摘要:当大模型的基础能力越来越接近,真正决定企业价值的,不再只是模型本身,而是模型能不能进入企业内部,读懂那些从未出现在公开互联网上的数据。AI 时代真正稀缺的,不是公开知识,而是可调用、可治理、可闭环的私有数据资产。
埃里森这番话,不能只按“甲骨文创始人炮轰 AI 公司”来理解。说“大部分 AI 模型一文不值”当然带有夸张和商业修辞,但它击中了 AI 产业正在发生的结构性变化:当大模型的基础能力越来越接近,真正决定企业价值的,不再只是模型本身,而是模型能不能进入企业内部,读懂那些从未出现在公开互联网上的数据。在 Oracle 2026 财年第二季度电话会上,Ellison 明确把“公共数据训练”与“私有数据推理”区分开来,并称后者会成为更大、更有价值的业务;他还强调,Oracle 数据库和应用中沉淀着大量高价值私有数据。(The Motley Fool)
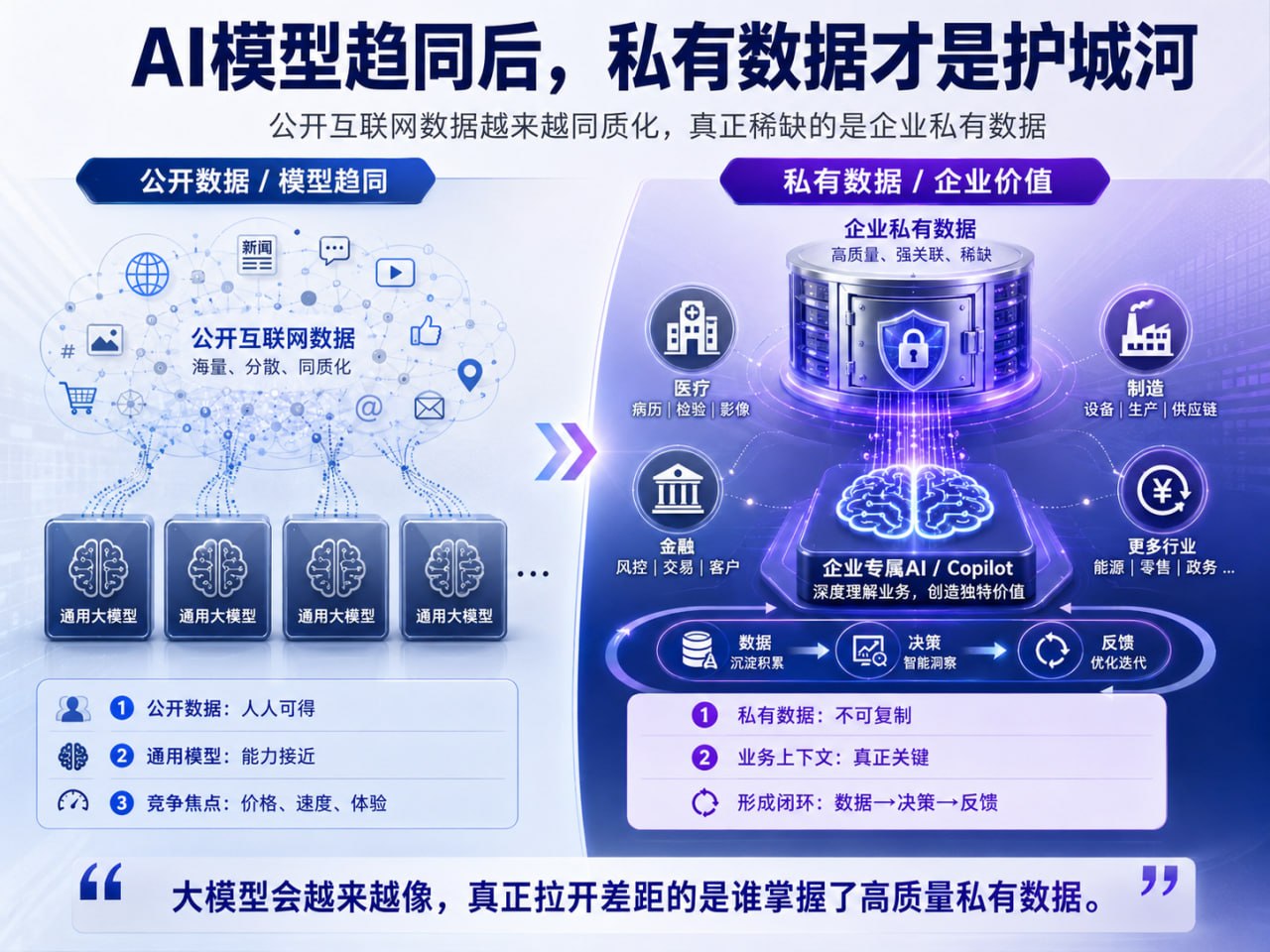
过去两年,AI 竞争像一场“公开知识”的军备竞赛。谁拥有更多 GPU,谁能抓取更多网页、论文、代码、论坛和图像,谁就有机会训练出更强的通用模型。这个阶段极其重要,因为它奠定了 AI 的语言、推理和多模态能力。但问题也在这里:公开互联网是一口大锅,顶尖公司都在从里面取水。即使配方不同、架构不同、后训练方法不同,只要食材高度重叠,模型之间的差异就会被持续压缩。最终,用户会发现:很多通用问题,ChatGPT、Gemini、Grok、Llama 都能回答;差别更多体现在速度、价格、上下文长度、生态和体验上,而不是不可替代的知识壁垒。
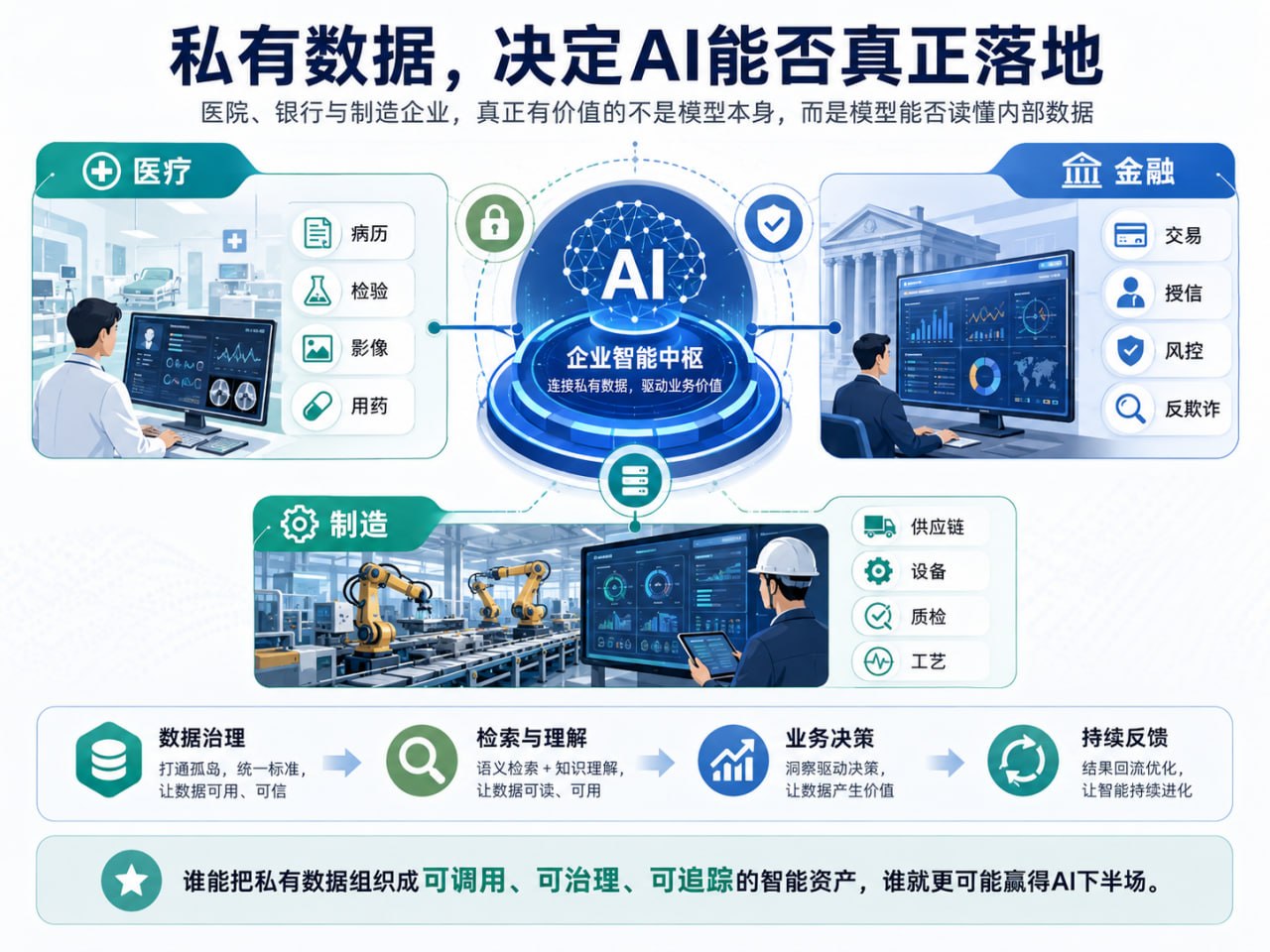
这正是私有数据开始显露价值的地方。公开数据回答的是“世界通常是什么样”,私有数据回答的是“我的世界正在发生什么”。一家医院真正需要的,不是一个会背医学教材的聊天机器人,而是能结合患者病史、检验指标、影像报告、用药禁忌和随访记录,帮助医生做判断的系统。一家银行真正需要的,也不是一个泛泛解释宏观经济的模型,而是能理解客户流水、风险敞口、授信历史、欺诈模式和监管约束的模型。制造业更是如此:供应商延迟、库存波动、设备传感器、质检缺陷、订单预测、售后反馈,构成了企业最真实的“商业神经系统”。
