摘要:Google Research 关于 reasoning 激活参数知识的研究提醒我们:RAG 不会消失,但它会从“外挂大脑”升级为企业 AI 系统中的可信知识供给层。
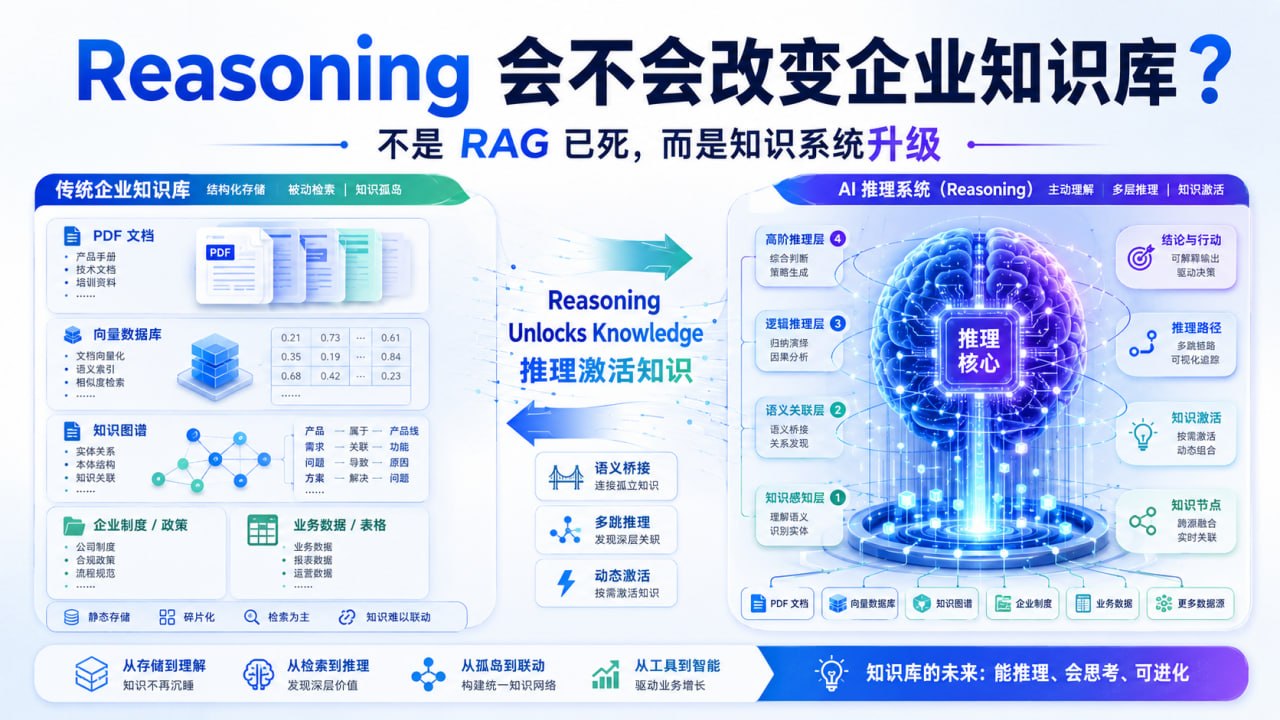
Google Research 近日发布了一篇很值得关注的研究文章:《Thinking to Recall: How Reasoning Unlocks Parametric Knowledge in LLMs》。表面上看,这是一篇关于大模型“记忆能力”的技术论文;但如果放到企业 AI、知识库和智能体落地的背景下看,它讨论的其实是一个更关键的问题:未来企业到底应该继续堆 RAG,还是开始重新理解“知识”与“推理”的关系?
过去两年,企业做大模型应用,几乎都会走向同一条技术路线:先把内部文档、制度、标准、产品手册、项目资料、客户资料整理出来,切片、向量化、入库,再用 RAG 检索增强生成。这个路线本身没有问题。因为企业知识大多不在通用模型训练数据里,模型也不可能知道某家企业最新的产品参数、内部流程、项目纪要和客户合同。
但问题在于,很多企业把 RAG 当成了大模型落地的全部答案。只要回答不准,就继续加文档;只要查不到,就继续优化向量库;只要效果不好,就调切片、调 Prompt、调召回。结果是,知识库越建越大,检索链路越来越复杂,但真正可用的智能应用并没有同步变强。
Google 这篇研究的价值就在这里:它提醒我们,大模型并不是只有“外部检索”这一种获取知识的方式,推理本身也可能成为一种“激活知识”的机制。
Reasoning 可能会把模型“想不起来”的知识激活出来
Google Research 研究的核心问题很具体:大语言模型参数中本来就存储了大量知识,但为什么有些知识在普通问答中调用不出来?
研究人员发现,即使面对一些并不复杂、甚至是单跳事实性问题,只要开启 reasoning,模型也更容易回答正确。换句话说,并不是所有需要 reasoning 的问题都真的“逻辑复杂”;有些问题只是模型需要更多计算过程,把原本隐藏在参数中的知识“想起来”。
Google Research 博客明确指出,reasoning enabled 时,模型能够召回一些在 reasoning off 时几乎无法恢复的答案。这个提升并不只是因为模型拆解了复杂问题,因为研究特意关注了大量简单、单跳问题。
这背后有两个机制很关键。
第一个叫 computational buffer effect,可以理解为“计算缓冲区效应”。模型在生成推理 token 的过程中,获得了更多中间计算空间,即使这些中间文字本身未必都有语义价值,也能帮助模型逐步逼近正确答案。
第二个叫 factual priming,可以理解为“事实启动”或“语义引导”。模型在推理过程中先生成一些相关事实,这些事实会像桥梁一样,把最终答案从参数记忆里牵引出来。
论文摘要也明确提到,这项研究识别了 computational buffer 和 factual priming 两个机制,同时指出如果中间事实产生幻觉,最终答案的幻觉风险也会上升。也就是说,reasoning 不是魔法,它既可能激活知识,也可能放大错误线索。
企业知识系统的旧分工正在变得不够准确
这件事为什么重要?因为它改变了我们对企业知识系统的理解。
过去我们经常把模型与知识库简单分工:模型负责语言生成和推理,知识库负责事实记忆。这个分工在工程上很清楚,但从能力演化看,它正在变得不够准确。
未来的大模型可能并不是一个“空脑袋的语言接口”,只能依靠外部文档才能回答事实问题。它本身就带有大量参数知识,而且越强的 reasoning 能力,越能把这些知识调动起来。
但这并不意味着 RAG 要消失。恰恰相反,Google 这篇研究更应该让我们反对一种极端说法:RAG 已死。
