摘要:在人工智能迅猛发展的今天,机器人不再是科幻电影中单纯执行预设程序的机械臂,而是需要真正"理解"物理世界的智能体。想象一下,一台机器人能在工厂车间自主巡逻,精确读取复杂的模拟压力表、液位计,甚至在多角度摄像头反馈下判断任务是否彻底完成;它还能在杂乱的工作台上准确找出指定工具,避免幻觉错误,同时严格遵守"不要搬动超过20公斤的重物"或"避免接触液体"的安全约束。这一切,正是谷歌DeepMind最新发布的Gemini Robotics-ER 1.6所带来的突破。 Gemini Robotics-ER系列是谷歌DeepMind专为具身智能(Embodied AI)设计的推理优先模型。ER代表"Embodied Reasoning",即具身推理,强调让AI从纯数字世界走向物理行动。1.6版本在1.5基础上实现了质的飞跃,尤其在视觉理解、空间推理和代理能力上大幅提升。它不再是简单的图像识别工具,而是集空间感知、世界知识和动态决策于一体的"机器人大脑"。通过与波士顿动力公司Spot机器人的深度合作,这一模型已能直接应用于工业巡检等高价值场景,标志着机器人从"执行者"向"思考者"的转变。

在人工智能迅猛发展的今天,机器人不再是科幻电影中单纯执行预设程序的机械臂,而是需要真正"理解"物理世界的智能体。想象一下,一台机器人能在工厂车间自主巡逻,精确读取复杂的模拟压力表、液位计,甚至在多角度摄像头反馈下判断任务是否彻底完成;它还能在杂乱的工作台上准确找出指定工具,避免幻觉错误,同时严格遵守"不要搬动超过20公斤的重物"或"避免接触液体"的安全约束。这一切,正是谷歌DeepMind最新发布的Gemini Robotics-ER 1.6所带来的突破。
Gemini Robotics-ER系列是谷歌DeepMind专为具身智能(Embodied AI)设计的推理优先模型。ER代表"Embodied Reasoning",即具身推理,强调让AI从纯数字世界走向物理行动。1.6版本在1.5基础上实现了质的飞跃,尤其在视觉理解、空间推理和代理能力上大幅提升。它不再是简单的图像识别工具,而是集空间感知、世界知识和动态决策于一体的"机器人大脑"。通过与波士顿动力公司Spot机器人的深度合作,这一模型已能直接应用于工业巡检等高价值场景,标志着机器人从"执行者"向"思考者"的转变。
空间推理:从指向到复杂物理逻辑的基石
空间推理是Gemini Robotics-ER 1.6的核心竞争力之一。传统机器人视觉系统往往停留在"看到物体"的层面,而1.6版本能通过"指向"(pointing)这一基础动作,完成更高级的任务。指向不是简单的手势,而是模型在图像中精确定位关键点的能力,用于计数、关系判断、轨迹规划和约束遵守。
例如,在一个杂乱的工作台上,模型可以准确识别并指向:2把锤子、1把剪刀、1支画笔、6把钳子,以及一组园艺工具。它不会凭空"幻觉"出不存在的轮胎或电钻,也能处理"从A点移动到B点"的相对位置逻辑。更进一步,它能映射物体运动轨迹,计算最优抓取点,甚至判断物体是否符合尺寸限制——比如"这个物体能否放入蓝色杯子"。
这种能力源于模型将指向作为中间表示(intermediate representation),用于分解复杂任务。在数学估算中,它会指向刻度线,通过代码辅助计算比例和间隔,实现亚刻度级精度。这比以往模型前进了一大步:Gemini Robotics-ER 1.5在计数和指向精度上容易出错,而通用Gemini 3.0 Flash虽然接近,但对细粒度工具的处理仍显不足。1.6版本的提升,让机器人能在动态环境中进行实时空间决策,为后续行动规划奠定基础。
代理视觉:代码+视觉的智能融合,精确读取模拟仪表
Gemini Robotics-ER 1.6最令人惊叹的创新是"代理视觉"(agentic vision)——将视觉推理与代码执行无缝结合。这项能力特别适用于工业仪表读取这一长期难题。工厂中常见的模拟压力表、液位计往往因相机畸变、光线干扰、刻度模糊而难以自动识别。传统方法需要大量人工标注和固定算法,而1.6版本能自主编写代码,动态修正问题。
具体流程是:机器人首先通过指向锁定仪表关键区域(如指针、液面、刻度线、文字单位);然后"放大"图像细节,利用代码执行估算比例、间隔和边界;最后结合世界知识解读读数。例如,面对一个圆形压力表,模型能处理多根指针组合成的十进制读数,或垂直液位计中因透视扭曲的液面高度。即使相机角度导致畸变,它也能通过代码校正,达到亚刻度精度。
这一过程充分体现了"代理"特性:模型不是被动识别,而是主动规划中间步骤、调用外部工具(如代码解释器),并验证结果。实际演示中,Spot机器人巡逻时拍摄的仪表图像被传入模型,后者输出精确读数,并直接对接数据分析系统。这种能力极大降低了工业巡检的人力成本,同时提高了数据实时性和准确性。在多视角融合下,模型还能从不同摄像头(如头顶和腕部)获取信息,构建完整场景理解,避免单一视角的遮挡问题。