私有数据的第一层价值,是不可复制。互联网上的信息可以被所有人抓取,论文可以被所有人学习,开源代码可以被所有人吸收;但一家企业过去十年的交易记录、客户行为、生产异常、合同条款和内部知识库,竞争对手拿不到。它不是普通信息,而是企业经营活动留下的独占痕迹。模型越通用,私有数据越稀缺;模型越便宜,独占数据越昂贵。AI 时代的护城河,正在从“谁拥有模型”转向“谁拥有高质量、可调用、可治理的数据”。
第二层价值,是上下文。很多企业数据单独看并不惊人:一张工单、一条日志、一次回访、一笔退款、一份采购单,都像碎片。但当这些碎片被串起来,它们就呈现出因果关系:哪个客户即将流失,哪台设备会提前故障,哪类供应商会带来交付风险,哪种定价策略会影响毛利。大模型本身擅长理解语言和生成推理路径,但它不知道一家公司的真实约束。私有数据把模型从“会说话的百科全书”,变成“理解业务现场的助手”。
第三层价值,是反馈闭环。公开互联网数据大多是静态材料,而企业私有数据每天都在产生新的结果。销售建议发出后,客户有没有成交;风控模型拦截后,是否减少坏账;医疗提醒触发后,患者是否复诊;客服机器人介入后,投诉率是否下降。这些结果反过来又成为新的训练和评估信号。真正强大的企业 AI,不是一次性部署的工具,而是随业务持续学习的系统。谁能把“数据-决策-结果-再学习”闭环跑起来,谁就能让 AI 价值复利化。
不过,私有数据不是把病历、账本、合同和供应链文件一股脑喂给模型就能变成金矿。未经治理的数据,更像矿石甚至雷区。数据格式混乱、权限不清、口径冲突、历史记录缺失、敏感信息暴露,都会让 AI 从助手变成风险源。尤其在医疗、金融、政务和大型企业场景中,私有数据的价值必须建立在安全、合规、可审计、可撤回之上。所谓“让 AI 理解企业”,前提不是开放一切,而是让正确的模型,在正确的权限下,访问正确的数据,并留下可追责的轨迹。
这也是甲骨文此时强调私有数据的原因。Oracle 在分析师会议材料中把 AI 数据平台描述为把 AI 模型、公开数据和私有数据连接起来的结构,并强调通过 RAG 让模型获得训练时没有的数据,同时保持私有数据的私密性。其材料还进一步提出,AI 数据库可以把企业希望模型访问的私有数据向量化,让模型在检索相关数据后回答问题,并在公开与私有数据之上推理。换言之,甲骨文想把自己从“数据库供应商”重新叙事为“企业 AI 的数据入口”。这不是中立判断,而是清晰的商业战略。
从资本市场语境看,这个判断也不只是口号。Oracle 公布的 2026 财年第二季度结果显示,其剩余履约义务达到 5230 亿美元,同比上升 438%,云收入为 80 亿美元,同比上升 34%;这些数字说明,围绕 AI 基础设施、数据库和企业云的长期订单正在快速膨胀。(Oracle 投资者关系) 但更深层的逻辑是:算力和模型只是第一层租金,企业数据入口、权限体系、业务应用和长期工作流,才可能产生更持久的定价权。
对中国企业来说,启发尤其直接。很多公司今天的问题不是缺少大模型,而是没有把自己的数据变成 AI 可理解、可检索、可执行的资产。数据躺在 ERP、CRM、数据库、邮件、文档、会议纪要和个人电脑里,看似很多,实则彼此隔离。部门墙不拆,AI 就只能停留在写文案、做摘要、生成 PPT 的浅层应用;流程不重构,模型就无法真正参与审批、预测、调度、风控和研发;权限不清楚,企业越想用 AI,风险越大。
因此,“模型一文不值”这句话最准确的翻译也许是:没有专属数据的模型,越来越难拥有专属价值。大模型并不会消失,它会像电力、云计算和操作系统一样成为基础设施。但真正赚钱的应用,不会停留在问答界面,而会深入贷款审批、临床辅助、供应链调度、研发实验、客户经营和财务风控。那里没有公开互联网的标准答案,只有企业自己的数据、流程和责任。
未来的 AI 赢家,未必是每家公司都训练一个最大模型,而是谁能把私有数据安全地组织起来,变成模型可以推理、员工可以使用、系统可以执行的智能资产。公开数据训练出了 AI 的通用大脑,私有数据才会决定它能不能长出行业的眼睛、企业的手脚和商业的判断力。