摘要:深入剖析奇异值分解(SVD)的历史渊源、数学原理及其在现代工程中的核心应用,揭示这一矩阵代数中最优美的分解如何成为推荐系统、图像压缩和自然语言处理的底层引擎。
影响人类的50个最重要算法系列:4/50
如果说蒙特卡洛方法教会了计算机"用随机性逼近真相",快速傅里叶变换教会了计算机"把复杂信号拆成简单波形",共轭梯度法教会了计算机"在百万维空间里高效寻路",那么奇异值分解(Singular Value Decomposition, SVD)教会计算机的是一件更根本的事:看透一个矩阵的本质结构。
这听起来很抽象。但换个说法你就明白了:Netflix怎么知道你可能喜欢哪部电影?搜索引擎怎么理解一个词和另一个词的语义关系?一张10MB的照片怎么被压缩到几百KB还不太失真?卫星遥感数据怎么从噪声中提取有用信号?
这些看似毫不相关的问题,底层都在用同一个工具:SVD。
一、历史来龙去脉:从19世纪的纯数学到20世纪的计算革命
SVD的数学理论可以追溯到19世纪。1873年,意大利数学家贝尔特拉米(Eugenio Beltrami)首次提出了矩阵奇异值的概念。几乎同时期,法国数学家卡米尔·若尔当(Camille Jordan)也独立发现了类似结果。随后,英国数学家西尔维斯特(James Joseph Sylvester)在1889年进一步发展了这一理论,并首次使用了"奇异值"这个术语。
但在那个没有计算机的年代,SVD只是纯数学家们的智力游戏。手工计算一个10×10矩阵的SVD就已经是噩梦级的工作量,更别说实际工程中动辄成千上万维的矩阵了。
真正的转折发生在1960-70年代。随着电子计算机的成熟,数值线性代数领域迎来了黄金时期。1965年,Gene Golub和William Kahan发表了具有里程碑意义的论文,提出了计算SVD的稳定数值算法。随后,Golub和Christian Reinsch在1970年进一步完善了这一算法,使其成为工程实践中真正可用的工具。
从此,SVD从数学家的书架走进了工程师的工具箱。
二、最通俗的原理:把任何变换拆成"旋转-拉伸-旋转"
要理解SVD,先要理解矩阵在做什么。
在线性代数里,一个矩阵本质上代表一种"变换"。当你用一个矩阵乘以一个向量时,你其实是在对这个向量做某种几何操作——可能是旋转、拉伸、压缩、投影,或者这些操作的组合。
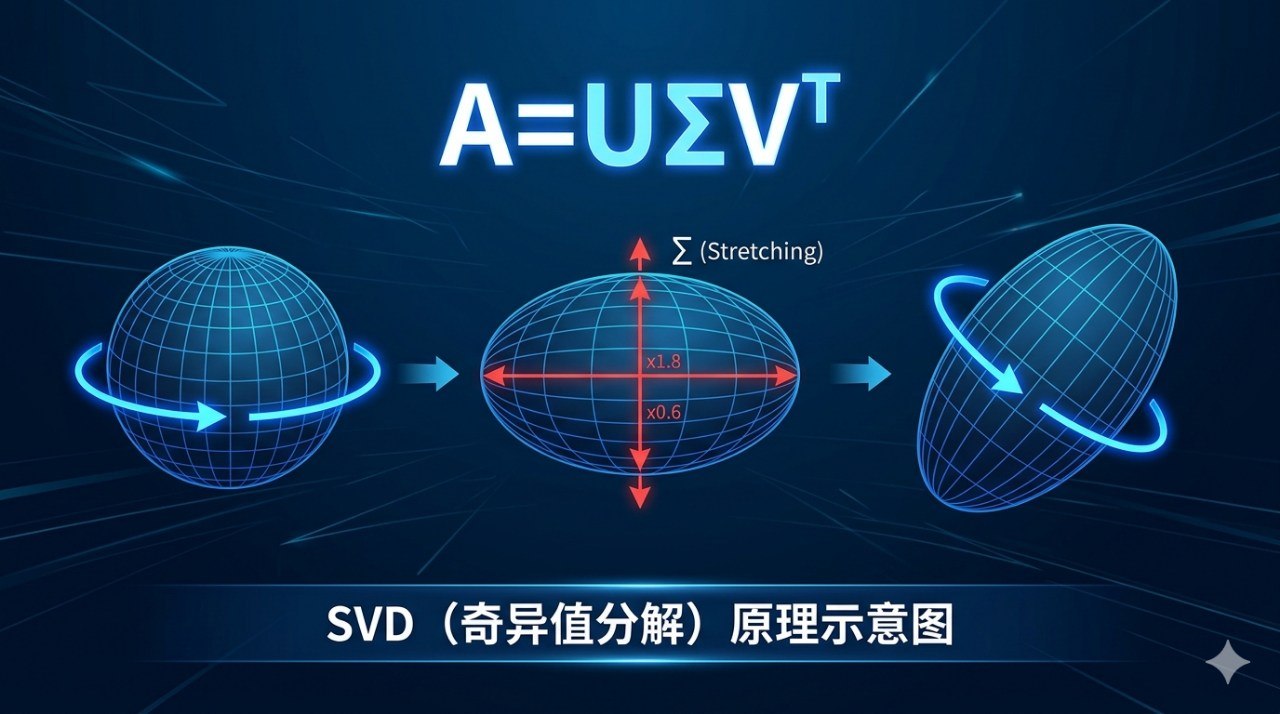
SVD的核心思想是:不管一个矩阵代表的变换有多复杂,它都可以被拆解成三步最简单的操作。
具体来说,任何一个m×n的矩阵A,都可以被分解为:
$$A = U \Sigma V^T$$
这三个矩阵分别代表:
- V^T(第一步旋转):先在输入空间里做一次旋转,把数据对齐到"最有意义"的方向上