多视角推理与任务完成判断:机器人自主决策的关键
另一个重大进步是多视角推理。机器人往往配备多个摄像头,传统系统难以融合这些异构视图。1.6版本能实时关联多路视频流,理解它们的空间关系,从而判断任务是否完成。
以一个简单放置任务为例:将蓝色笔放入黑色笔筒。模型会同时分析腕部摄像头(近距离细节)和头顶摄像头(全局位置),当笔完全落入筒内且无晃动时,才判定"任务完成",否则自动重试。这种"成功检测"能力解决了机器人长期面临的"何时停止行动"难题。在工业场景中,这意味着巡检机器人能在确认仪表读数稳定后,继续下一个目标,而非无限循环或遗漏隐患。
多视角推理还增强了模型在遮挡、动态环境下的鲁棒性。它能处理光线变化、物体移动等干扰,融合信息后输出可靠决策。这与早期模型形成鲜明对比:1.5版本在单视角下尚可,但在多视图融合时容易出错。
工业巡检:Spot机器人与AI的完美协同
Gemini Robotics-ER 1.6的最大落地场景是工业设施巡检。与波士顿动力Spot四足机器人结合后,效果尤为显著。Spot能在复杂工厂环境中自主移动,拍摄模拟仪表图像。模型则负责后续处理:自动校正相机畸变、计算精确刻度,并生成结构化数据。
这一协作解决了工业界长期痛点——人工巡检效率低、危险高、数据延迟大。现在,机器人能24小时不间断监测压力、液位、温度等关键参数,异常时立即报警。波士顿动力Spot副总裁兼总经理Marco da Silva表示:"仪表读取和可靠任务推理能力,将让Spot完全自主地看到、理解并应对真实世界挑战。"这一评价并非夸张,它预示着智能巡检将成为工厂数字化转型的核心基础设施。
除了巡检,模型还能在车间中辅助物体定位、工具清点等任务,显著提升生产效率。
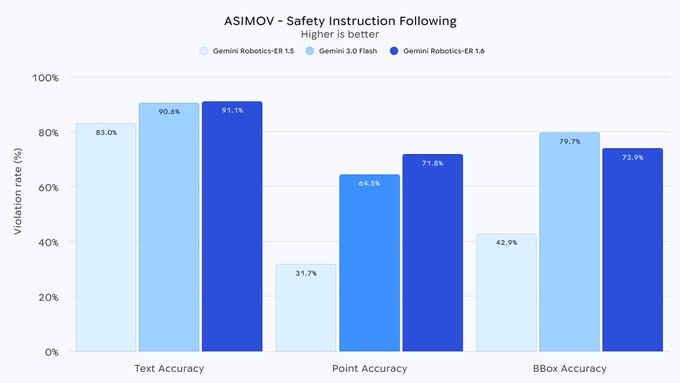
安全至上:物理约束与风险感知的双重保障
安全性是1.6版本的突出亮点,被誉为"迄今最安全的机器人模型"。它在每个层面都内置安全机制:不仅遵守通用AI安全政策,还特别强化空间推理下的物理约束。
例如,模型能根据指向输出判断物体重量(避免搬动超20kg物品)或属性(拒绝处理液体)。在真实伤害报告数据集上,其视频风险检测能力较Gemini 3.0 Flash提升10%,文本描述提升6%。这意味着机器人能在执行指令前主动识别潜在危险,如尖锐物体、泄漏液体或人体接近风险。
安全提升得益于端到端的训练和指向机制:模型不只是"看到",而是"理解后果"。相比前代,1.6在对抗性空间任务中的合规率大幅领先,确保机器人不会因误判而引发事故。
基准测试与技术架构洞察
官方基准显示,1.6在仪表读取、指向、计数、成功检测等多项指标上全面超越1.5和3.0 Flash。仪表读取测试特别引入代理视觉支持,而多视角成功检测则使用独立样本,避免直接比较偏差。指向基准中,1.6的精确率和零幻觉率领先明显。
从架构看,Gemini Robotics-ER 1.6作为高阶推理引擎,擅长调用外部工具:Google搜索、世界知识库、视觉-语言-动作(VLA)模型或用户自定义函数。它不是端到端视觉-动作模型,而是"思考层",与底层执行器(如Spot的运动控制)协同工作。这种分层设计既提升灵活性,又便于迭代。
训练过程中,模型大量使用真实机器人数据和模拟场景,特别针对工业仪表、杂乱环境和多视图融合进行优化。虽未公开具体参数规模,但其在代码-视觉融合上的表现,显示出谷歌在多模态大模型上的深厚积累。
可用性与开发者生态
Gemini Robotics-ER 1.6现已上线Google AI Studio和Gemini API,开发者可立即试用。无论是构建自定义巡检机器人,还是集成到现有自动化系统中,都只需几行代码调用即可接入。其开放性体现在支持用户上传10-50张标注失败案例图像,帮助DeepMind进一步优化模型鲁棒性。
这一举措极大降低了机器人AI的门槛。中小企业无需从零构建视觉系统,即可借助云端推理实现智能升级。
未来展望:具身智能的广阔蓝图
Gemini Robotics-ER 1.6的发布,只是具身AI浪潮的起点。未来,机器人将深入家庭、医疗、物流等领域:家庭助手能自主整理杂物并判断清洁完成度;医疗机器人能在手术室精确读取设备读数;物流中心则实现全自主分拣与安全避障。
挑战依然存在,如长时序任务的记忆保持、极端环境适应性和跨机器人平台通用性。但1.6版本证明,通过空间推理+代理视觉的路径,这些难题正逐步被攻克。DeepMind的邀请也释放信号:开放合作、共同迭代,将加速行业进步。
最终,Gemini Robotics-ER 1.6不止是一次模型升级,更是AI与物理世界深度融合的里程碑。它让机器人真正"看见"世界、"理解"世界,并"安全行动"于世界。伴随5G、边缘计算和硬件进步,我们正站在机器人智能爆发的门槛上。未来已来,值得每一位技术从业者和产业决策者共同期待。