摘要:2026 年 6 月 10 日,PgDog 宣布获得 550 万美元融资,投资方包括 Basis Set、Y Combinator、Pioneer Fund 等。官方公告给出的定位很明确:PgDog 不是要替换 PostgreSQL,而是在 PostgreSQL 前面放一个代理层,让"同一个 Postgres"具备连接池、读写路由、负载均衡和分片能力。项目方还披露,PgDog 已在生产环境中服务超过 200 万 QPS、覆盖数十个部署,并处理了超过 20 TB 的已知分片数据[^1](PgDog)。
2026 年 6 月 10 日,PgDog 宣布获得 550 万美元融资,投资方包括 Basis Set、Y Combinator、Pioneer Fund 等。官方公告给出的定位很明确:PgDog 不是要替换 PostgreSQL,而是在 PostgreSQL 前面放一个代理层,让"同一个 Postgres"具备连接池、读写路由、负载均衡和分片能力。项目方还披露,PgDog 已在生产环境中服务超过 200 万 QPS、覆盖数十个部署,并处理了超过 20 TB 的已知分片数据[^1](PgDog)。
这件事有意思的地方,不只是"又一个数据库基础设施项目拿到融资"。它更像是 PostgreSQL 生态长期矛盾的一次集中显影:Postgres 越来越像默认数据库,但默认数据库并不等于默认可以水平扩展。
PostgreSQL 的成功,也放大了它的边界
过去十多年,很多团队选择 PostgreSQL 的理由很直接:事务、SQL、索引、JSON、扩展生态、运维经验、云服务支持都足够成熟。它能覆盖从后台管理系统、SaaS 多租户,到金融、电商、地理空间、队列和分析型查询的一大块需求。
但 PostgreSQL 的经典部署模型,仍然很大程度围绕"一个主库 + 若干只读副本"展开。PostgreSQL 官方文档在高可用与负载均衡章节中也把问题分得很清楚:多个数据库服务器可以用于主库故障接管,或让多台机器服务同一份数据;只读数据库服务器相对容易被组合起来做负载均衡[^2](PostgreSQL)。流复制可以让 standby 持续接收 primary 产生的 WAL 记录,但默认是异步的,提交后到副本可见之间仍可能有延迟[^3](PostgreSQL)。
这意味着,Postgres 的"读扩展"相对清晰:加副本、做读写分离、控制复制延迟。但"写扩展"就没有那么优雅。一个 primary 的 CPU、IOPS、锁竞争、WAL 写入、autovacuum 压力和连接数上限,迟早会变成瓶颈。到了那个时候,团队通常会面临几个选择:继续垂直扩容,拆服务,应用层分片,使用 Citus 这类扩展,迁移到另一种分布式数据库,或者在数据库前面引入一个更聪明的代理层。
