摘要:八部门发布推动工业互联网高质量发展的实施意见,把工业互联网从“连接工程”推向“工业AI基础设施工程”。2.5万亿目标背后,真正要建设的是网络、平台、数据、安全和产业生态协同运转的工业智能底座。

八部门这次把工业互联网重新放到了一个更高的位置。
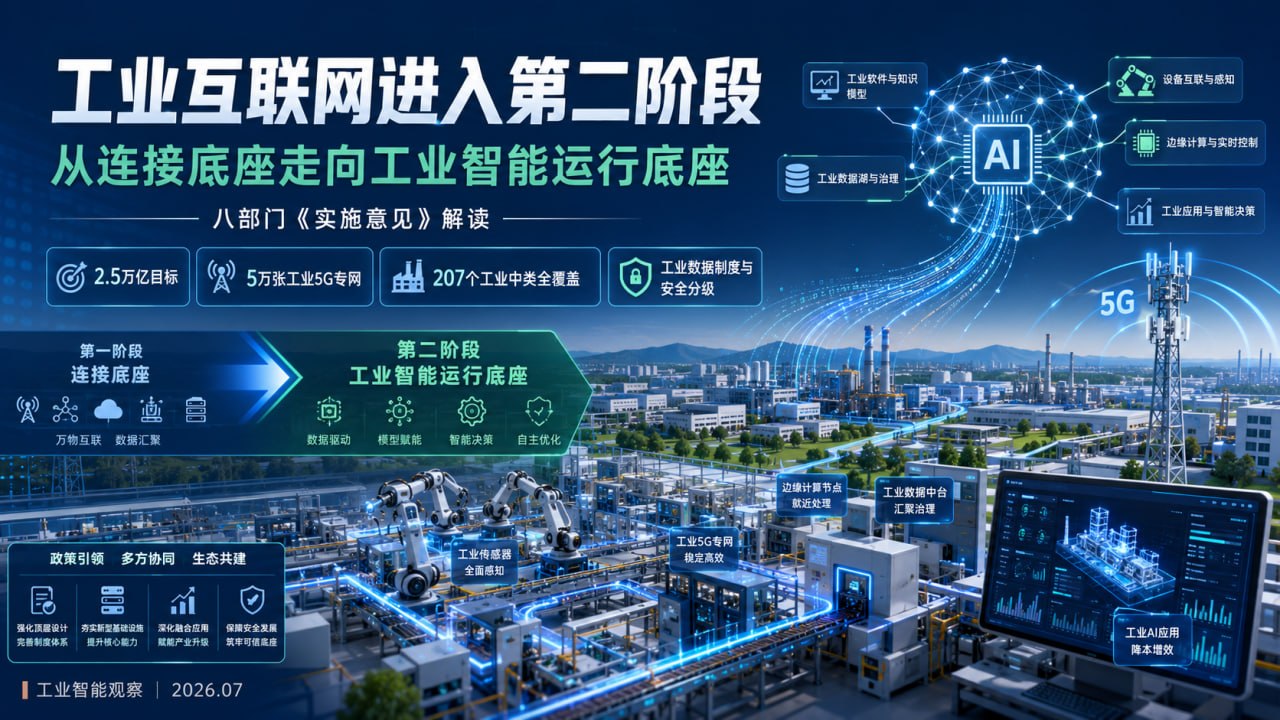
工信部等八部门联合发布《关于推动工业互联网高质量发展的实施意见》,提出到2030年工业互联网核心产业增加值突破2.5万亿元,并把工业5G专网、工业互联网平台、工业数据制度、安全分类分级和产业生态一起纳入目标体系。
这不是简单给工业互联网再定一个产业规模指标。
更准确地说,它标志着工业互联网的政策重心正在发生变化:过去几年重点解决“连起来、上平台、建标识、做示范”,下一阶段要解决的是“能不能支撑工业AI规模化落地”。工业互联网不再只是数字化转型的连接底座,而要成为工业智能的运行底座。
2.5万亿目标背后,是工业互联网进入第二阶段
过去谈工业互联网,关键词常常是设备联网、数据采集、标识解析、上云上平台、智能工厂示范。它解决的是工业数字化的第一层问题:让机器、产线、工厂、软件系统和供应链能够被连接、被感知、被管理。
这一步很重要,但还不够。
如果工业互联网只停留在“连接”和“看板”,企业很容易陷入一种尴尬:屏幕越来越多,数据越来越多,系统越来越多,但真正进入研发、工艺、排产、质量、能耗、设备维护和供应链协同的智能化能力并不够强。很多项目最后变成展示工程,而不是生产力工程。
这次《实施意见》的信号,是工业互联网要从第一阶段的连接型基础设施,转向第二阶段的智能型基础设施。
所谓核心产业增加值突破2.5万亿元,不能只理解为产业规模扩张。它背后真正对应的是一整套产业能力:工业网络、工业软件、工业数据、工业模型、边缘计算、安全体系、平台服务商、行业解决方案商,都要能支撑更大范围、更深程度的工业智能应用。
换句话说,工业互联网未来值不值2.5万亿元,不取决于平台数量和大屏数量,而取决于它能不能让制造业真正获得可复制的智能化能力。
5万张工业5G专网,解决的是工业AI的现场入口
《实施意见》提出,到2030年建设5万张工业5G专网。
这个指标看起来是通信指标,实际上是工业AI的现场入口指标。
工业AI和消费互联网AI最大的不同,是它必须进入现场。模型不能只在云端回答问题,还要接触设备、产线、传感器、视觉系统、机器人、PLC、MES、SCADA和能源系统。现场数据如果上不来,控制指令如果下不去,边缘推理如果跑不稳,工业AI就只能停留在办公辅助和知识问答层。
工业5G专网的价值,就在于把连接能力从“可用”推进到“可生产”。它要解决低时延、稳定性、隔离性、可靠性和现场覆盖问题。
这对很多工业场景非常关键。视觉质检需要实时回传图像和推理结果;AGV和移动机器人需要稳定连接;矿山、港口、化工、钢铁等场景需要在复杂环境里保持通信可靠;柔性产线需要设备之间更快协同。没有现场网络,所谓工业智能就很难闭环。
所以,5万张工业5G专网不是孤立的网络建设任务,而是在给工业AI铺设“进入车间的路”。
207个工业中类全覆盖,意味着试点时代要结束
文件提出,融合应用要实现207个工业中类全覆盖。
这句话值得重视。
过去工业互联网和智能制造项目,最容易集中在少数基础好、数字化程度高、投资能力强的行业,比如汽车、电子、钢铁、化工、装备制造。它们能做样板,但很难代表中国制造业的全貌。
207个工业中类全覆盖,意味着政策不满足于几个灯塔工厂和头部企业案例,而是要把工业互联网从示范工程推向普及工程。
这会带来一个很现实的挑战:不同行业的工艺差异太大。食品饮料、纺织服装、建材、医药、机械加工、电子装配、能源化工,对数据、控制、质量、安全和合规的要求完全不同。一个通用平台很难直接复制到所有行业。
因此,下一阶段工业互联网竞争的关键,不是平台讲得多大,而是能不能沉到行业里。平台企业要懂行业工艺,解决方案商要能把模型和设备结合,地方政府要围绕本地产业集群设计场景清单,制造企业也要把工艺知识和数据治理拿出来,而不是只等外部厂商交钥匙。
工业AI真正难的地方,也正在这里:它不是把通用大模型搬进工厂,而是把行业知识、工艺规则、现场数据和安全约束组织成可执行系统。
工业数据制度,是工业AI能不能跑起来的燃料系统
这次文件里,工业数据制度体系被放到了很重要的位置。
这非常准确。
工业AI的最大瓶颈之一,不是没有模型,而是没有可用的数据。很多企业有数据,但分散在设备、表格、MES、ERP、PLM、质量系统和供应链系统里;有些数据格式不统一,有些没有标注,有些质量差,有些涉及商业机密和安全边界,不能随便流通。
结果就是,模型看起来很强,一到工厂就缺燃料。
工业数据制度要解决的,正是数据从“沉睡资源”变成“可用资产”的问题。它至少包括几个层面:
第一,数据采集和标准化。设备数据、工艺数据、质量数据、能耗数据和维修数据必须能被统一描述。
第二,数据权属和使用边界。谁拥有数据,谁可以使用,使用到什么程度,是否可以跨企业、跨平台、跨区域流通,都要有规则。
第三,数据安全和可信流通。工业数据涉及产能、配方、工艺、供应链和安全生产,不能简单照搬互联网数据流通模式。
第四,高质量数据集建设。工业AI不是只靠海量文本训练,而需要高质量、可验证、贴近工艺流程的数据集。
如果这些问题不解决,工业AI就会长期停留在“演示可以,规模化困难”的状态。
安全分类分级,是工业AI进入生产系统的前提
《实施意见》提出,重点行业规上工业企业安全分类分级普及率达到80%。
这不是附属指标,而是工业AI能否进入生产系统的前提。
消费互联网应用出错,最多是体验不好;工业系统出错,可能影响设备、产线、产品质量、安全生产和供应链交付。越是把AI接入工业现场,越不能只看模型能力,还必须看权限边界、责任边界和安全边界。
尤其是未来工业智能体如果进入排产、运维、质检、能耗优化、设备控制等环节,就必须明确哪些建议只能供人参考,哪些操作可以半自动执行,哪些操作绝不能由模型直接触发。
安全分类分级的价值,就在于把工业互联网应用按风险程度分层管理。高风险场景要有更严格的隔离、审计、回滚和人工复核机制;低风险场景可以更快试点。这样工业AI才能在不牺牲安全的前提下逐步进入核心流程。
工业AI要真正落地,不能只有“智能”,还要有“可控”。
对地方和企业来说,抓手不在口号,在场景清单
这份文件对地方政府和制造企业最大的启发,是不要再把工业互联网当成抽象工程。
地方要抓,不应只抓平台数量和投资额,而应抓本地产业链中的关键场景:哪个行业的设备停机成本最高,哪个工序最缺质量检测,哪个环节最依赖老师傅经验,哪个企业最需要节能降耗,哪个园区最适合建设工业5G专网和边缘算力节点。
企业要抓,也不应从“大模型战略”开始,而应从业务痛点开始。
比如:
- 设备维护能不能从事后维修转向预测性维护;
- 质量检测能不能从抽检转向在线全检;
- 工艺参数能不能从经验调整转向数据驱动优化;
- 能耗管理能不能从月度统计转向实时优化;
- 生产排程能不能把订单、库存、设备状态和交付约束联动起来;
- 老员工的经验能不能沉淀成工艺知识库和操作规程智能助手。
这些场景不一定听起来宏大,但只要能闭环,就比空泛的平台建设更有价值。
这轮工业互联网,不该再做成“数字化外壳”
这次政策最值得警惕的风险,是各地把它重新做成一轮“上平台、建大屏、报项目”的数字化外壳。
工业互联网真正难的部分,不在采购系统,而在改造流程;不在展示数据,而在改变决策;不在建一个平台,而在让平台进入研发、生产、质量、设备、供应链和能源管理的日常运行。
如果只是为了完成指标,企业可能会买系统、接设备、做驾驶舱,但生产方式没有变,工艺知识没有沉淀,数据没有治理,AI没有进入闭环,最后仍然只是多了一层软件壳。
相反,真正有价值的建设应该有几个特征:
一是从单点场景切入,但能持续扩展到流程。比如先做视觉质检,再打通质量追溯、工艺调整和供应商管理。
二是从数据治理开始,而不是从模型炫技开始。没有干净、可信、可解释的数据,模型越强越容易失真。
三是保留现场安全边界。工业AI要先从辅助决策、异常发现、知识检索、方案生成做起,再逐步进入自动执行。
四是形成可量化收益。节省多少停机时间,降低多少返工率,提高多少良品率,减少多少能耗,这些指标比平台宣传更重要。
结语:工业AI的竞争,先是底座竞争
八部门这份《实施意见》真正释放的信号,是工业AI开始进入底座建设阶段。
未来几年,很多企业都会谈工业大模型、工业智能体、智能工厂、具身智能和柔性制造。但这些能力要跑起来,必须先有稳定网络、工业数据、平台生态、安全制度和行业场景。
工业互联网就是这些能力的承载层。
所以,“2.5万亿工业互联网”不只是一个产业目标,而是一个判断框架:谁能把网络、数据、模型、软件、设备和安全治理真正组织起来,谁才有可能把工业AI从概念变成生产力。
对中国制造业来说,这一轮竞争不会只属于模型公司,也不会只属于设备厂商。真正的机会在那些能把工业现场、工业软件、工业数据和AI能力打通的企业和区域。
工业AI的上半场看模型,下半场看底座。