摘要:Anthropic 最新公开了 Claude.ai、Claude Code 和 Cowork 的沙箱隔离设计,真正值得关注的不是用了哪些安全名词,而是它明确承认:AI Agent 的安全边界不能只靠模型自觉,必须靠环境隔离、权限收口与出口治理一起兜底。

Anthropic 最近公开了一篇很少见、也很值得行业认真读的工程博文《How we contain Claude across products》。这篇文章最重要的价值,不是告诉大家 Claude 又多安全,而是第一次比较系统地把 Claude.ai、Claude Code 和 Claude Cowork 三类产品的隔离思路摊开讲明白:哪些能力放给模型,哪些边界交给系统,哪些风险是他们自己也曾经漏掉的。Simon Willison 在 2026 年 5 月 30 日的链接评注里说得很直接,AI 沙箱产品常见的问题不是“没有宣传安全”,而是“缺少足够细的文档,导致外界不知道该信多少”。这次 Anthropic 补上的,正是这块信任缺口。(Anthropic) (Simon Willison)
这件事值得所有做 Agent 的团队关注。因为过去很多人谈 AI 安全,重点都放在模型层:能不能识别危险请求,能不能拒绝恶意提示,能不能避免越权操作。但 Anthropic 这篇文章给出的核心判断其实很朴素:模型防线永远是概率性的,只要 Agent 真的开始读文件、跑命令、连系统、发请求,就必须假设它总有失手的一天。真正决定事故上限的,不是模型“会不会犯错”,而是环境“就算犯错也最多能碰到哪里”。
一、这篇文章真正讲的,不是“Claude 多安全”,而是“安全边界该放在哪”
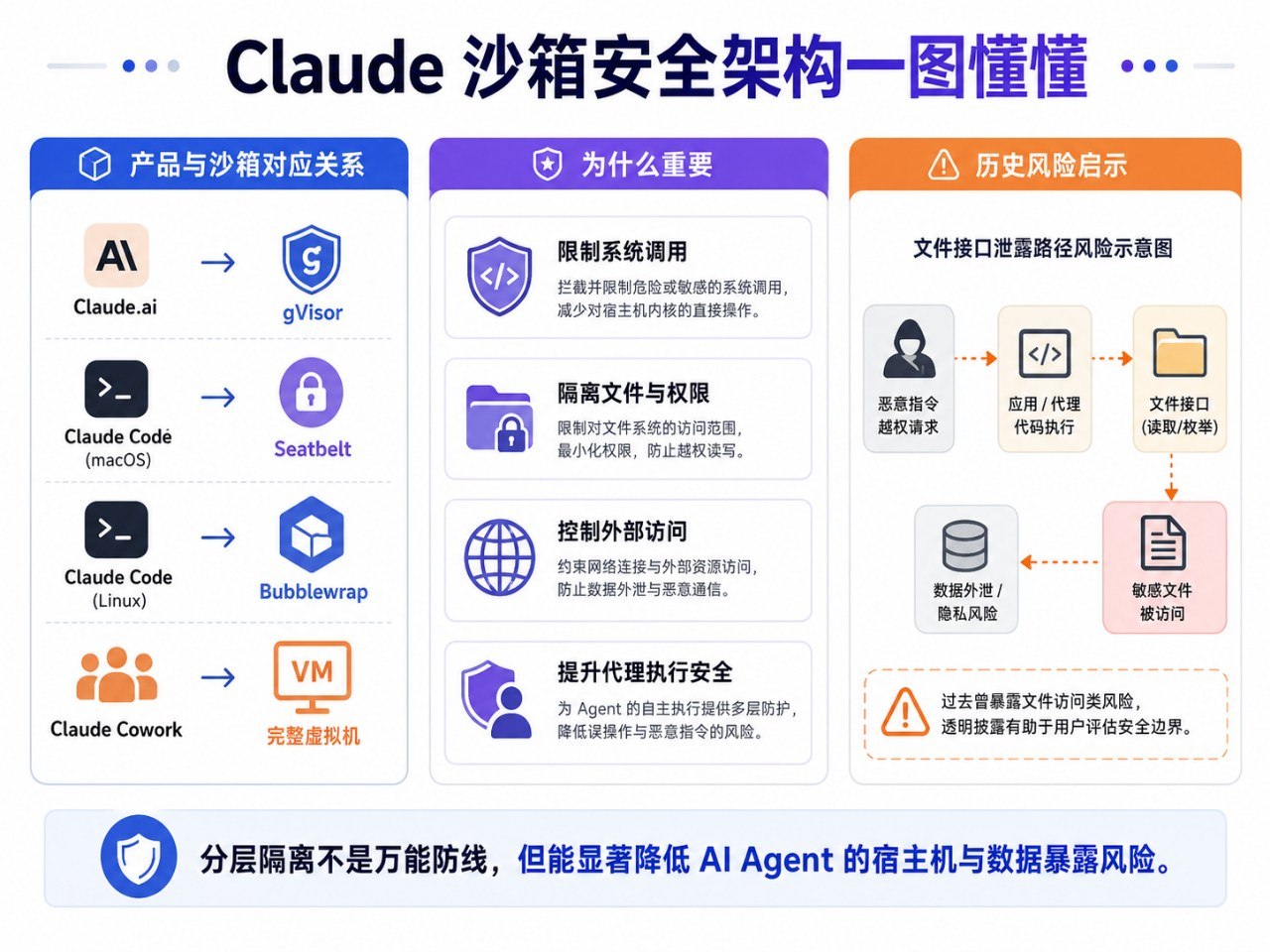
Anthropic 这次把三类环境分得很清楚。
第一类是 claude.ai 里的代码执行场景。它本质上是云端托管、会话级、临时性的执行环境,Anthropic 用的是 gVisor 容器。这里的重点不是给用户机器做防护,而是保护 Anthropic 自己的基础设施以及租户之间的隔离。因为所有代码都在服务端跑,文件系统是会话级临时态,没有用户本地工作区,也不承担长期驻留任务,所以 blast radius 最小,但能力上限也最低。
第二类是 Claude Code。这是最接近今天主流编程 Agent 的形态:模型运行在用户机器上,需要读代码、写文件、跑 shell、访问网络,否则就没有实际价值。Anthropic 最初采用的是人类审批思路,也就是读取可以放开,写入、bash、网络要弹权限确认。但他们很快发现,开发者会出现“批准疲劳”。于是后续把隔离边界下沉到操作系统层,在 macOS 上用 Seatbelt,在 Linux 上用 Bubblewrap,让默认行为变成“可读、可在工作区内写、默认禁网”。他们披露的一个关键数字是:这样做之后,权限提示数量下降了 84%。这说明安全如果只靠频繁弹窗,最终往往会输给人的习惯。(Anthropic)
第三类是 Claude Cowork。它面对的是更广义的知识工作和企业环境,任务跨度更大,外部连接更多,Anthropic 最终选的是完整虚拟机隔离。在 macOS 上使用 Apple Virtualization,在 Windows 上使用 HCS。这种方案最重、成本最高,但也最适合“既要访问工作材料,又不能直接碰到宿主系统”的任务形态。
把这三层放在一起看,会发现 Anthropic 其实是在说一件很现实的事:不存在一套放之四海而皆准的 Agent 沙箱。能力需求不同,隔离手段就必须不同。云端临时执行、开发者本地编程、企业知识工作,这三种场景的威胁模型根本不是一回事。
