摘要:Cartesian 把算法教材做成了可执行、可回放、可交互的学习软件。本文拆解其技术路线,并进一步讨论:这种模式是否适合数值分析与科学计算类教科书写作?答案是,极其适合,而且可能比数据结构教材更有潜力。
最近看到一个很有意思的项目:Cartesian。
上面这段演示视频其实比静态截图更有说服力。你会很直观地看到它不是普通电子书,而是一套把正文、可视化、代码回放和练习环境揉在一起的学习软件。
它表面上是一套数据结构与算法教材,但如果仔细看,你会发现它真正做的事情不是“把书电子化”,而是把教材改造成了一种 可执行、可交互、可回放、可练习的软件产品。
这是一个很重要的方向。因为它指向的不只是“算法怎么教”,而是一个更大的问题:如果今天重新写一遍数值分析、科学计算这类教材,最合理的形态还会是 PDF、Word、LaTeX 导出的静态书吗?
我越来越觉得,答案可能是否定的。
Cartesian 到底在做什么?
从官网信息和作者在 Reddit 上的介绍看,Cartesian 的核心特征包括:
- 670+ 交互页面
- 22 章完整内容
- 300+ 可视化模块
- 250+ 可交互代码片段
- 100+ 已解题目
- 内嵌 Python 环境
- 代码执行回放(暂停、快进、回退、单步)
- 可自定义输入
- 离线可用
- 无订阅、无追踪、无 DRM
这说明它不是“电子书 + 一些动画”,而是一个典型的 interactive computational textbook,也就是“交互式计算教材”。
它把传统教材中的四个原本分散的部分重新合并了:
- 正文讲解
- 算法过程可视化
- 可执行代码环境
- 练习与反馈系统
这四件事以前通常分布在不同地方:书里讲理论,博客放动图,IDE 跑代码,OJ 平台做题。Cartesian 的价值在于,它把这些环节压缩进了同一个学习空间里。
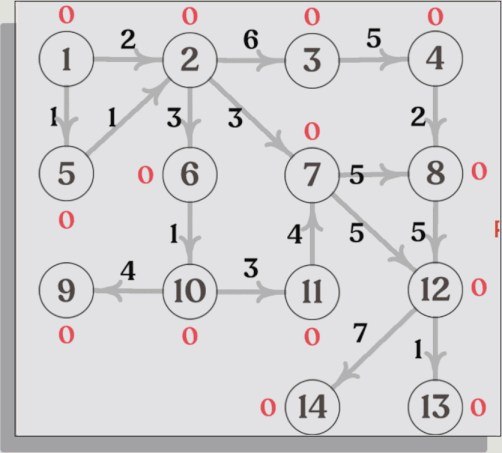
上面这类图结构可视化非常能说明它的产品思路:不是给你一个静态图,而是把算法执行中的节点状态、边权、路径变化实时暴露出来,让“图论过程”变成一种可观察对象。
我理解的技术路线
Cartesian 没有公开完整架构,但从产品形态基本能反推出它大致采用了下面这条技术路线。
1. 内容层:结构化文档 + 交互组件系统
它的内容显然不是普通 Markdown 加几张图这么简单。更像是:
- 章节正文由结构化内容描述
- 文档中可以插入各种自定义组件
- 组件包括:可视化器、代码块、回放器、输入面板、练习器、复杂度分析卡片等
也就是说,它的底层更像是:
文档 AST + 自定义交互组件框架
这和普通博客、普通电子书的最大区别在于:内容本身不是最终展示结果,而是一个“可编排的交互场景”。
2. 可视化层:算法状态机驱动,而不是简单动画
Cartesian 最关键的技术点,不是会画图,而是把算法执行过程拆成了一系列状态。
以排序算法为例,它不是放一段事先做好的演示动画,而是动态生成一条状态轨迹:
