摘要:TorchDAE 把微分代数方程求解、隐式刚性积分、高指标约简、事件重置、伴随灵敏度和 PyTorch 批量/GPU 工作流放到同一个接口下。它不一定马上替代成熟工业求解器,但为“带硬约束的物理仿真成为训练图中的一等公民”补上了关键一环。
过去几年,科学机器学习的主线之一,是把“仿真器”变成“可训练模块”。
Neural ODE、Neural SDE、可微渲染、可微物理引擎,背后的共同逻辑都是:
模型不再只是拟合数据,而是把物理方程、数值积分和梯度优化接到同一条计算图里。
PyTorch 生态中,torchdiffeq 已经提供可微 ODE 求解器,并支持通过伴随方法进行常数内存反向传播;torchsde 则把类似能力扩展到了随机微分方程。(torchdiffeq、torchsde)
但长期以来,一个很常见、却更难处理的方程类型仍然缺位:
微分代数方程,也就是 DAE。
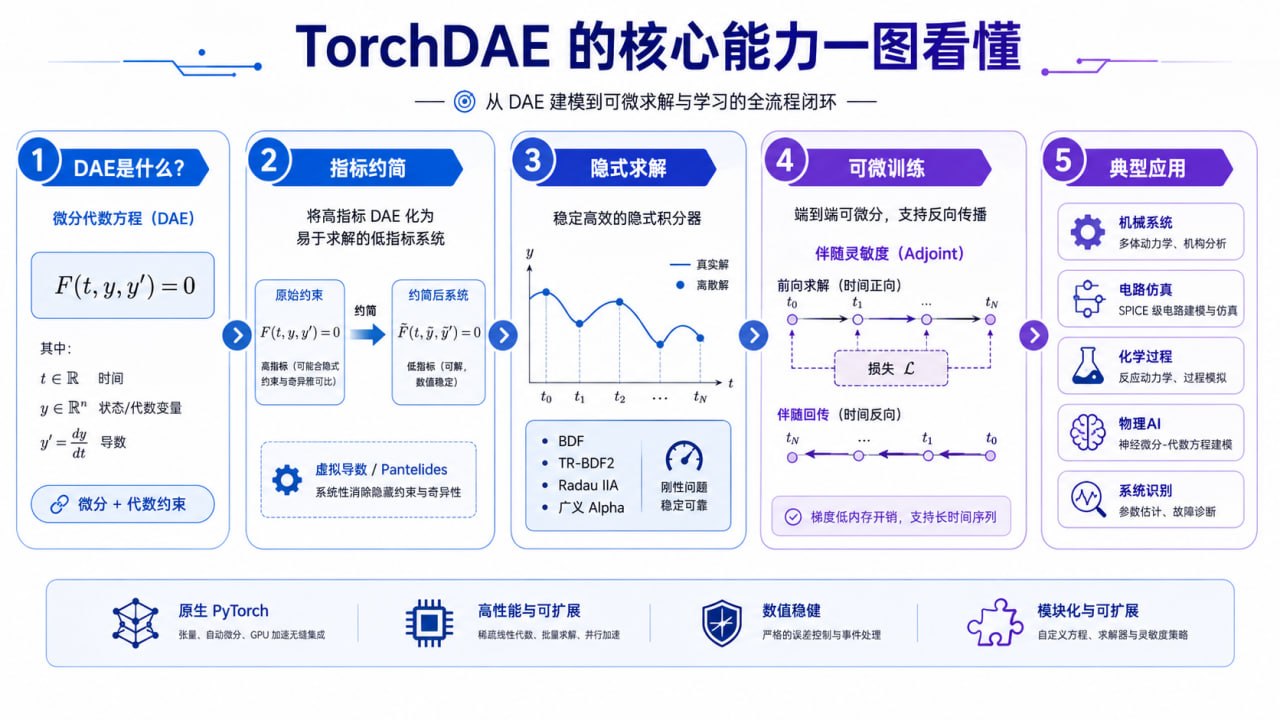
近日发布的 TorchDAE 正是瞄准这个空白。根据项目说明,它是一个基于 PyTorch 的数值 DAE 求解库,目标是提供可微、GPU 可运行、能与深度学习流水线直接集成的隐式 DAE 求解器。
PyPI 页面显示,TorchDAE 当前版本为 0.1.1,2026 年 6 月 2 日发布;项目支持 BDF1、BDF2、TR-BDF2、Radau IIA 等刚性问题常用隐式方法,支持高指标 DAE 的自动指标约简、约束漂移修正、事件与重置、连续伴随灵敏度,以及 PyTorch vmap 批量并行。(PyPI、GitHub)

DAE 为什么值得单独做一个库
很多真实物理系统并不是单纯的:
$$
\dot y = f(t, y, p)
$$
而更接近:
$$
F(t, y, \dot y, p) = 0
$$
这里既有描述状态演化的微分方程,也有必须始终满足的代数约束。
例如机械多体系统中的杆长约束、电路中的基尔霍夫约束、化工过程中的质量守恒与平衡约束,往往都不是“自由演化后再惩罚一下”那么简单。
DAE 的指数,通常可以理解为需要对代数约束微分多少次,才能把系统化成显式或半显式 ODE 形式;指数越高,数值求解越敏感,也越容易出现不稳定。(scikit-SUNDAE)
这也是 TorchDAE 的技术看点之一:
它不是简单把 ODE 求解器包一层,而是把 DAE 的几个关键难点直接放进库设计中。
对于 Index-1 DAE,TorchDAE 文档列出了 BDF1、BDF2、TR-BDF2 和 Radau IIA-5,其中 BDF 方法适合刚性系统,Radau IIA 则属于高阶全隐式 Runge-Kutta 路线。隐式方法的核心代价在于每一步都要解非线性方程,因此库中也暴露了 Newton 阻尼、Jacobian 重计算策略等参数,允许用户在稳定性与计算成本之间做权衡。(TorchDAE 文档)