- Σ(拉伸/压缩):沿着每个方向做不同程度的拉伸或压缩——这些拉伸系数就是"奇异值"
- U(第二步旋转):在输出空间里再做一次旋转,把结果摆到最终位置
打个比方:想象你在揉面团。不管面团最终被揉成什么形状,这个过程都可以分解为"先转一个角度,然后沿不同方向拉伸,最后再转一个角度"。SVD就是找到这三步操作的精确参数。
三、奇异值:数据的"重要性排行榜"
SVD最强大的地方在于中间那个Σ矩阵。它是一个对角矩阵,对角线上的值就是奇异值,而且按从大到小排列。
这些奇异值告诉你一件至关重要的事:数据中每个"方向"的重要程度。
第一个奇异值最大,代表数据中最主要的变化模式;第二个次之,代表第二重要的模式;以此类推。通常,前面几个奇异值会远大于后面的,这意味着数据的大部分信息集中在少数几个方向上。
这就引出了SVD最核心的应用思想:低秩近似。
如果一个1000×1000的矩阵,前20个奇异值占了总能量的99%,那你只需要保留前20个奇异值对应的分量,就能用一个"秩为20"的矩阵近似原矩阵,误差极小,但数据量从100万个数压缩到了4万个。
这不是近似,这是"看透本质后的精简"。
四、改变世界的应用场景
Netflix推荐系统:猜你喜欢
2006年,Netflix悬赏100万美元,征集能把其电影推荐算法提升10%的方案。最终获胜的团队,核心武器就是SVD。
原理很直观:把"用户×电影"的评分矩阵做SVD分解。每个用户被映射到一个低维"品味向量",每部电影被映射到一个低维"特征向量"。一个用户对一部未看电影的预测评分,就是这两个向量的内积。
SVD之所以有效,是因为它发现了评分矩阵背后的"隐含因子"——也许第一个因子对应"动作片vs文艺片",第二个对应"新片vs经典",第三个对应"好莱坞vs独立制作"。用户和电影都在这些隐含维度上有自己的坐标,匹配度高的就是好推荐。
图像压缩:用更少的数据保留更多的信息
一张灰度图片就是一个像素值矩阵。对它做SVD,你会发现前几十个奇异值就包含了图像的绝大部分视觉信息(轮廓、主要色块),而后面的奇异值对应的是细节和噪声。
只保留前k个奇异值,你就得到了一张压缩图像。k越小,压缩率越高,但细节损失越多。这就是为什么JPEG压缩后的图片会有"模糊感"——本质上就是丢弃了小奇异值对应的高频细节。
潜在语义分析(LSA):让机器理解语义
在自然语言处理的早期,研究者构建了"词-文档"矩阵:每一行是一个词,每一列是一篇文档,矩阵元素是这个词在这篇文档中出现的频率。
对这个矩阵做SVD,奇迹发生了:语义相近的词(比如"汽车"和"轿车")在低维空间中被映射到了相近的位置,即使它们从未在同一篇文档中共同出现过。
这就是潜在语义分析(Latent Semantic Analysis),它是后来Word2Vec、BERT等词向量技术的思想先驱。SVD帮助机器第一次"理解"了词语之间的语义关系。