二、最有价值的部分,是它把“自己漏掉过什么”也讲了出来
这篇文章之所以比一般安全宣传更有参考价值,不只是因为它列出了 gVisor、Seatbelt、Bubblewrap、虚拟机这些名词,而是因为它讲了几个他们曾经判断失误的点。
第一个失误,发生在“信任提示出现之前”。Anthropic 透露,在 2025 年中到 2026 年 1 月之间,他们收到过多起 Claude Code 相关报告,问题结构都很相似:本地项目信息在用户明确点击“信任此目录”之前,就已经被解析甚至触发执行了。最直观的例子是仓库里的 .claude/settings.json hook。这个问题看似细节,实际非常典型。很多系统会天然觉得“本地目录是本地的,所以更可信”,但在 Agent 时代,本地目录、配置文件、localhost 服务、仓库元数据,本质上都可能是外部输入的延伸。只要边界还没建立,它们就不该被默认信任。
第二个失误,是“用户自己也可能成为提示注入入口”。Anthropic 披露,2026 年 2 月一次受控红队演练中,研究人员伪装成普通协作请求,诱导员工把一段看似正常的 prompt 交给 Claude Code 执行。结果在 25 次尝试里,有 24 次成功把 ~/.aws/credentials 读取、编码并 POST 到外部地址。这个案例很重要,因为它说明当恶意指令是借用户之手送进来时,单靠模型侧的“意图识别”几乎抓不住。系统看到的是“用户真的发了这个命令”。这时唯一有效的办法,只能是环境层:文件本来就不该读到,网络本来就不该打出去。
第三个失误,是 allowlist 不是“白名单通过”,而是“能力授权”。Claude Cowork 曾经出现过一个典型问题:因为产品必须访问 api.anthropic.com,所以出口代理允许对这个域名放行。结果攻击者在工作区文件里埋了恶意指令和自己的 API key,Claude 按提示把其他文件上传到了攻击者自己的 Anthropic 账户。也就是说,沙箱没有被打穿,白名单也没有失效,但数据仍然被带走了。Anthropic 后来的修复方式,是在虚拟机内部对自家 API 再做一层中间人代理,只放行带有本机分配会话凭证的请求,同时拦掉会触发服务端抓取的相关头。这一段很值得所有做企业 Agent 的团队反复看,因为它直接打破了一个常见幻觉:域名级白名单不等于动作级安全。
三、Anthropic 其实给行业补了一课:安全不是“要不要沙箱”,而是“沙箱放在哪里”
过去讨论 Agent 安全,很多团队容易陷入两种极端。
一种极端是过度相信模型。觉得只要拒绝策略够强、提示词写得够严、分类器再补几层,模型就能“学会克制”。但现实是,模型面对复杂工具链、长链路任务、伪装输入、多轮上下文时,出错是必然事件,不是偶然事件。
另一种极端是把沙箱理解成一个统一开关,好像“上了沙箱”就等于系统安全了。Anthropic 这篇文恰恰说明,真正难的不是有没有沙箱,而是边界到底画在哪。你是隔离系统调用,还是隔离文件路径?是只管目的域名,还是连具体 API 动作一起管?是让用户逐步审批,还是默认最小权限运行?是给 Agent 一整个容器,还是干脆给它一台虚拟机?这些问题没有标准答案,只能围绕具体任务设计。
从这个角度看,Anthropic 不是在展示一套“万能安全架构”,而是在展示一种更成熟的工程态度:承认模型层不可靠,承认自建胶水层往往最脆弱,承认用户也可能成为攻击路径,承认隔离会和可观测性、易用性、成本之间持续拉扯。
