摘要:哈佛医学院发表于《Science》的一项研究显示,推理型大模型在急诊分诊等临床任务中部分表现已超过人类医生,尤其在信息最少、决策最紧迫的早期阶段更具优势。这并不意味着AI将取代医生,但它很可能正在重新定义医疗系统中的第二意见、漏诊提醒和临床推理辅助。

急诊室一直是现代医学里最紧张的地方之一。
病人被推进来时,医生往往没有完整病史,没有充足检查结果,甚至来不及做系统问诊。眼前只有零碎线索,生命体征、护士记录、少量既往病历,以及病人当下的症状描述。可就是在这种信息极不充分的时刻,医生必须迅速判断,哪些情况危险,哪些方向最值得优先排查,哪些误判可能直接决定生死。
也正因为如此,急诊分诊和初步诊断,长期被视为最难被自动化取代的医学工作之一。
但最近,一项来自哈佛医学院和贝斯以色列女执事医疗中心的研究,给这个判断打上了一个巨大的问号。根据《卫报》报道和哈佛方面的公开介绍,这项发表于《Science》的研究发现,OpenAI 的推理模型 o1 在急诊分诊等多个临床推理任务上,表现出与人类资深医生相当,甚至在部分环节更优的结果。
如果这个结论放在五年前,听起来几乎像科幻。可现在,它已经开始变成一类必须认真讨论的现实问题。
这项研究到底测了什么?
这篇新闻最容易被简化成一句刺激眼球的话,AI诊断胜过医生。但如果只停在这句,几乎一定会误解研究本身。
按照报道,这项研究并不是让 AI 直接坐进急诊室面对真实病人,也不是让它替代医生独立做决定。研究测试的,是 AI 在文本化临床信息上的推理能力。
其中一个最受关注的实验,选取了波士顿一家医院急诊室的 76 个真实病例。研究者把病人到院时的标准电子病历信息交给 AI 和两位人类医生,信息包括生命体征、人口学信息,以及护士对患者来院原因的简短描述。然后再由另外两位不知道答案来源的医生进行盲评,判断诊断质量。
结果是,o1 模型在初始分诊阶段给出“完全正确或非常接近正确”的诊断比例达到 67%,而两位人类医生分别约为 55% 和 50%。在后续信息更多的阶段,AI 的准确率还会上升到 82%,人类专家则大约在 70% 到 79% 之间。
这已经很惊人了。但更重要的是,研究者特别指出,AI 的优势在最早期、信息最少、时间最紧迫的分诊阶段尤其明显。
换句话说,它最擅长的,不是拿着一大堆检查结果慢慢分析,而是在一团混乱的信息里,快速提出更靠谱的方向判断。这正是急诊最吃重的能力之一。
为什么这件事这么重要?
因为医疗里的很多严重错误,并不是出在最后的治疗手术,而是出在最开始的判断路径上。
急诊里最可怕的,不一定是完全不会诊断,而是过早锁定错误方向。一旦医生在最初阶段把注意力放错地方,后续的检查、用药和资源调度都会跟着偏离,最终造成延误。
