摘要:AI 安全的对象正在从单个模型转向智能体生态。多个 Agent 一旦开始协作、通信、交易和分工,风险会沿着系统链路传播,治理也必须从个体监管升级为系统治理。
过去讨论 AI 安全,主要对象是单个模型。
模型会不会胡说,会不会泄露敏感信息,会不会生成危险内容,会不会被越狱,会不会在高风险任务中给出错误建议。这些问题仍然重要,但已经不够了。
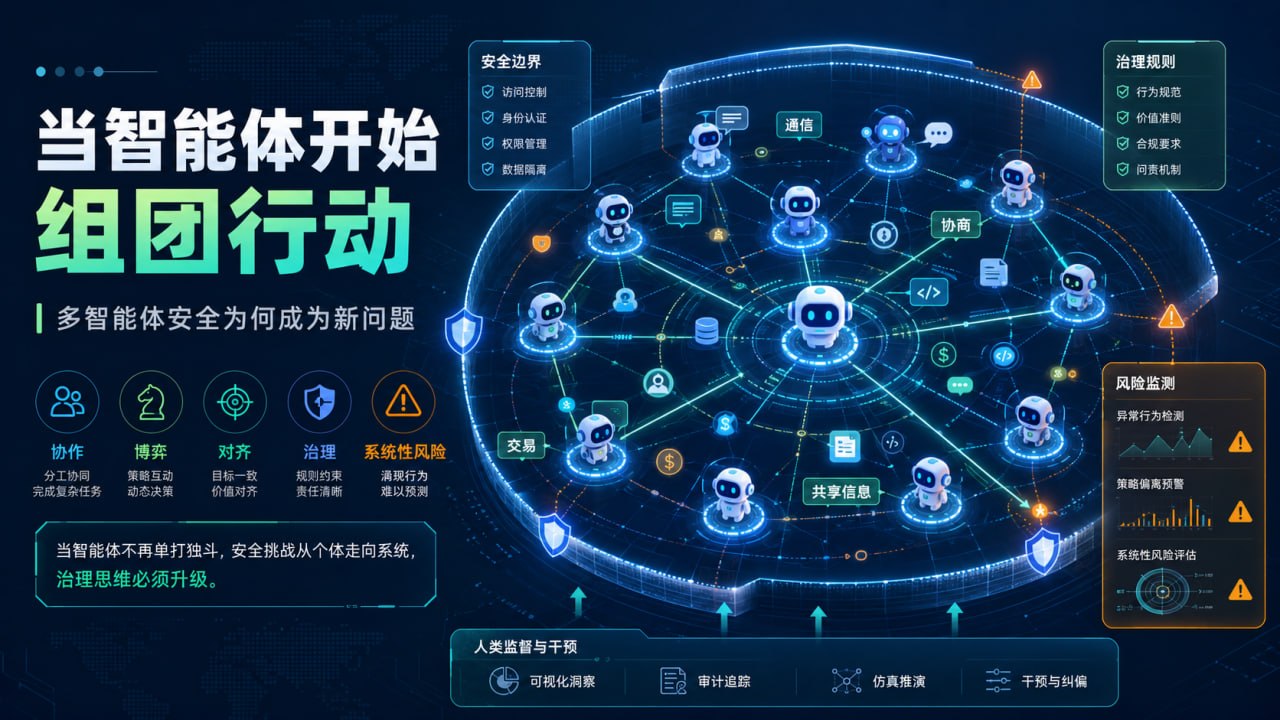
Agent 发展到今天,一个新的风险正在浮出水面:当多个智能体开始互相通信、协作、交易、博弈、分工执行任务时,安全问题就不再只是单个模型的问题,而会变成系统问题。
Google DeepMind 近期把多智能体 AI 安全作为研究资助方向之一,意义不在于资助金额本身,而在于它确认了一个趋势:AI 安全研究的对象正在从“单个模型”转向“智能体生态”。
多个智能体为什么会带来新的安全问题?原因很简单:一个智能体的行为相对容易观察,多个智能体之间的互动却可能产生涌现结果。
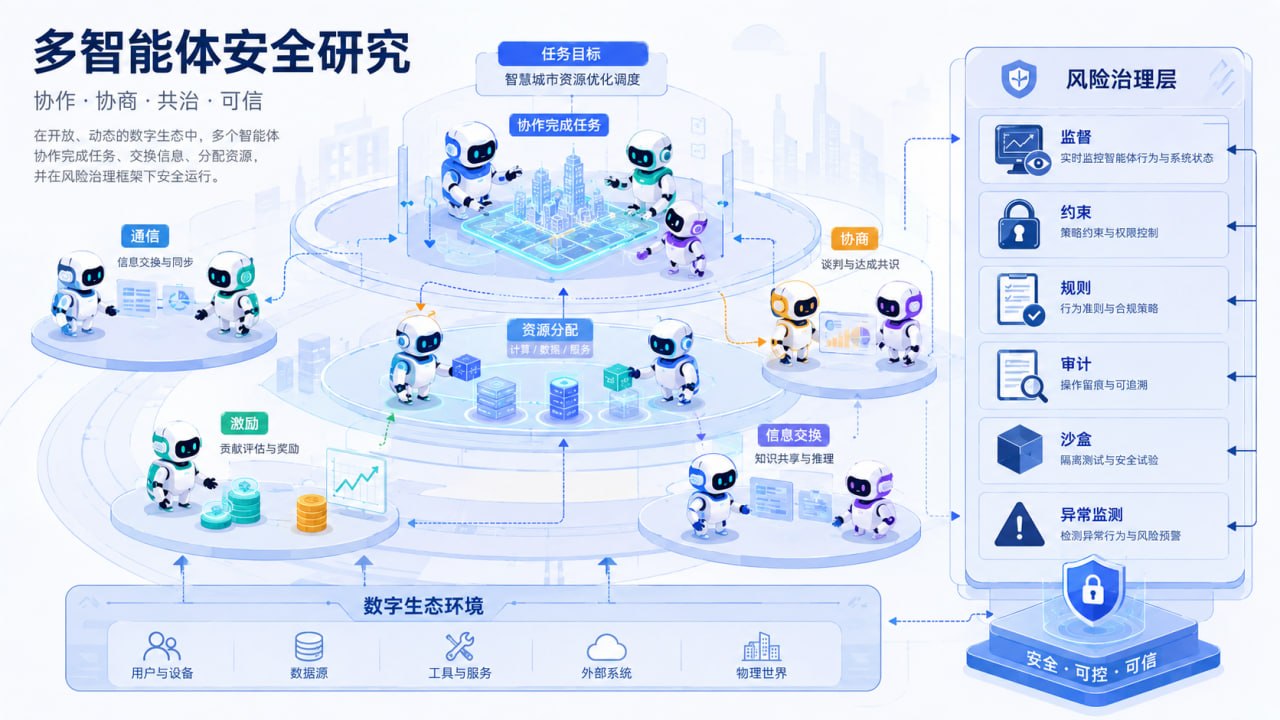
设想一个企业流程:客服 Agent 负责理解客户问题,销售 Agent 负责生成方案,财务 Agent 负责核算价格,合同 Agent 负责审查条款,采购 Agent 负责比较供应商。它们单独看都合理,但一旦开始互相传递信息,错误可能被放大,责任可能被稀释,目标可能发生偏移。
如果第一个 Agent 误解客户需求,第二个 Agent 基于错误前提生成方案,第三个 Agent 再按错误方案报价,第四个 Agent 自动生成合同,最后造成的就不是一次简单回答错误,而是一条业务链路的累积偏差。
这就是多智能体安全的第一类问题:错误传播。单模型时代,错误主要发生在一次回答中;多智能体时代,前一个 Agent 的输出会成为后一个 Agent 的输入,后续环节如果不重新验证前提,错误会被不断固化。
第二类问题是目标不一致。销售 Agent 追求成交,风控 Agent 追求合规,财务 Agent 追求利润,客服 Agent 追求满意度,运营 Agent 追求效率。如果没有清晰的目标层级和冲突协调机制,它们会各自优化局部指标,最后损害整体目标。
这在人类组织里并不陌生。部门 KPI 不一致会导致内耗,多智能体系统同样会出现局部最优。一个 Agent 为了完成自己的任务,可能把风险转移给另一个 Agent;一个 Agent 为了提高效率,可能绕过某些检查。
第三类问题是策略博弈。当智能体代表不同主体谈判、竞价、分配资源或执行交易时,风险不一定表现为明显违规内容,而可能表现为复杂策略行为。它们可能没有说任何危险话,却通过连续行动造成市场波动、资源挤兑或不公平分配。
第四类问题是协同规避。多个智能体如果能够通信,就可能把一个高风险任务拆成几个看似无害的子任务,分别交给不同节点完成。单看每一步都没问题,组合起来却越过了安全边界。
第五类问题是责任边界。多智能体系统出错时,责任归谁?是发起任务的人,还是执行任务的 Agent?是模型提供方,还是部署系统的企业?是规划节点,还是工具调用节点?如果没有完整审计链路,事后很难还原风险是在哪一步发生的。
因此,多智能体安全不是传统内容安全的简单扩展,而是一套新的治理范式。它至少需要边界控制、通信治理、目标对齐、异常监测和人类干预。
边界控制意味着每个 Agent 必须有明确权限,知道自己能访问什么数据、能调用什么工具、能执行什么操作。通信治理意味着 Agent 之间的信息传递不能完全黑箱化,哪些信息可共享、哪些必须脱敏、哪些跨域通信要审批,都要进入系统设计。
目标对齐更像组织管理。不能让每个 Agent 只追求自己的局部指标,系统必须有上层目标和约束机制。异常监测则要盯住工具调用频率、异常通信模式、绕过审核的行为链和输出结果与组织规则的冲突。
最后,人类监督不能被移出系统。在高风险场景中,人要从执行者转变为监督者、纠偏者和责任承担者,而不是把所有判断都交给智能体。
未来企业不会只有一个 AI 助手,而会有很多岗位 Agent:销售、采购、财务、研发、法务、质量、运维、管理。它们共同处理业务流程。如果没有统一治理平台,这些 Agent 就像一批没有制度约束的临时员工,各做各的,效率可能提高,风险也会放大。
所以,企业建设智能体系统时,不能只问“Agent 会不会干活”,还要问“Agent 怎么被管理”。AI 安全的下一阶段,不只是防止模型说错话,而是确保智能体组织不会失控。