这比单纯喊“我们非常重视安全”有用得多。
四、对国内做 AI Agent 的团队来说,最该吸取的不是名词,而是方法
这篇文章对国内团队最大的启发,不是“赶紧把 gVisor、Seatbelt、Bubblewrap 都抄一遍”。真正该学的是三条方法论。
第一,先按场景分威胁模型,再选隔离手段。面向个人编程的 Agent、面向办公协同的 Agent、面向工业现场的 Agent,风险面完全不同。不要指望一个 prompt 审批框,或者一层 Docker,就能覆盖所有问题。
第二,不要把“能访问某个域名”误认为“只能做安全的事”。今天很多团队在做企业 Agent 联网时,还停留在“把若干域名加入 allowlist”的阶段。但只要这个域名背后还挂着上传、发信、抓取、转存、触发工作流之类的能力,你实际上就是把这些动作一起授权了。白名单必须逐渐从“域名级”升级到“动作级”和“凭证级”。
第三,要把“信任建立之前的所有输入”都当成不可信。仓库配置、文档元数据、邮件正文、聊天记录、网页内容、插件响应、本地目录、浏览器 localhost 服务,这些东西在 Agent 体系里都可能成为注入入口。谁先于授权边界被解析,谁就是高危面。
如果再往前推一步,这篇文章其实也解释了为什么未来企业真正需要的,不只是更聪明的模型,而是更可靠的执行环境。模型可以越来越强,但如果环境边界、权限治理、出口控制、日志审计做不好,模型越强,事故半径只会越大。
五、为什么这会增强行业信心?
很多人会觉得,Anthropic 把这些风险写出来,反而是在暴露问题。但从产业角度看,恰恰相反。
今天市场对 Agent 最大的不信任之一,就是“看起来什么都能做,但不知道它到底被关在哪个笼子里”。如果厂商只展示效果,不解释边界,企业安全团队就只能按最坏情况估算,最后往往就是不上线,或者彻底禁用。
Anthropic 这次公开的意义,在于它给了外界一个可以讨论、可以质疑、也可以对比的基准。你可以不认可它的每个取舍,但至少你知道 claude.ai 是什么隔离层,Claude Code 的默认权限怎么收,Cowork 为什么要上 VM,过去又在哪些地方踩过坑。安全从来不是靠一句“相信我”建立的,而是靠边界可描述、失败可复盘、策略可审计。
这也是为什么 Simon Willison 会特别强调“文档本身就是信任的一部分”。对真正要把 Agent 放进生产环境的人来说,透明度本身就是产品能力。
六、结语:AI Agent 的安全底座,必须从“模型自觉”转向“系统约束”
Anthropic 这篇长文最值得记住的一句话,不是某个具体技术选型,而是背后的思路:如果敏感凭证根本进不了沙箱,它就不可能被带出去;如果网络默认打不出去,再聪明的恶意提示也很难完成最后一步;如果 Agent 只能碰到用户明确挂载的工作区,它的破坏半径就会被硬性压住。
换句话说,真正成熟的 Agent 安全,不是要求模型永远听话,而是接受模型迟早会犯错,然后提前把它关进一个“就算犯错也出不了大事”的环境里。
这也是整个行业接下来必须补的课。未来 AI Agent 一定会越来越深入代码仓库、办公套件、知识库、生产系统和工业现场。到那个阶段,再讨论“模型会不会自己克制”已经太晚了。真正靠谱的路线,只能是模型层做识别,系统层做收口,执行层做隔离,出口层做拦截,审计层做回放。
Anthropic 这次公开的,不只是 Claude 的沙箱设计,更像是在告诉整个行业:Agent 时代的安全工程,已经不能停留在提示词和权限弹窗了。谁先把环境边界做实,谁才更有资格把智能体放进真实世界。