高指标系统:约束不能只靠 loss 惩罚
更有意思的是高指标系统。
高指标 DAE 常见于机械约束系统,例如单摆、连杆、机器人机构等。如果直接数值积分,约束可能会慢慢漂移:
理论上长度应该恒定,计算结果却逐步偏离约束流形。
TorchDAE 给了两条路线。
一条是广义 Alpha 方法,用于高指标机械问题,并通过 rho_inf 控制高频数值阻尼;另一条是结构化指标约简,通过 Pantelides 算法和 Mattsson-Söderlind 虚拟导数方法,把高指标系统降到更容易求解的 Index-1 形式。(TorchDAE 高指标求解器文档)
虚拟导数方法的基本思想,是在对部分方程微分后,引入新的代数变量替代某些导数,从而避免系统过定,并把增强后的系统降到至多 Index-1;这一思想来自 Mattsson 与 Söderlind 关于 DAE 指标约简的经典工作。(SIAM)
这对科学机器学习很关键。
如果一个系统的核心约束本来就是硬约束,那么把它写成训练损失里的软惩罚项,通常只是把数值问题推给优化器。
DAE 求解器的价值,是让约束在求解层面参与每一步演化,而不是等轨迹已经跑偏之后再用 loss 拉回来。
可微仿真的价值在于能训练
在可微仿真里,仅有正向求解还不够。
真正的价值来自“能不能训练”。
设系统参数为 p,损失函数为 L(y(T)),我们希望得到:
$$
\frac{\partial L}{\partial p}
$$
如果把每个时间步的中间状态都保存下来再反向传播,长时间仿真会迅速吃满显存。
伴随灵敏度方法的优势,是通过构造一个反向时间求解的伴随系统,在显存与计算之间重新做权衡。
TorchDAE 文档中提供了 solve_dae_adjoint 和 DAEAdjointFunction.apply,用于计算 DAE 损失相对于初值和参数的梯度。(TorchDAE 伴随灵敏度文档)
这让 DAE 可以像神经网络层一样参与训练,例如做系统识别、参数反演、控制优化或物理信息建模。
从 API 角度看,TorchDAE 延续了 PyTorch 用户熟悉的残差式写法。用户不需要把方程强行整理成显式 y' = f(y),而是定义一个残差函数:
1 | def F(t, y, yp): |
然后选择 solve_bdf2、solve_generalized_alpha 或伴随版本求解器。
这个设计很重要,因为大量工程模型天然就是残差形式:
有些变量是动态状态,有些变量是拉格朗日乘子、电压、电流、压力或浓度约束。
把这些方程硬改成显式 ODE,不仅麻烦,还可能破坏问题结构。
批量化是工程价值,不只是 API 装饰
TorchDAE 的另一个工程价值是批量化。
科学机器学习中,我们往往不是只解一个系统,而是同时解成百上千组参数、初值或控制输入。
TorchDAE 声称支持 PyTorch vmap 和批量输入,并可在 GPU 与 CPU 管线中运行。(PyPI)