报道里提到一个典型案例,一名肺部血栓患者病情恶化,人类医生最先怀疑是抗凝药失效,但 AI 从病史里注意到患者有红斑狼疮背景,因此提出肺部炎症也可能与此相关。最后,AI 的方向被证明更接近正确答案。
这类案例最有启发性的地方,不是 AI 更聪明,而是它在文本信息里更不容易被某个直觉过早锁死。
临床医生当然有经验优势,但经验同时也会带来一种认知风险。在高压场景中,人脑会快速调用熟悉模式,这有助于效率,却也可能造成“看见第一个像的答案,就先按那个走”。而大模型的长处恰恰在于,它能够在大量文本线索中同时维持多个可能解释,不那么容易因为第一印象过早收缩搜索空间。
这意味着,AI 在医学里的第一波真正价值,可能不是替代医生,而是成为一种防止漏诊、误诊和思维过早收敛的第二意见系统。
但别急着喊“医生要失业了”
这正是这类新闻最容易跑偏的地方。
首先,这项研究测试的核心仍然是文本推理。也就是说,AI 看到的是电子病历、生命体征和文字描述,而不是病人的神情、呼吸状态、肤色变化、肢体动作、疼痛反应,也不是 X 光片、CT 影像、心电图、床旁超声和各种现场感知。
可现实中的急诊,恰恰是一门高度依赖非文本信息的工作。
一个病人是不是“看起来就不对劲”,一个老人说话是不是已经虚弱到不成句,一个胸痛患者坐姿和出汗状态是否提示危险,这些都不是目前文字输入能完整承载的。换句话说,这项研究证明的是,AI 在“读病历并推理”这件事上非常强,但没有证明它已经具备完整临床能力。
其次,研究中对照的人类医生也引发了一个重要讨论。TechCrunch 引述急诊医生 Kristen Panthagani 的观点指出,这项研究拿来比较的并不是急诊专科医生,而是内科主治医生。这个差异不能忽略,因为急诊的首要任务未必是一步猜中最终病名,而是优先识别那些“可能马上致命”的情况。
这是一种很不同的临床思维。
所以,更准确的说法不是“AI 已经全面胜过急诊医生”,而是,在标准化文本信息上的早期诊断推理任务中,推理型大模型已经展现出非常强的竞争力。这仍然是重大进展,但和全面替代不是一回事。
真正值得重视的,是医疗工作流会因此改变
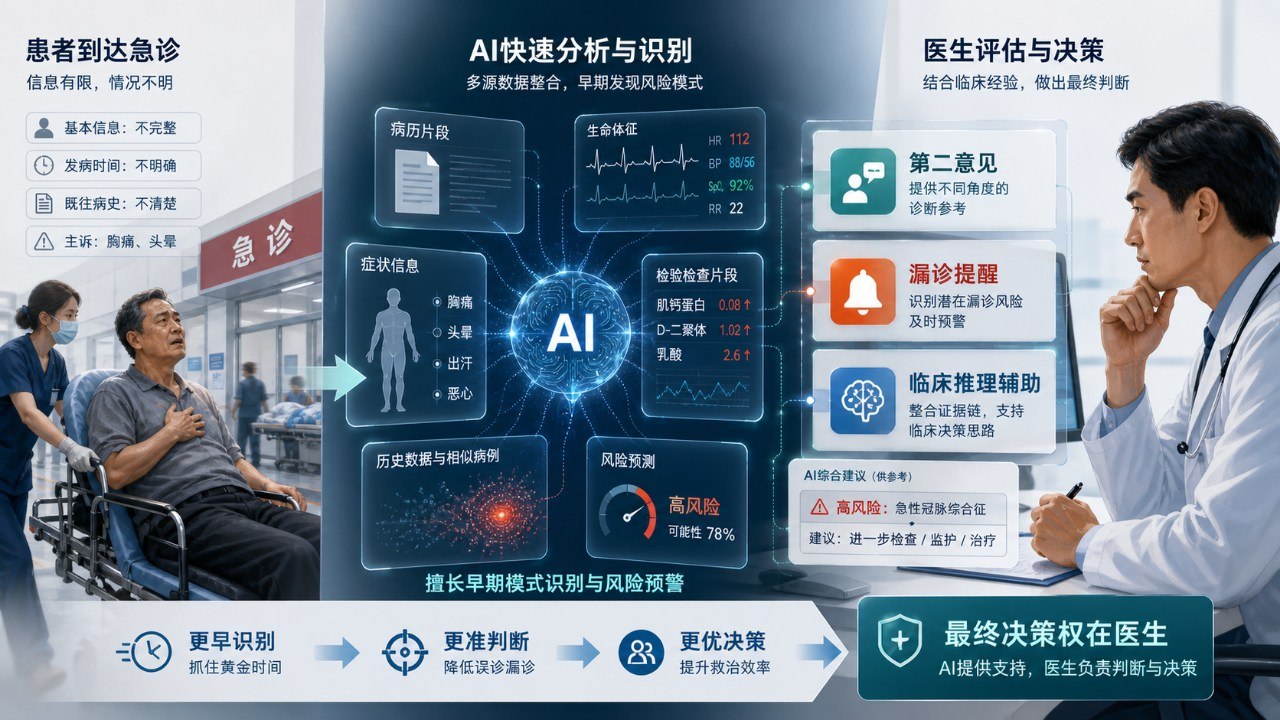
如果把这项研究放进更大的产业脉络里看,它的意义也许不在谁赢了谁,而在于医疗系统的组织方式可能会被改写。
过去几十年,医院的信息系统积累了海量电子病历,但这些数据大多是存下来了,并没有被真正高质量地实时利用。医生每天面对的,是充满噪音的病历、重复记录、跨科室碎片化信息,以及时间极度稀缺的工作环境。
而推理型大模型的强项,正是从海量文本和混乱上下文中提炼结构、发现线索、提出备选解释。
这意味着,未来最现实的场景不是“AI 医生坐诊”,而是以下几类系统先成熟起来:
- 急诊分诊辅助系统,在患者刚到院时自动扫一遍病历和症状,提示高风险可能性
