程的理念是:让整个程序(包括物理模拟器、渲染器、控制器)都变成可微的,然后用梯度优化来"学习"程序中的参数。
例如:
- 可微物理引擎:让机器人在模拟环境中学习控制策略,梯度直接从物理模拟器反向传播到控制参数
- 可微渲染器:从2D图像反推3D场景参数,梯度通过渲染过程反向传播
- 可微科学模拟:把神经网络嵌入偏微分方程求解器中,用观测数据端到端地训练整个系统
Yann LeCun在2018年说:“深度学习只是可微编程的一个子集。未来,我们会把所有东西都变成可微的。”
这个愿景的实现,完全依赖于自动微分技术的成熟。
八、从1964到2026:一个被低估了50年的算法
自动微分的历史充满了"被忽视"的遗憾。
1964年Wengert发表论文时,计算机科学还在襁褓中。1970年Linnainmaa描述反向模式时,没有人意识到它的重要性。整个1970-2000年代,AD主要在科学计算的小圈子里流传,被主流计算机科学忽视。
直到深度学习的爆发,人们才突然意识到:这个50年前就存在的技术,竟然是整个AI革命的数学基础。
今天,自动微分已经从一个小众的数值分析技巧,变成了计算科学中最核心的基础设施之一。它连接了数值分析、优化理论、机器学习和科学计算,是这些领域的公共语言。
正如一位AD研究者所说:“微积分的链式法则是300年前的数学。但把它系统地、高效地、自动地应用于任意计算机程序——这是一个深刻的算法洞察,它的全部潜力我们才刚刚开始挖掘。”
📥 系列回顾: