摘要:Higgs Audio v3 TTS 的重点不只是把文字读得更自然,而是把 TTS 放进 voice agent 的实时工程语境:流式合成、内联控制、多语言声音保持、零样本声音克隆和可服务化推理,正在把语音模型从“文本到声音”推向“对话到表达”。

最近 Boson AI 发布了 Higgs Audio v3 TTS,一个面向语音聊天场景的文本转语音模型。它的关键词很明确:约 4B 级别自回归 decoder、基于 Qwen3-4B backbone、支持 100 多种语言、面向 voice agent、支持零样本声音克隆,并且可以通过文本流中的内联控制标签调整情绪、风格、语速、音高、停顿和音效。(LMSYS / SGLang-Omni 发布说明、Hugging Face 模型卡)
如果只把它看成“又一个 TTS 模型”,其实低估了这次发布的意义。过去 TTS 的核心任务是把一段已经写好的文本读出来,追求的是发音准确、音色自然、停顿合理。Higgs Audio v3 代表的方向则更进一步:TTS 不再只是大模型回答之后的最后一步,而是实时语音智能体的一部分。它要在一句话还没有完全生成时就开始说话,要根据上下文调整情绪,要能在多轮对话中保持声音身份稳定,还要让开发者用类似提示词的方式控制语音表现。
这意味着语音 AI 的技术重心正在发生变化:从“文本到声音”转向“对话到表达”。
一、为什么语音聊天需要新的 TTS 架构
传统 TTS 很多时候假设输入是一段完整文本。系统先拿到整句或整段话,再做分词、韵律预测、声学建模和声码器合成。这种模式适合有声书、播报、导航、客服话术等稳定场景,但不一定适合实时语音智能体。
语音聊天的输入是不完整的。大模型可能一边生成文本,一边把文本流式输出。如果 TTS 必须等整段回答生成结束再说,用户体验就会出现明显延迟。如果 TTS 提前开口,又要面对另一个问题:前半句还不知道后半句是什么,语气、重音、停顿很容易不自然。
Higgs Audio v3 的定位正是为了解决这种“边生成边说”的问题。官方说明强调,它面向真实 voice-agent 场景,可以在完整句子或标点尚未到来前开始合成,并在后续文本继续进入时保持说话人身份、情绪和语速的连贯性。(LMSYS / SGLang-Omni)
它不是简单地把完整文本送入合成器,而是把文本 token 和音频 token 放在统一的自回归生成流程里处理。模型可以交替接收文本和音频上下文,使后续音频片段既受当前文本约束,也受前面已经生成的声音状态约束。
这类架构对 voice agent 很重要。因为用户真正感受到的不是“模型回答得对不对”这么简单,而是它是否像一个正在交流的人:是否会停顿,是否会强调,是否会在惊讶时显得惊讶,在解释时显得沉稳,在道歉时显得克制。
语音不是文本的附属品,而是交互本身。
二、技术核心:音频 token 化与多码本生成
Higgs Audio v3 的一个关键点是音频离散化。它使用 Higgs Tokenizer 将音频编码成离散 token,并采用 8 个 codebook,以 25 fps 的帧率表示音频。简单说,就是把连续波形压缩成一组模型可以像语言 token 一样处理的符号序列。
这背后有一个重要趋势:现代 TTS 越来越像“音频语言模型”。过去语音合成更像信号处理与声学模型问题;现在,音频被 token 化以后,就可以进入大语言模型类似的自回归生成框架。文本 token 描述“说什么”,音频 token 描述“怎么说”。两者在同一个序列里建模,模型就有机会学习文本语义、说话风格、情绪节奏和声学细节之间的对应关系。
Higgs Audio v3 的官方资料中提到,它使用约 4B 参数的自回归 decoder,基于 Qwen3-4B backbone,包含多码本融合 embedding 和多码本输出 head。音频 token 经过延迟模式排列,再被映射到 backbone 的隐藏状态中,最后解码回 24 kHz 波形。(LMSYS / SGLang-Omni)
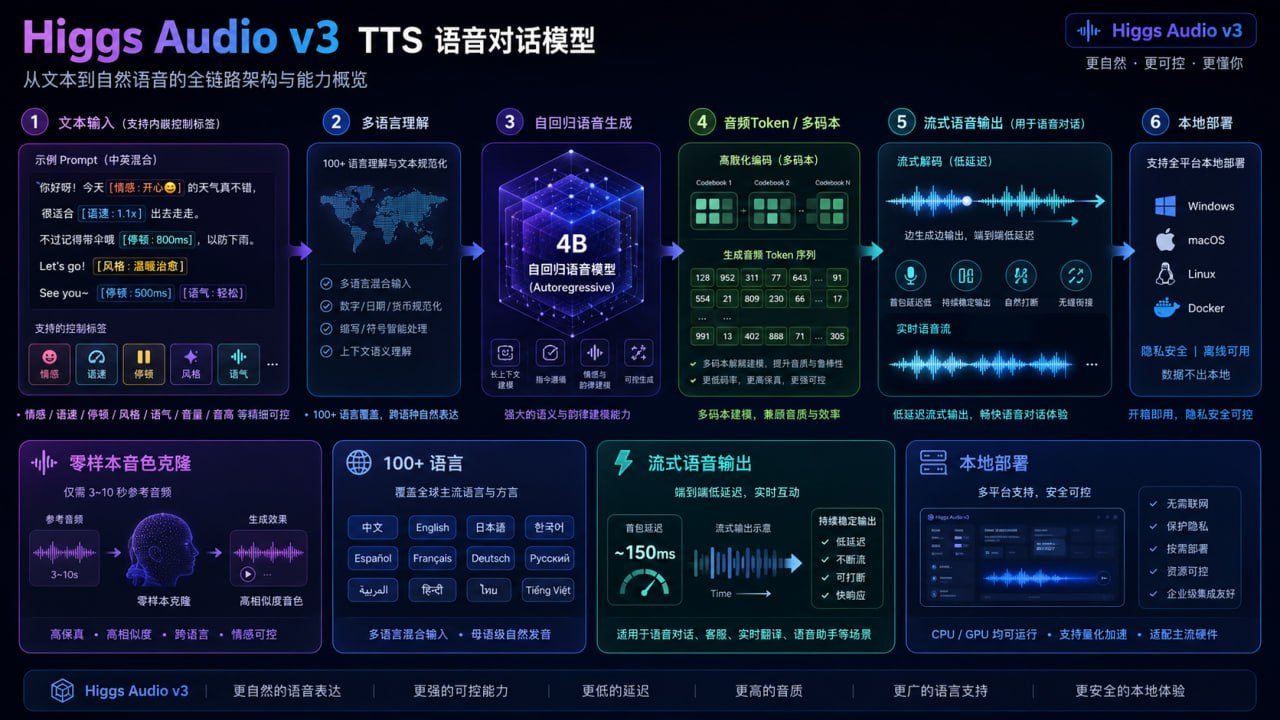
这套设计的意义在于,它不是单纯生成“声音”,而是在生成一个带有上下文记忆的声音流。前面说话的音色、节奏、情绪会影响后续生成;参考音频中的说话人特征也会影响当前输出。这正是零样本声音克隆、多轮语音对话和跨语言声音保持的基础。
三、内联控制:把语音控制变成文本协议
Higgs Audio v3 最值得开发者关注的功能,是内联控制标签。开发者可以把类似 <|emotion:amusement|>、<|prosody:speed_fast|>、<|style:whispering|>、<|sfx:laughter|> 这样的控制 token 直接插入输入文本,让模型在同一条语音中改变情绪、语速、音高、停顿和音效。模型卡也说明,情绪、风格、语速、音高这类全局 delivery token 通常放在输入开头,而停顿和音效类 token 可以放在需要触发的位置。(Hugging Face 模型卡)
这件事看似只是一个小功能,实际上很关键。过去要控制 TTS 的表现,往往需要额外参数、独立接口、SSML 标记、后处理规则,或者复杂的前端工程。现在它更像一种“语音提示词协议”:文本不仅包含内容,也包含表演指令。
例如,一个语音助手可以这样组织输出:前半句用平静语气解释问题,中间插入一个长停顿,后半句用更坚定的语气给出建议。客服机器人可以在道歉时降低语速,在确认订单时提高语调,在播报风险提示时切换到更严肃的表达。教育应用可以让同一个知识点用“老师讲课”“朋友解释”“儿童故事”等不同风格说出来。
这会改变应用层的开发方式。未来做语音产品,不只是调用一个 TTS API,而是要设计一套“语音表达策略”:什么场景该快,什么场景该慢,哪些词要强调,什么时候要停顿,情绪如何随对话状态变化。语音交互的产品经理和提示词工程师,可能会变成同一类岗位。
四、多语言能力:从“支持语言”到“可用语言”
Higgs Audio v3 宣称支持 100 多种语言,并在多语言测试中达到较低的 WER/CER。SGLang-Omni 发布说明中提到,Boson AI 的内部 Higgs-Multilingual 测试覆盖 111 种语言和方言,v3 在 100 种语言上达到个位数 WER/CER;模型卡也列出 Seed-TTS、CV3、MiniMax-Multilingual 和 Higgs-Multilingual 等基准结果。(LMSYS / SGLang-Omni、Hugging Face 模型卡)
这里需要注意,TTS 的“支持语言”不是简单能发出声音,而是要看三个层次。
第一是可懂度,也就是说出来的内容是否能被正确识别。第二是自然度,也就是听起来是否像人,而不是机械拼接。第三是表达一致性,也就是跨语言时能否保持同一个说话人的音色和情绪。
对语音智能体来说,第三点尤其重要。因为全球化应用中,一个用户可能希望同一个 AI 助手能在中文、英文、日文、西班牙语之间切换,但声音身份不要频繁变化。过去多语言 TTS 经常出现的问题是:中文一个声音,英文一个声音,换语言就像换人。Higgs Audio v3 的零样本声音克隆和跨语言生成能力,正是向“一个声音说多种语言”的方向推进。
这对企业应用有现实价值。跨境客服、在线教育、游戏 NPC、虚拟主播、实时翻译、智能硬件,都不希望为每种语言重新制作完整音库。如果一个模型可以用短参考音频迁移音色,再在多语言上保持较低错误率,语音产品的本地化成本会明显下降。
五、SGLang-Omni:真正难点在推理服务
大模型语音合成不只是模型权重问题,更是推理系统问题。Higgs Audio v3 的本地 serving 支持放在 SGLang-Omni 上,这一点很值得关注。
语音模型的推理不同于普通文本模型。它既要处理文本 token,又要处理多码本音频 token;既要关注吞吐,又要关注首包延迟;既要保证生成质量,又要支持流式输出。对于实时语音智能体来说,用户最敏感的是“多久能听到第一段声音”。如果模型质量很好,但要等几秒才开口,就很难进入真实对话场景。
SGLang-Omni 这类 serving 框架的价值在于,它把多阶段生成、连续批处理、多码本解码、流式返回等问题工程化。官方给出的测试显示,在 1 张 H100 上,Seed-TTS EN 全量测试中并发 16 时平均延迟约 1079 ms、RTF 约 0.262,低于实时播放时长;模型卡还展示了通过 Server-Sent Events 流式返回 base64 WAV 音频块的用法。(LMSYS / SGLang-Omni、Hugging Face 模型卡)
这说明 Higgs Audio v3 不只是一个离线 demo,而是朝着可服务化部署走了一步。
当然,这也意味着本地运行门槛并不低。4B 级语音模型加上音频解码链路,对显存、吞吐、并发和工程优化都有要求。个人开发者可以尝试,但企业要做生产级语音服务,还要考虑 GPU 成本、并发排队、音频缓存、失败重试、日志合规和内容安全。
六、从 v2 到 v3:重点从“表达力”转向“对话性”
Higgs Audio v2 已经在情绪表达、问题语调、多说话人对话等方面表现突出。v3 的变化,不只是指标提升,而是目标发生了转向。
v2 更像是在证明:开源或开放权重模型也可以做到高质量、强表达、多说话人。v3 则更像是在回答:如何让 TTS 成为实时语音智能体的基础组件。