RAG 不会死,因为企业私有知识、实时知识、流程知识和权限知识都不可能完全依赖模型参数。今天一家制造企业的产品 BOM、设备台账、质量记录、售后工单、工艺变更、项目合同,这些内容既是私有的,也是动态变化的,而且还涉及权限、安全和审计。这些知识不可能靠通用模型“想起来”,必须通过企业内部知识系统和业务系统提供。
真正会变化的是 RAG 的位置。过去很多人把 RAG 当成“外挂大脑”,未来它更可能成为企业 AI 系统中的“可信知识供给层”。
公共知识、通用规律、行业常识,可以越来越多地交给模型自身和 reasoning;企业私有知识、实时数据、合规约束、业务流程,则仍然需要 RAG、数据库、知识图谱、API 和权限系统来支撑。
也就是说,未来不是 RAG 被 reasoning 取代,而是 RAG 从“万能补丁”回到它本来应该承担的位置:提供可验证、可追溯、可更新、可授权的企业知识。
知识库不能只停留在“文档入库”
这对企业 AI 落地有一个直接启示:知识库建设不能只停留在“文档入库”。
很多企业现在建设知识库,主要工作是把 PDF、Word、PPT、网页、制度文件全部丢进向量库,然后期待模型回答问题。短期看,这样能做出一个问答机器人;长期看,它很难支撑复杂智能体。因为智能体要完成工作,不只是查一句话,而是要理解对象、关系、约束、流程和目标。
例如,一个工程智能体要完成某个零部件优化设计,它不能只回答“某个标准怎么写”。它需要理解产品结构、材料参数、工况条件、仿真模型、设计约束、成本目标、质量规则和审批流程。这里的知识不再是文档片段,而是一个可被推理、可被调用、可被执行的知识体系。
知识库如果仍然只是“文档检索”,就无法支撑这类任务。
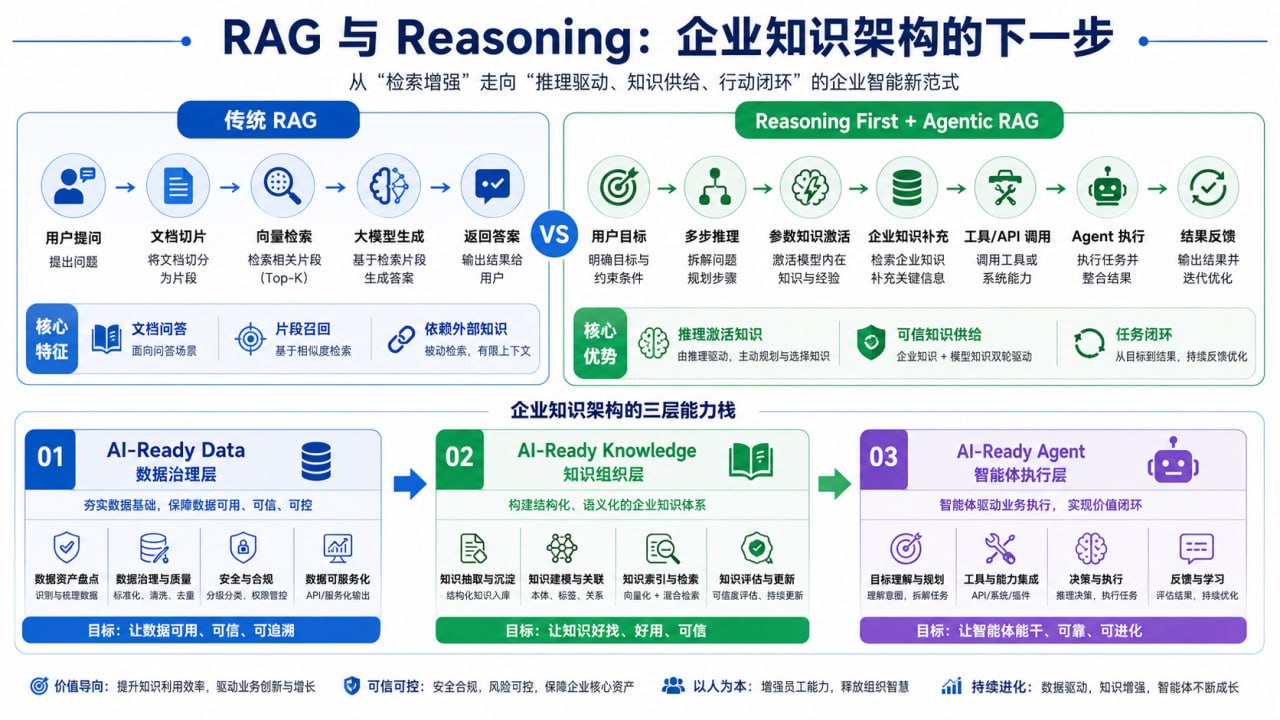
因此,Google 这项研究给企业带来的真正信号,不是“少做 RAG”,而是“重新设计知识架构”。未来企业需要从 Knowledge Base 走向 Knowledge OS。前者强调“把知识存进去,让人或模型查”;后者强调“把知识组织成对象、关系、规则和能力,让 Agent 能够调用”。
这也是 AI-Ready Data 之后必然出现的下一个概念:AI-Ready Knowledge。
AI-Ready Data 解决的是数据能不能被模型使用的问题,比如数据是否完整、干净、结构化、可授权、可追溯。AI-Ready Knowledge 解决的是知识能不能被智能体理解和推理的问题,比如知识是否有边界、是否有来源、是否能关联业务对象、是否能转换为规则、是否能触发工具调用、是否能进入任务闭环。
前者是数据治理,后者是知识工程。
工业智能尤其需要 AI-Ready Knowledge
这对工业智能尤其重要。
制造业里的知识具有几个特点:一是高度专业,很多内容来自工程经验和现场实践;二是强约束,设计、工艺、质量、安全都不能随意发挥;三是多模态,图纸、表格、曲线、工单、照片、仿真结果同时存在;四是强流程,知识不是孤立答案,而是嵌在研发、制造、运维和售后链条里。
这样的知识体系,单靠传统 RAG 很难真正用起来,必须结合 reasoning、知识图谱、工具调用和业务系统。
举一个场景。一个设备故障诊断 Agent 接到问题:“某型号泵在高温工况下振动异常,最近两周能耗升高,是否可能与轴承磨损有关?”