- 当前数组排列
- 比较了哪两个元素
- 哪一步发生交换
- 哪部分已局部有序
- 当前指针位置在哪里
这说明其可视化系统更可能是:
算法执行 trace → 渲染引擎
也就是先记录每一步的状态,再由前端播放器去渲染。这样才能支持:
- 暂停
- 单步执行
- 回退
- 自定义输入后重新生成过程
这套思路对算法书有效,对数值分析其实更重要,因为数值方法的学习高度依赖“过程感”。
3. 代码回放层:解释执行或插桩执行
官网特别强调“你可以看到变量如何随着代码执行实时变化”。
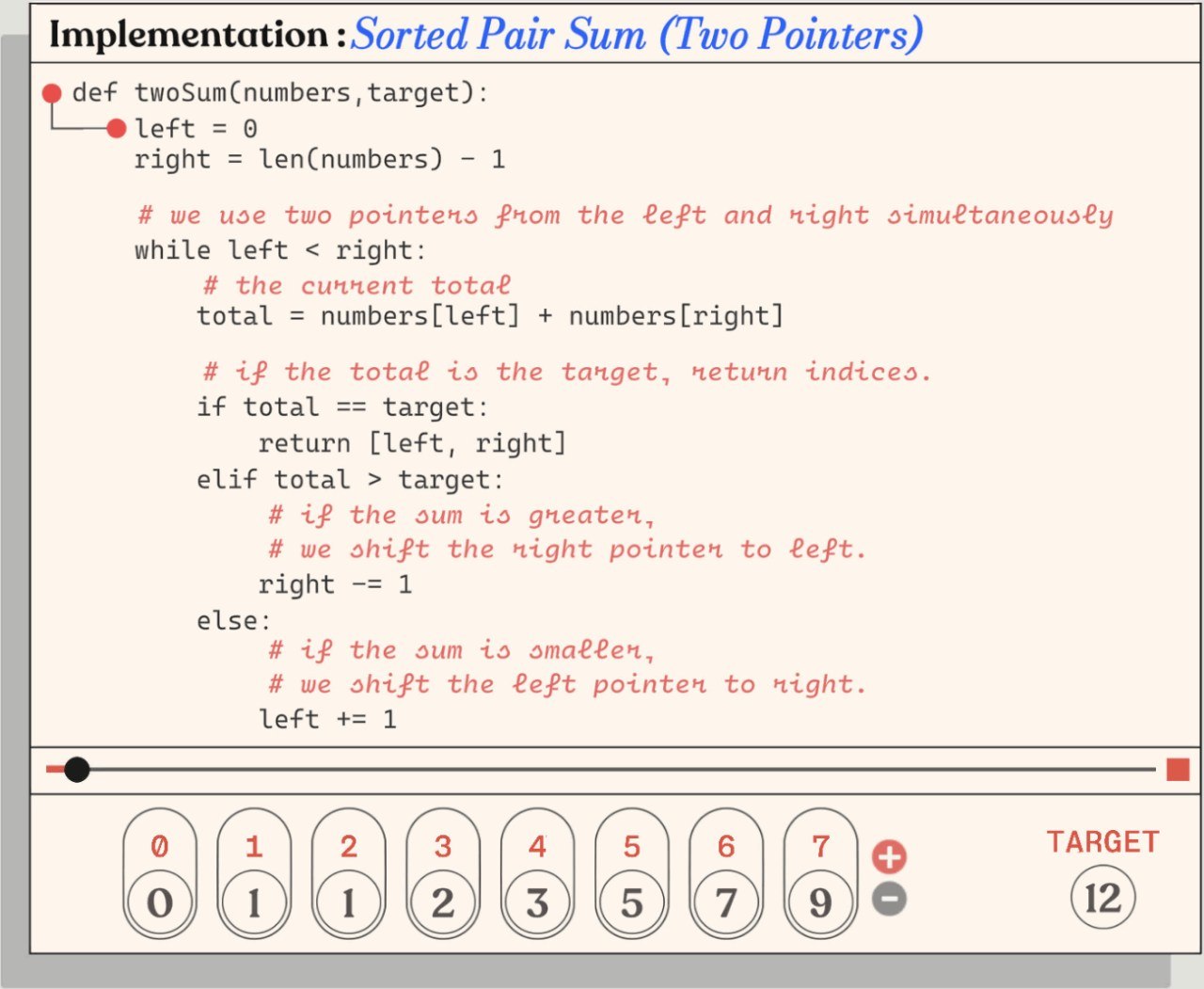
这个界面很关键,它说明 Cartesian 做的不是“把代码贴上去”,而是把代码、输入、执行进度、算法状态绑定成一个统一播放器。用户既能看 two pointers 的逻辑,也能同步观察数组区间如何收缩。
要做到这一点,通常有两种办法:
路线 A:解释器/沙箱执行
把 Python 代码放进受控环境中运行,同时截获变量状态。
路线 B:代码插桩
在代码执行前自动插入 trace 记录逻辑,例如记录:
- 当前执行到哪一行
- 当前局部变量值
- 容器如何变化
- 递归栈如何展开
如果还要支持 rewind,基本就需要走 trace-first 的思路,也就是先把整个执行过程离散化成可播放的状态序列。
4. 计算环境:嵌入式 Python
Cartesian 内置 Python 环境,这一点很关键。