这背后的差异很大。有声书 TTS 追求长文本稳定;播报 TTS 追求清晰准确;配音 TTS 追求情绪和音色;语音智能体 TTS 追求的是实时、可控、上下文一致、能和大模型生成流配合。它不只是“读得像人”,而是要“接话像人”。
这也是为什么内联控制和流式合成如此重要。一个真正的语音 agent,不能每次都像念稿。它需要根据用户打断、上下文变化、情绪状态和任务阶段调整说话方式。未来的语音模型评价,也不能只看 WER、MOS 或单句自然度,而要看多轮对话中的稳定性、响应延迟、情绪一致性和用户信任感。
七、应用前景:本地语音智能体的关键拼图
Higgs Audio v3 对本地 AI 应用有很强的启发。过去很多语音产品依赖云端 TTS 服务,优点是稳定、易用,缺点是成本、隐私和可控性受限。随着本地大语言模型、本地 ASR、本地向量库和本地 agent 框架逐渐成熟,TTS 是最后一块关键拼图。
一个完整的本地语音智能体,至少包括四层能力:语音识别把用户的话转成文本,大模型理解意图并调用工具,记忆和业务系统提供上下文,TTS 把回答自然说出来。Higgs Audio v3 这类模型的出现,使最后一层开始具备更强的本地化可能。
这对智能硬件、企业私有化部署、工业现场助手、车载语音、桌面机器人尤其重要。工业场景里,语音助手不能只会机械播报,它要能在嘈杂环境下用清晰语速提醒风险,在设备异常时用严肃语气给出操作建议,在培训场景里用更自然的节奏讲解流程。如果语音可以被内联控制,那么业务系统就能把“内容策略”和“表达策略”统一起来。
八、风险与边界:声音克隆必须有规则
不过,TTS 越强,风险也越明显。零样本声音克隆、多语言迁移和情绪控制,既可以用于客服、教育和辅助技术,也可能被用于冒充、诈骗、虚假宣传和深度伪造。Higgs Audio v3 的模型卡显示,它采用 Boson Higgs Audio v3 Research and Non-Commercial License;GitHub README 也明确说明,生产、托管或营收型使用需要单独商业授权。(Hugging Face 模型卡、GitHub README)
这一点不能被忽略。未来语音 AI 的竞争,不只是模型效果竞争,也是安全治理竞争。
真正可持续的语音应用,需要建立声音授权、音频水印、身份验证、敏感场景限制、日志审计和用户告知机制。尤其是在企业客服、金融交易、政务通知、医疗咨询等场景,声音越像真人,越需要清楚告诉用户“这是 AI”。
结语:TTS 的下一站是“可编排的声音智能”
Higgs Audio v3 TTS 的意义,不在于它又把语音合成指标往前推了一点,而在于它把 TTS 带入了 voice agent 的工程语境。
未来的语音模型不只是把文字念出来,而是要理解对话节奏、承载情绪表达、接受实时控制、适应多语言环境,并能被部署到实际应用链路中。语音将不再是 AI 系统的装饰层,而会成为人机交互的主入口。
从这个角度看,Higgs Audio v3 代表的不是单个模型的进步,而是一个趋势的清晰化:当大模型有了嘴巴,真正重要的不是它能不能说话,而是它能不能在正确的时间,用正确的语气,说出正确的话。