对系统识别来说,这意味着可以把一批实验轨迹同时送入求解器。
对参数优化来说,可以在 GPU 上并行评估多个候选参数。
对神经 DAE 来说,则可以把仿真器嵌入 mini-batch 训练流程,而不是每条样本串行求解。
此外,项目还提供事件检测与状态重置。TorchDAE 文档中提到,事件可被记录到 DAESolution 中,并通过二分查找定位事件时间,再用 Hermite 插值修正事件状态。(TorchDAE 事件文档)
这让它有机会处理混合系统和事件驱动系统,例如碰撞、触地、阀门切换、保护动作触发等。
这些问题如果只用连续 ODE 表达,往往会在不连续点附近变得非常脆弱。
不要误读成“第一个 DAE 求解器”
当然,TorchDAE 不应被理解为“世界上第一个 DAE 求解器”。
成熟的数值计算生态里,SUNDIALS 的 IDA/IDAS 长期用于 DAE 初值问题,其中 IDAS 还包含前向和伴随灵敏度分析;Julia SciML 生态也提供广泛的微分方程求解能力。(SUNDIALS IDA、SUNDIALS IDAS)
TorchDAE 的意义更准确地说,是把 DAE 求解、GPU 张量计算和 PyTorch 自动微分工作流拉到了同一个原生接口下。
对于已经用 PyTorch 构建模型、训练循环和部署管线的团队,这种“少跨语言、少胶水代码”的体验,可能比单个求解器指标更关键。
从应用层看,TorchDAE 最适合三类问题。
第一类是有硬约束的物理学习,例如机械臂、车辆动力学、多体系统、电路网络。相比把约束写进 loss 里软惩罚,DAE 形式可以在求解层面维护约束。
第二类是参数反演,例如通过观测轨迹反推出摩擦系数、刚度、阻尼、反应速率或电路参数。
第三类是混合系统和事件驱动系统,例如碰撞、触地、阀门切换、保护动作触发等。
新项目的价值和风险
需要提醒的是,TorchDAE 目前仍是很新的项目。
新库的优势是设计贴近当下 PyTorch 生态,缺点则是工程成熟度、边界案例覆盖、性能基准和长期维护都还需要社区验证。
尤其是 DAE 求解天然复杂:
初值一致性、Jacobian 奇异、事件附近的不连续性、伴随系统稳定性、GPU 上的批量非线性求解,任何一个环节都可能成为实际项目中的坑。
因此,更合理的使用方式不是一上来替换成熟工业求解器,而是先在可控问题上做对比验证:
检查残差、约束漂移、梯度数值差分一致性,以及不同步长下的收敛行为。
总体来看,TorchDAE 的出现,是 PyTorch 科学计算生态的一次重要补位。
ODE 让神经网络学会连续时间演化,SDE 引入随机过程,而 DAE 则把“硬约束”和“隐式物理结构”带进可微编程。
对于希望把机械、电路、化工、能源系统和深度学习真正接起来的研究者来说,TorchDAE 值得关注。
它的长期价值不只在于多几个求解器函数,而在于让“带约束的物理仿真”成为 PyTorch 训练图中的一等公民。