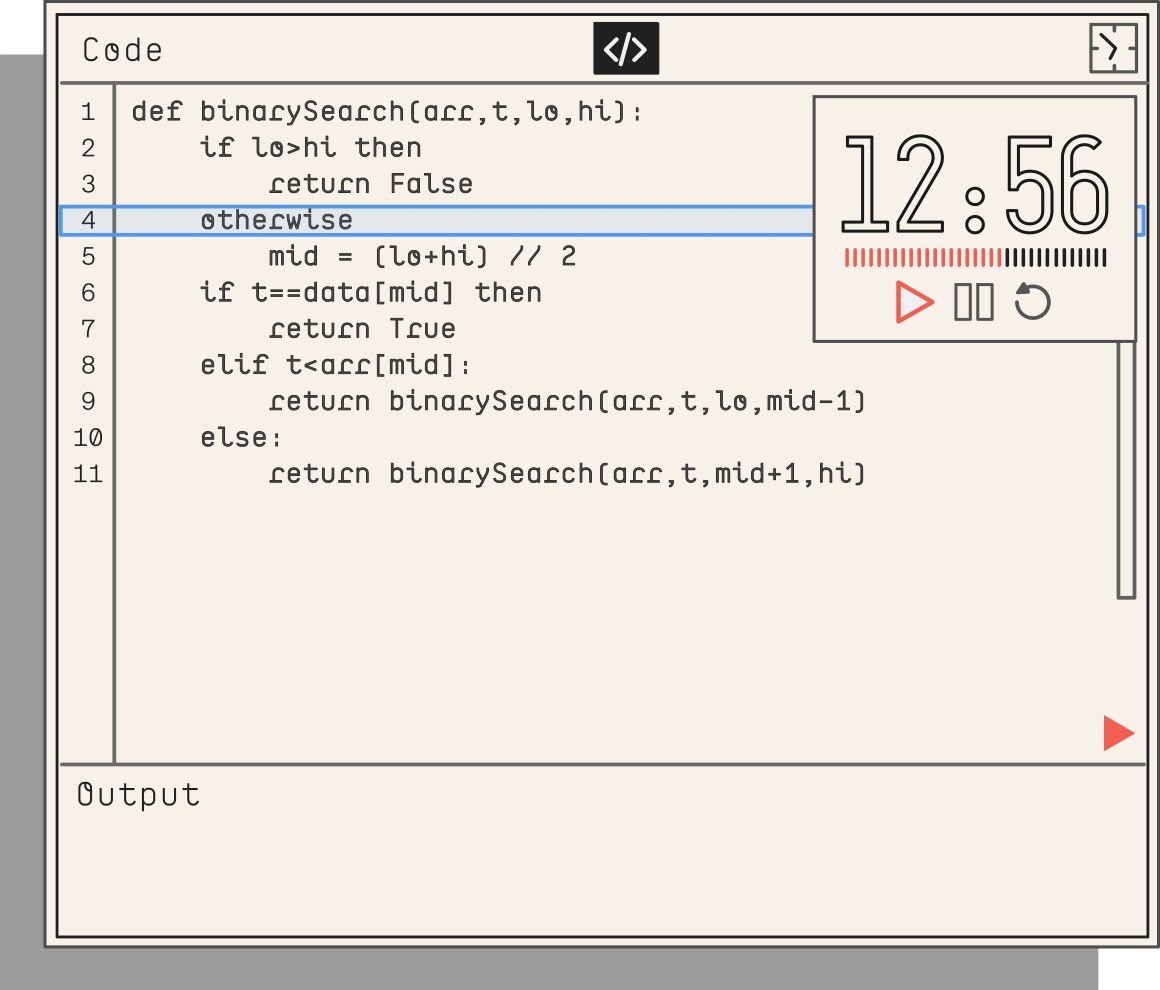
从这个代码界面也能看出,它并不是普通的代码高亮块,而是一个带时间控制、步骤播放和输出区域的轻量执行器。这意味着它背后一定有某种 trace 机制或者受控解释执行环境。
这意味着它不是只讲伪代码,而是让用户真正去运行、修改和测试代码。考虑到它强调离线可用,我更倾向于它采用的是本地优先的计算方式,比如:
- Pyodide / WebAssembly Python
- 打包应用内嵌 Python runtime
- 本地解释器 + 资源一起分发
这也是它和普通网页教程最大的差异之一:它像软件,不像网站。
5. 习题系统:内嵌判题 + 解法可视化
Cartesian 的练习不是简单问答,而是:
- 题目描述
- 用户写代码
- 内嵌执行
- 测试用例验证
- 多解法展示
- 每个解法还能继续配可视化
这本质上是把一个轻量级在线 judge 嵌进了教材里。
从教学设计上看,这非常聪明。因为它把“学”和“练”之间的切换成本降到了极低。
为什么这种模式特别适合算法书?
因为算法学习天然依赖四件事:
- 过程
- 状态变化
- 输入改变后的行为差异
- 自己动手试错
普通教材能讲清“是什么”,但很难让你真正理解“它怎么动起来”。Cartesian 恰好抓住了这一点。
所以它在数据结构与算法上成立,是完全合理的。
但更有意思的问题是:如果把同样的思路迁移到数值分析、科学计算类教科书,会发生什么?
我的判断:这种方式对数值分析、科学计算甚至更有潜力
结论先说:
非常适合,而且某些地方比算法教材更适合。
原因很简单。数据结构与算法依赖“状态变化”,而数值分析与科学计算依赖的不只是状态变化,更依赖:
- 误差传播
- 收敛过程
- 参数敏感性
- 几何直觉
- 实验现象
这些内容天生就是交互式表达的强项。
1. 迭代法极其适合交互教材
比如:
- 牛顿法
- 割线法
- Jacobi / Gauss-Seidel
- 共轭梯度法
- 不动点迭代
如果放在静态教材里,通常只能给几张示意图和几列数表。
但如果放在 Cartesian 式系统里,就可以变成:
- 初值滑块
- 迭代轨迹动画
- 收敛/发散对比
- 残差曲线实时更新
- 参数变化引起的收敛速度变化
这会把“抽象方法”直接变成“可观察现象”。
2. 数值误差与稳定性,几乎就是为交互教材而生的
传统数值分析最难讲清楚的往往是这些:
- 舍入误差
- 消去误差
- 条件数
- 病态问题
- 稳定算法与不稳定算法的差异
这些内容在静态书里通常需要靠作者的语言功底硬撑。但在交互教材里,它们可以直接被“看见”:
- 同一个问题切换不同浮点精度
- 输入改动 10⁻⁸,看输出怎么爆炸
- 比较正规方程、QR、SVD 在病态问题上的表现差异
- 动态展示误差如何随迭代传播
这对理解会是质变,不是量变。
3. 线性代数算法的几何直觉能被真正释放
比如:
- Householder 反射
- QR 分解
- SVD
- 幂法
- Krylov 子空间
这些内容如果只有公式,很多学生会学得非常痛苦。但如果能把变换过程做成交互:
- 向量如何被反射
- 矩阵如何逐步三角化
- 奇异值对应哪些拉伸方向
- 特征值迭代如何收敛
那理解速度会快很多。
4. ODE / PDE / 有限元 / CFD 的离散化过程,也很适合
例如:
- 欧拉法 vs Runge-Kutta
- 时间步长变化
- 网格剖分变化
- CFL 条件
- 热方程离散
- 有限差分模板
- 有限元网格和形函数
这些内容如果做成交互实验,学习者可以直接调参数看结果:
- 步长变大后稳定性怎么崩
- 网格变细后误差怎么下降
- 边界条件改变后解场如何变化
- 显式法和隐式法的差异如何可视化
这正是科学计算教材最缺的一层。
但不是所有内容都适合这样写
需要说清楚,这种模式也不是万能的。
不那么适合的部分包括:
- 长篇收敛性证明
- 谱理论的大段严格推导
- 泛函分析背景
- PDE 存在唯一性证明
- 高度抽象的算子理论
这些内容的核心是严密逻辑链,而不是动态过程。交互可以辅助,但不应该喧宾夺主。
所以更合理的方式不是“把整本书全改成交互”,而是把书拆成三层:
- 正文层:概念、定理、推导、证明
- 实验层:算法过程、误差、参数、几何直觉
- 执行层:代码、sandbox、练习、可回放 trace
我觉得这才是数值分析和科学计算教材真正理想的形态。
对科学计算教材写作意味着什么?
如果采用 Cartesian 这种思路,作者的角色会发生变化。
他不再只是“写书的人”,而更像:
- 内容作者
- 教学设计师
- 交互产品设计者
- 实验策展人
- 计算环境编排者
这比写一本文字教材难得多,但一旦做出来,护城河也高得多。
因为用户买到的不再只是知识文本,而是:
内容 + 交互 + 计算实验 + 可执行环境
这不是一份 PDF 能替代的。
一个更现实的推进方式
如果今天就要把这套思路用在科学计算内容上,我反而不建议一上来就做一个完整的 Cartesian。
更现实的路线是:
第一步:文章 + 独立交互 demo
比如:
- 牛顿法:调初值看收敛
- Householder:拖动向量看反射
- QR:看矩阵如何逐步上三角化
- 共轭梯度:看残差和搜索方向变化
第二步:把 demo 组织成专题手册
等积累够 20-30 个交互模块,再进一步组织为:
- 交互式数值分析手册
- 交互式科学计算算法图谱
- 面向工程师的计算实验教材
这个路线比直接造一个巨系统更稳,也更容易形成可持续更新的内容资产。
我的最终判断
Cartesian 做对的一点,不是它把教材做得更炫,而是它抓住了下一代技术教材真正该有的三件事:
- 算法可执行
- 过程可观察
- 知识可实验
如果把这套思路迁移到数值分析和科学计算,我认为它的潜力甚至比算法书更大。
因为数值分析从来就不是一门只靠“读懂定义”就能学会的学科,它本质上是一门实验科学。既然如此,最合理的教材形态,本来就不该只是静态书页。
也许未来真正优秀的科学计算教材,不再是一本书,而是一套能运行、能调参、能观察、能试错的计算学习系统。
Cartesian 让我更确信,这条路是对的。