PgDog 瞄准的正是最后这个位置。
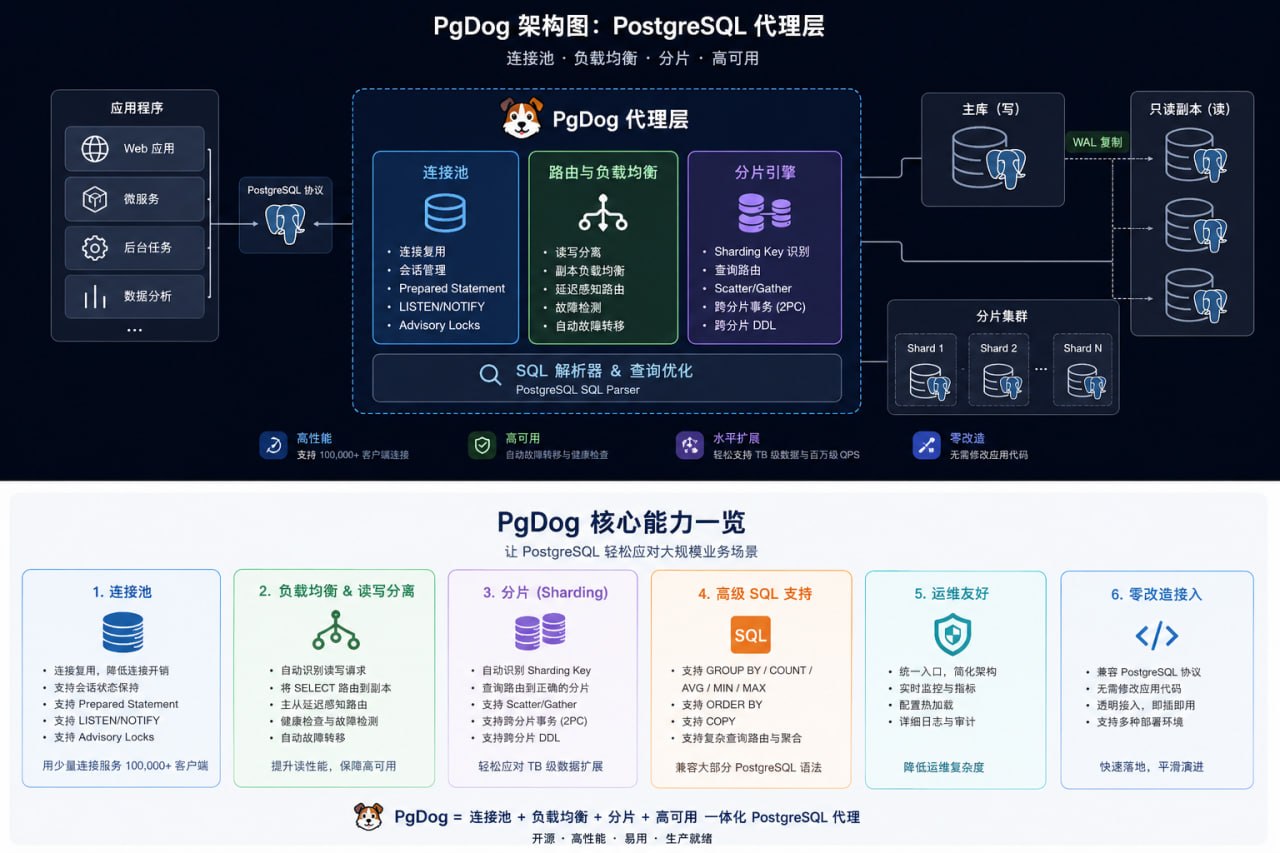
PgDog 架构图:作为 PostgreSQL 代理层,提供连接池、负载均衡、分片和高可用能力(图源:PgDog / 自制信息图)
从连接池到代理层:Postgres 扩展史的一条暗线
PostgreSQL 生态里,"代理"并不是新东西。最广为人知的是 PgBouncer,它的定位一直很克制:轻量级 PostgreSQL 连接池。PgBouncer 的价值在于把大量客户端连接复用到较少的后端数据库连接上,缓解连接创建、进程资源和内存占用压力。PgBouncer 官方主页也直接把它称为 PostgreSQL 的 lightweight connection pooler[^4](PgBouncer)。
再往复杂一些,是 Pgpool-II。它不只是连接池,还覆盖负载均衡和高可用。Pgpool-II 官方将其描述为面向 PostgreSQL 的开源中间件,提供 connection pooling、load balancing 和 high availability[^5](Pgpool-II)。在流复制模式下,Pgpool-II 会根据查询类型决定应该把请求发往 primary 还是 standby,例如 INSERT、UPDATE、DELETE 等写操作只能发往 primary,而部分 SELECT 可以被发往 standby[^6](Pgpool-II)。
云厂商也做了自己的版本。Amazon RDS Proxy 的核心价值同样是连接池和故障韧性:它可以让应用共享数据库连接、缓解突发连接流量,并在数据库故障时自动连接到 standby,同时尽量保留应用连接[^7](AWS 文档)。但 RDS Proxy 也有边界,比如 AWS 文档列出的 PostgreSQL 限制包括不支持 session pinning filters、不支持客户端 CancelRequest,以及当前不支持 streaming replication mode[^8](AWS 文档)。
这些工具解决了 PostgreSQL 扩展问题的一部分,但没有彻底解决"一个 Postgres 集群如何像一个逻辑数据库一样横向扩展"的问题。连接池解决连接风暴,读写分离解决读压力,高可用代理解决故障切换;真正难的是分片、跨分片事务、DDL、schema 演进、查询路由、热点数据、数据迁移和再均衡。
PgDog 的切入点:把 Postgres 代理做成"数据库入口"
PgDog 官方文档把自己定义为 PostgreSQL 的 sharder、connection pooler 和 load balancer;它用 Rust 编写,目标是在不修改应用代码的前提下实现水平扩展[^9](docs.pgdog.dev)。这个定位比传统连接池更激进:PgDog 不是只在连接层省资源,而是试图成为应用和多个 Postgres 实例之间的"数据库入口"。
从功能拆开看,PgDog 有三层含义。
第一层是连接池。 PgDog 宣称可以用少量 Postgres 连接服务 100,000+ 客户端,并支持 session state、advisory locks、LISTEN/NOTIFY 和 prepared statements 等场景[^1](PgDog)。这说明它并不只是做简单 TCP 转发,而是要理解 PostgreSQL 协议和会话状态,否则连接复用很容易被 prepared statement、临时表、事务状态或 session 参数击穿。
第二层是负载均衡和高可用。 PgDog 官方称其可以在副本之间分发读请求,检测复制延迟、硬件故障和 primary failover,并通过一个统一 endpoint 暴露给应用;它还使用内部 PostgreSQL SQL parser 做读写拆分,把 SELECT 路由到副本,把其他请求路由到 primary[^1](PgDog)。这类能力的关键不只是"能不能转发",而是"什么时候不能转发":复制延迟、事务隔离级别、SELECT FOR UPDATE、函数副作用、临时对象、session 状态,都会让读写分离变得复杂。
第三层是分片。 PgDog 的官方描述是:它可以从查询中提取 sharding key,并把请求发送到正确 shard;没有 sharding key 的查询会被并行发送到所有数据库,即 scatter/gather。它还声称支持 GROUP BY、COUNT、AVG、ORDER BY、MIN、MAX、COPY 等操作,并提供跨分片事务、复制表、整数主键生成、sharding key mutation 和跨分片 DDL[^1](PgDog)。
这就是 PgDog 与 PgBouncer、RDS Proxy 的最大差异:它想从"连接基础设施"进入"分布式查询协调器"的位置。
为什么这个方向现在又热了?
原因并不神秘:PostgreSQL 被用得太广了。
当一个数据库成为事实上的默认选择,组织的第一反应通常不是"换数据库",而是"能不能继续撑一撑"。尤其是已经有大量 SQL、ORM、迁移脚本、监控告警、备份恢复流程、权限模型和 DBA 经验的团队,迁移到另一个数据库的成本非常高。PgDog 官方公告里甚至直白地说,MongoDB、DynamoDB 这类数据库存在的原因之一,是 Postgres 有扩展问题;他们的目标是让 Postgres 在 100 TB+ 表和百万级 QPS 下也"just work"[^1](PgDog)。
这句话当然带有创业公司式的锋芒,但它抓住了一个真实需求:很多业务并不是一开始就想要分布式数据库。它们只是先用了 PostgreSQL,然后业务增长、租户增长、订单增长、地理范围增长,最后发现"单主库"正在变成组织瓶颈。
PgDog 创始人在公告里提到,他曾在 Instacart 运行 PostgreSQL,并在 2020 年 4 月参与支撑公司 5 倍增长;当时的核心问题,是让 Postgres 服务每分钟数十万级的 grocery delivery orders[^1](PgDog)。这类背景对基础设施产品很重要,因为数据库扩展不是实验室问题,而是凌晨三点的故障切换、版本升级、慢查询雪崩和连接风暴问题。
但代理层不是魔法
对 PgDog 最好的态度,不是把它当作"PostgreSQL 终于分布式了",而是把它看成"把一部分分布式复杂性从应用层搬到了代理层"。
这件事有价值,但不会消灭复杂性。
分片首先是数据建模问题。 你要选 sharding key,要理解热点租户,要处理跨租户查询,要决定哪些表复制、哪些表分片、哪些表保留在单库。选错 sharding key,代理层也只能帮你把错误路由得更快。
其次是事务问题。 PgDog 声称通过 PostgreSQL prepared transactions 和 two-phase commit 支持跨分片事务[^9](docs.pgdog.dev)。这对兼容性很重要,但 2PC 的代价也很现实:参与者越多,延迟越高,故障恢复越复杂,悬挂事务和锁保留都需要被认真监控。也就是说,支持跨分片事务不等于鼓励你把每个请求都写成跨分片事务。
再次是再分片和迁移问题。 Hacker News 讨论里就有评论指出,即便有 PgDog 这样的代理,Postgres 分片故事也没有完全解决;对于已经达到 TB 级的数据库,用逻辑复制做 resharding 可能很难追上,应用层分片在某些场景下仍然更灵活[^10](Hacker News)。这类质疑很关键:数据库横向扩展最难的往往不是第一次切分,而是业务继续增长后的二次、三次迁移。
最后是代理本身的可靠性。 代理层一旦成为唯一入口,就必须具备和数据库同等级别的可观测性、灰度升级能力、配置回滚能力、流量隔离能力和故障演练机制。否则,原来数据库是单点,现在代理也可能成为新的单点。
与 Citus、逻辑复制和应用层分片的关系
PgDog 也不应该被孤立地理解。PostgreSQL 的横向扩展路线大致可以分成三类。
一种是扩展内核能力,例如 Citus。 Citus 是开源 PostgreSQL extension,可以把 PostgreSQL 转换为分布式数据库,实现跨多节点水平扩展[^11](微软学习)。Citus 文档中的模型是 coordinator + workers:应用把查询发给 coordinator,coordinator 根据元数据把查询路由到单个 worker 或并行发送到多个 worker[^12](docs.citusdata.com)。这条路线的优势是数据库内部知道更多元数据和执行计划,劣势是需要接受扩展和特定部署模型。
第二种是逻辑复制和迁移工具链。 PostgreSQL 逻辑复制基于 publication/subscription,可以复制数据对象及其变更,并常用于跨版本、跨平台、子集复制或数据汇总[^13](PostgreSQL)。但逻辑复制也有明确限制,例如 schema 和 DDL 不会自动复制,后续 schema 变更需要手动保持同步;sequence 数据也不会作为 sequence 本身复制[^14](PostgreSQL)。所以它是重要基础设施,但不是完整的自动分片方案。
第三种是应用层分片。 它最"土",也最可控。业务代码知道租户、用户、订单、地域、时间范围,因此可以做最贴合业务的路由。但代价是侵入性强,ORM、事务、报表、后台任务、迁移脚本都会被分片逻辑污染。很多团队最后不是不会做应用层分片,而是不想让这套复杂性扩散到整个工程组织。
PgDog 的赌注是:把足够多的 SQL 和 PostgreSQL 协议语义放到代理层,使应用层可以少改甚至不改。这是一个非常诱人的方向,也是一条工程难度很高的路。
开源商业化的微妙平衡
这次融资之后,社区自然会关心:PgDog 会不会走向"核心开源、关键能力商业化"的老路?
在 Hacker News 讨论里,PgDog 创始人回应称,Enterprise Edition 的两大方向是多节点部署控制平面,以及用于自动阻断坏查询、防止数据库被拖垮的 QoS;同时他表示"sharding / running Postgres at scale"会始终开源,而"让 PgDog 更容易大规模运行的基础设施管理"属于 enterprise[^10](Hacker News)。
这个切分相对合理。数据库代理的核心能力如果不开源,很难获得底层用户信任;但生产环境中的控制平面、SLA 支持、自动化部署、审计、QoS 和托管体验,确实是企业愿意付费的部分。问题在于,这条边界能否长期保持清晰。基础设施公司最难的不是第一天承诺什么,而是几年后在增长压力、投资人预期和社区信任之间如何取舍。
一个更大的信号:Postgres 正在被"系统化"
PgDog 获得融资,表面上是一个代理项目的新闻;更深层看,是 PostgreSQL 生态继续系统化的信号。
过去的 Postgres 生态更像"一个强大的单体数据库 + 一组周边工具":PgBouncer 管连接,Patroni 或云厂商管故障切换,Pgpool-II 管中间件能力,逻辑复制管数据流,Citus 管分布式扩展,应用代码管业务路由。现在越来越多项目试图把这些能力重新组合,形成更接近"数据库平台"的体验。
PgDog 代表的是其中一种路线:不改 Postgres 内核,不强依赖特定云,不要求应用大改,而是在代理层吸收复杂性。它的优势是部署位置灵活,理论上可以跑在 RDS、Aurora、EC2、自建机房或本地环境中;PgDog 官方也强调可以部署在用户自己的云、colo、on-prem 或 laptop 上[^1](PgDog)。
但数据库基础设施的判断标准最终很朴素:故障时能不能稳住,升级时能不能不中断,慢查询能不能隔离,复制延迟能不能感知,分片后能不能继续迁移,出了问题能不能解释清楚。
融资验证的是市场兴趣,不是技术终局。PgDog 值得关注,因为它抓住了 PostgreSQL 用户最真实的痛点:大家想继续用 Postgres,但不想继续手写一套脆弱的分片和故障切换系统。
如果 PgDog 能把连接池、读写分离、failover、SQL 路由和分片协调真正做成可靠的开源基础设施,它可能会成为 PostgreSQL 横向扩展路线里的重要一环。反过来,如果它低估了 SQL 兼容性、跨分片事务和再分片迁移的复杂性,它也会再次证明数据库领域那句老话:所有看似消失的复杂性,最后都会在某个更隐蔽的层面重新出现。
[^1]: PgDog - Official website, https://pgdog.dev
[^2]: PostgreSQL - High Availability, Load Balancing, and Replication, https://www.postgresql.org/docs/current/high-availability.html
[^3]: PostgreSQL - Streaming Replication, https://www.postgresql.org/docs/current/warm-standby.html#STREAMING-REPLICATION
[^4]: PgBouncer - About, https://www.pgbouncer.org
[^5]: Pgpool-II - About, https://pgpool.net
[^6]: Pgpool-II - Load Balancing Configuration, https://www.pgpool.net/docs/latest/en/html/runtime-config-load-balancing.html
[^7]: AWS - Using RDS Proxy, https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/rds-proxy.html
[^8]: AWS - RDS Proxy limitations for PostgreSQL, https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/rds-proxy-limitations.html
[^9]: PgDog - Documentation, https://docs.pgdog.dev
[^10]: Hacker News - PgDog discussion, https://news.ycombinator.com/item?id=42540746
[^11]: Microsoft Learn - Hyperscale server group architecture, https://learn.microsoft.com/en-us/azure/postgresql/hyperscale/concepts-hyperscale-nodes
[^12]: Citus - Sharding, https://docs.citusdata.com/en/stable/reference/sharding.html
[^13]: PostgreSQL - Logical Replication, https://www.postgresql.org/docs/current/logical-replication.html
[^14]: PostgreSQL - Logical Replication Restrictions, https://www.postgresql.org/docs/current/logical-replication-restrictions.html