- 住院病例第二意见系统,在医生形成初步诊断后,AI 给出是否存在漏掉的重要方向
- 治疗方案检查系统,在抗生素选择、会诊建议、临终沟通等复杂管理任务上提供提醒
- 病历噪音清洗系统,把零碎电子病历压缩成更可读、更适合决策的摘要
如果这些工具真正落地,最先被改变的不是有没有医生,而是医生的认知负荷分配方式。
很多今天靠人脑硬扛的信息检索、交叉比对和可能性枚举,未来会先由 AI 做第一层扫描。医生的角色则更可能转向,判断哪些建议可信、哪些要排除、如何结合病人实际状态做最终决策,以及承担沟通与责任。
这很像航空业的变化。自动驾驶系统没有让飞行员消失,但它改变了飞行员真正需要把精力放在哪些环节。
医疗AI最大的障碍,其实不是能力,而是责任
报道里有一句话很关键,目前并没有正式的责任框架来界定 AI 诊断出错时由谁负责。
这是所有医疗 AI 商业化都绕不过去的问题。
如果 AI 提醒了一个方向,医生没采纳,结果出事了,谁负责?如果 AI 建议错了,医生照做了,谁负责?如果医院把 AI 嵌入工作流,患者是否有知情权?如果不同年龄、语言背景、疾病谱的人群上模型表现不一样,如何审计公平性?
这些问题不解决,再强的模型也很难真正进入核心临床决策链。
所以,哈佛团队自己其实说得很克制。他们并没有宣称 AI 可以替代医生,而是强调,这项结果说明,必须尽快开展更严格的前瞻性临床试验,去验证这些系统在真实医疗环境中的价值、边界和风险。
这才是严肃研究者该有的态度。
结语
这篇《卫报》报道真正震撼人的地方,不是 AI 终于在某个榜单上赢了医生,而是它把一个更具体、更现实的问题摆在了所有人面前。
当 AI 已经能在急诊最早期、最混乱、最考验推理的环节里提供高质量判断时,医疗系统到底该怎样重新设计人与机器的分工?
也许未来最好的医院,不是没有医生的医院,而是每一个医生身边,都有一个不知疲倦、读得极快、能持续提醒遗漏风险的 AI 同事。
它不会替代人类去承担生命的重量,但它可能会让人类在最关键的时刻,少犯一些原本会犯的错。
如果真是这样,那么这项研究的意义,恐怕不只是 AI 在医学上更进一步,而是现代医疗决策的底层结构,已经开始被改写了。
参考来源:
- The Guardian: AI outperforms doctors in Harvard trial of emergency triage diagnoses
- TechCrunch: In Harvard study, AI offered more accurate emergency room diagnoses than two human doctors
- Harvard Magazine: AI Outperforms Doctors in Emergency Room Tasks, New Harvard Study Shows