如果只是 RAG,它可能检索维修手册和历史案例,然后拼接答案。但真正有价值的智能体应该进一步分析运行曲线、对比历史工况、读取传感器数据、关联同型号设备案例、调用仿真或诊断模型,并输出可验证的判断路径。
这里面既需要外部知识,也需要 reasoning。没有知识,推理会空转;没有推理,知识只是一堆材料。
这也是为什么未来企业 AI 的竞争,不只是“谁的模型更强”,也不是“谁的知识库更大”,而是谁能把模型、知识、工具和流程组织成一个可执行系统。
Google 的研究让我们看到,模型的内部知识召回能力正在提升;但企业真正要做的,是把外部知识也变成模型和 Agent 能够可靠使用的基础设施。
RAG 的未来不是消失,而是升级
从这个角度看,RAG 的未来不是消失,而是升级。
第一代 RAG 是文档问答,核心是“找到相关片段”。第二代 RAG 是企业知识助手,核心是“基于权限和来源给出可信回答”。第三代 RAG 则会进入 Agentic RAG 阶段,核心是“在任务执行过程中动态调用知识、数据和工具”。
Google Research 近期也在讨论 Gemini Enterprise Agent Platform 中的 Agentic RAG。它指出,传统单步 RAG 难以处理现代企业工作流里的多来源、多跳问题;Agentic RAG 则通过规划、推理、迭代检索和上下文充分性判断,持续寻找足够信息,再生成更可靠的回答。
这说明大厂也在把 RAG 从问答系统推向智能体任务系统。
所以,这篇 Google Research 论文最值得写的地方,不在于它提出了一个耸动结论,而在于它提醒我们:Reasoning 正在改变大模型使用知识的方式。
过去我们认为“知识在外部,模型只负责生成”;现在需要承认,“模型内部也有知识,推理可以激活知识”。但同时,企业私有知识仍然必须通过可信系统提供。未来真正有效的企业 AI 架构,应该是内部参数知识、外部企业知识、实时业务数据和工具执行能力的组合。
对于做工业智能、数字工匠、企业 Agent 的团队来说,这个趋势非常关键。未来产品不能只做“上传文档问答”,也不能只追求接入更多模型,而要把行业知识组织成可推理、可调用、可闭环的能力栈。谁能把工程知识、业务流程、数据对象和智能体执行结合起来,谁就更接近真正的工业智能基础设施。
一句话总结:Reasoning 不会简单取代 RAG,但会重塑 RAG。企业知识库也不会消失,但它必须从“文档仓库”升级为“智能体可用的知识系统”。这才是 Google 这篇研究对企业 AI 落地真正有价值的启示。
参考资料
-
Google Research:Thinking to recall: How reasoning unlocks parametric knowledge in LLMs,2026-06-24
https://research.google/blog/thinking-to-recall-how-reasoning-unlocks-parametric-knowledge-in-llms/ -
arXiv:Thinking to Recall: How Reasoning Unlocks Parametric Knowledge in LLMs,2026-03-10
https://arxiv.org/abs/2603.09906 -
Google Research:Unlocking dependable responses with Gemini Enterprise Agent Platform’s Agentic RAG,2026-06-05
https://research.google/blog/unlocking-dependable-responses-with-gemini-enterprise-agent-platforms-agentic-rag/ -
Google Cloud:Gemini Enterprise Agent Platform
https://cloud.google.com/products/gemini-enterprise-agent-platform