主成分分析(PCA):高维数据的降维利器
PCA是统计学和机器学习中最常用的降维方法,而它的数学本质就是对数据协方差矩阵做SVD(或等价地,做特征值分解)。
当你有一个包含几百个特征的数据集时,PCA通过SVD找到数据变化最大的几个方向(主成分),然后把数据投影到这些方向上。这样,你可以用3-5个主成分就捕获原始数据90%以上的信息,大幅降低后续分析和建模的复杂度。
五、为什么SVD如此特殊?
线性代数中有很多矩阵分解方法——LU分解、QR分解、Cholesky分解、特征值分解。为什么SVD被称为"万能分解"?
原因有三:
第一,它对任何矩阵都适用。 特征值分解只能用于方阵,Cholesky分解要求正定矩阵,但SVD对任意形状、任意性质的矩阵都成立。不管是3×5的矩阵还是10000×200的矩阵,SVD都能做。
第二,它给出了最优低秩近似。 Eckart-Young定理证明:在所有秩为k的矩阵中,SVD截断得到的那个,是与原矩阵距离最近的。换句话说,如果你想用更少的信息来近似一个矩阵,SVD给出的方案是数学上最优的,没有之一。
第三,它揭示了矩阵的几何本质。 奇异值告诉你变换在每个方向上的"放大倍数",左右奇异向量告诉你输入和输出空间的"自然坐标系"。这比任何其他分解都更直观地展示了矩阵在做什么。
六、从理论到工程:计算SVD的挑战
SVD在理论上很完美,但在工程实践中计算它并不容易。
对于一个n×n的矩阵,直接计算SVD的时间复杂度是O(n³)。当n达到百万级时(比如推荐系统中的用户-物品矩阵),精确计算SVD是不现实的。
这催生了一系列近似算法:
- 截断SVD:只计算前k个最大的奇异值,而不是全部
- 随机化SVD:用随机投影先降维,再在低维空间中计算精确SVD
- 增量SVD:当数据不断更新时,增量地更新分解结果而不是从头重算
这些工程优化让SVD能够处理现代大规模数据。今天,Python的scikit-learn、NumPy,以及Spark MLlib等分布式计算框架,都内置了高效的SVD实现。
七、SVD的当代意义
在大语言模型时代,SVD依然活跃在最前沿。
LoRA(Low-Rank Adaptation)——当前最流行的大模型微调方法——其核心思想就是:模型权重的更新矩阵是低秩的,可以用两个小矩阵的乘积来近似。这本质上就是SVD思想的直接应用。
量化压缩、模型剪枝、知识蒸馏——这些让大模型变小变快的技术,很多都在利用SVD发现的"大部分信息集中在少数方向"这一规律。
从19世纪的纯数学定理,到21世纪驱动推荐系统和大语言模型的核心工具,SVD用了150年证明了一件事:真正深刻的数学,永远不会过时。
📥 系列回顾: