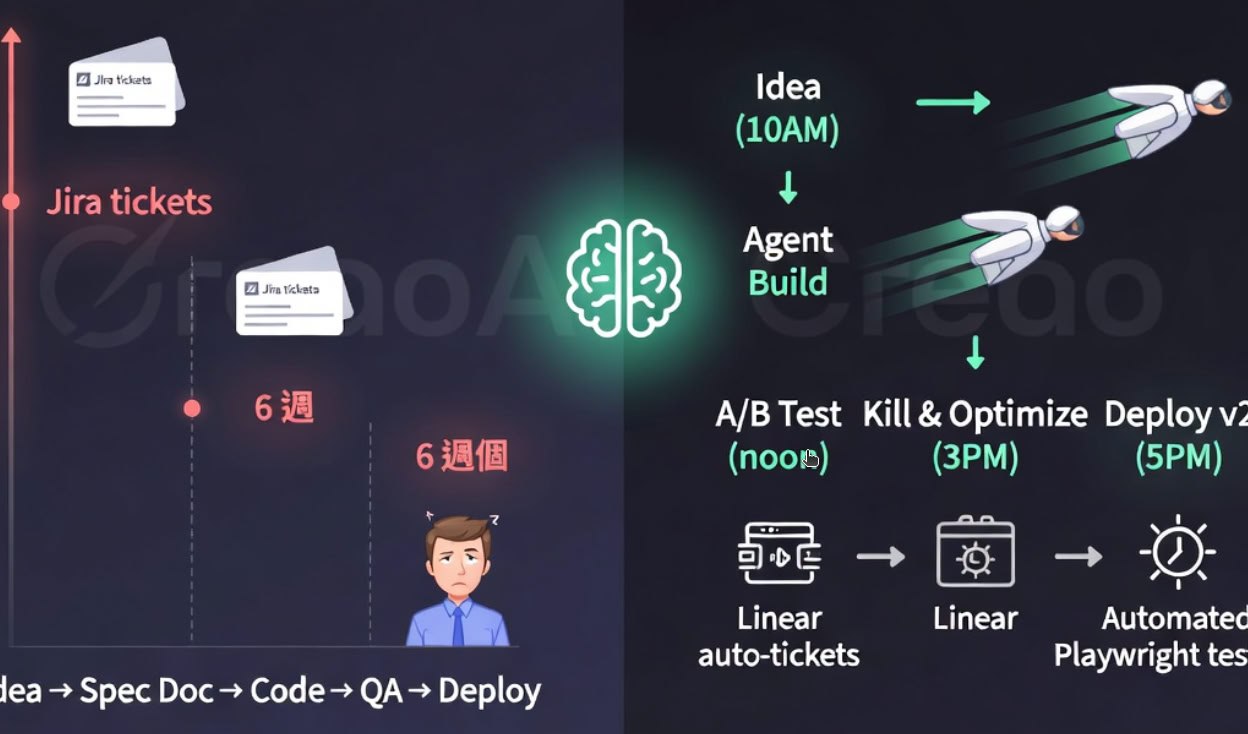
摘要:2026年4月13日,CreaoAI 联合创始人 Peter Pang(前 Meta LLaMA 团队成员)在 X 上发布了一篇长帖,详细拆解了他们团队如何将 99% 的生产代码交给 AI 完成,并将完整功能从构思到上线压缩到一天内完成:上午 10 点上线新特性,中午 A/B 测试,下午 3 点根据数据下线,晚上 5 点上线优化版。三个月前,同样的周期需要六周。 这不是"装个 Cursor 用 Copilot 提效 10-20%“的 AI-assisted 故事,而是彻底的 AI-first 重构。Peter 将其称为 harness engineering(OpenAI 在 2026 年 2 月正式命名的概念):工程团队的核心工作不再是写代码,而是为 Agent 构建可读、可验证、可执行的"马具”(harness),让 AI 成为首要构建者,人类负责方向、批判和风险判断。 本文将从技术视角完整解读这篇帖子,拆解 CreaoAI 的架构重构、工具链、自愈闭环、新型工程角色,以及对整个行业的启示。目标是帮助正在或即将迈入 Agent 时代的工程师和 CTO 理解:真正的 10x 不是更快写代码,而是把整个系统设计成 AI 能"看懂、改好、自己修"的状态。
2026年4月13日,CreaoAI 联合创始人 Peter Pang(前 Meta LLaMA 团队成员)在 X 上发布了一篇长帖,详细拆解了他们团队如何将 99% 的生产代码交给 AI 完成,并将完整功能从构思到上线压缩到一天内完成:上午 10 点上线新特性,中午 A/B 测试,下午 3 点根据数据下线,晚上 5 点上线优化版。三个月前,同样的周期需要六周。
这不是"装个 Cursor 用 Copilot 提效 10-20%“的 AI-assisted 故事,而是彻底的 AI-first 重构。Peter 将其称为 harness engineering(OpenAI 在 2026 年 2 月正式命名的概念):工程团队的核心工作不再是写代码,而是为 Agent 构建可读、可验证、可执行的"马具”(harness),让 AI 成为首要构建者,人类负责方向、批判和风险判断。
本文将从技术视角完整解读这篇帖子,拆解 CreaoAI 的架构重构、工具链、自愈闭环、新型工程角色,以及对整个行业的启示。目标是帮助正在或即将迈入 Agent 时代的工程师和 CTO 理解:真正的 10x 不是更快写代码,而是把整个系统设计成 AI 能"看懂、改好、自己修"的状态。
一、AI-assisted vs AI-first:乘法级差异的本质
大多数团队仍在"AI-assisted"模式:工程师打开 Cursor 提示,PM 用 ChatGPT 写需求,QA 尝试 AI 生成测试用例。流程不变,只是每个环节提效 10-20%。Jira 看板、站会、QA 签发一如既往。
CreaoAI 的 AI-first 则完全反转假设:AI 是首要构建者,工程师提供方向和最终判断。这要求三件事同时发生:
- 产品规划周期必须匹配构建速度(从周级降到小时级);
- 验证系统必须与实现速度同频(否则下游形成新瓶颈);
- 代码库架构必须对 Agent 完全"可读"(legible)。
Peter 观察到三个致命瓶颈:
- PM 瓶颈:传统 PM 花几周写规格文档,Agent 两小时就能实现特性。规划成了约束。
- QA 瓶颈:构建两小时,人工测试三天。验证滞后。
- 人力瓶颈:25 人团队(10 名工程师)面对 100 倍人力竞争,无法靠招聘追赶,必须靠流程重构。
解决方案不是"加 AI 工具",而是拆掉原有流程,围绕 Agent 重建。这正是 harness engineering 的核心:当 Agent 失败时,修复方式不是"让它再试一次",而是"缺少什么能力?如何让这个能力对 Agent 可读、可强制执行?"
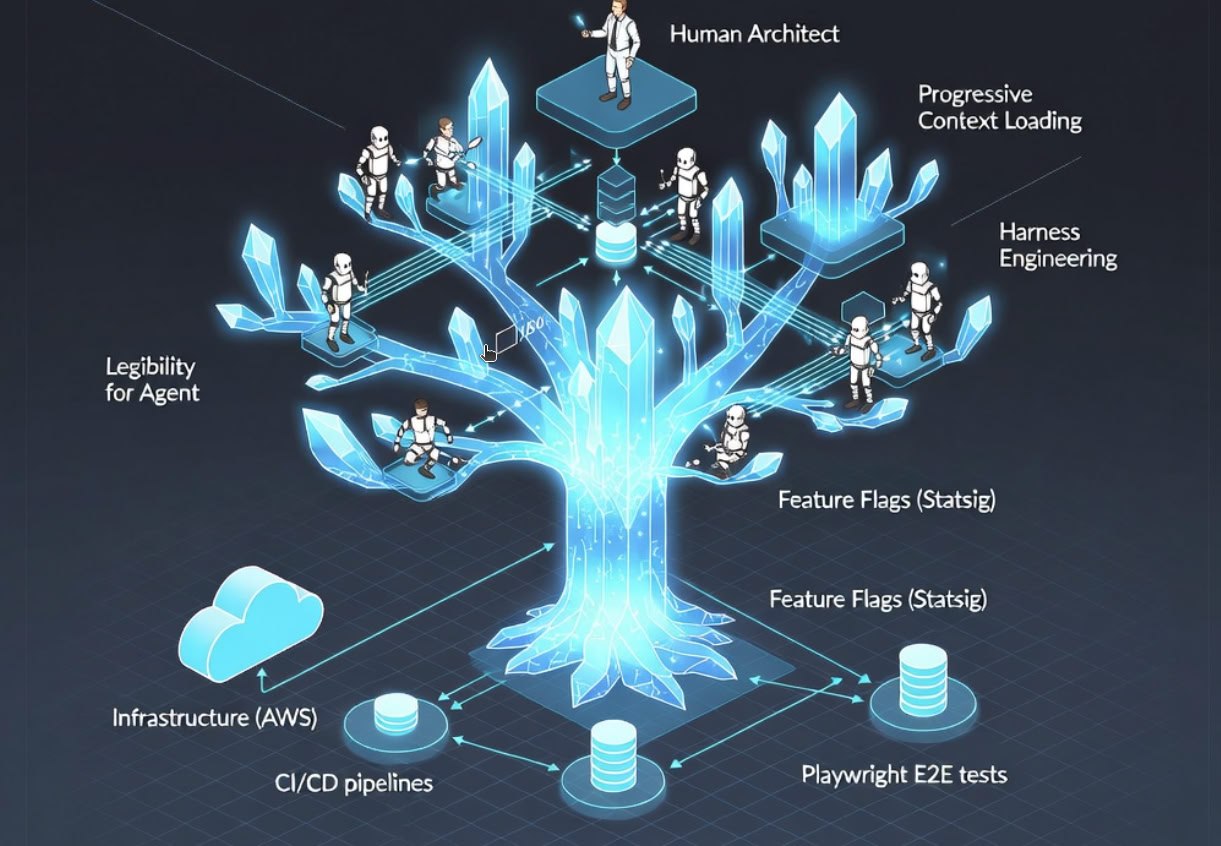
二、统一单体仓库(Monorepo)——让 Agent "看懂"整个系统
旧架构是多个独立仓库,改动一个特性可能涉及 3-4 个 repo。对人类工程师可控,对 Agent 则是"黑箱":无法看到全貌,无法做跨服务推理,无法本地跑集成测试。
Peter 用一周时间设计新架构,再用一周时间让 Agent 重构整个代码库。他们把一切拉进单个 monorepo。核心原理是 harness 思想:系统对 Agent 的可见性(legibility)直接决定杠杆大小。
技术上,monorepo 带来三大利好:
- 上下文完整性:Agent 可以遍历整个代码树,进行跨模块依赖分析。
- 本地验证闭环:Agent 能在本地运行完整的集成测试和 E2E 测试(Playwright),而非仅靠 PR 阶段的 CI。
- 渐进式上下文加载:不是把整个 repo 塞进 prompt(会爆炸),而是结合 Agent skills + 结构化检索(RAG-like),只加载当前任务相关的子树 + 相关依赖图。
Peter 特别提到,最近几个月 Claude 等模型在"progressive context loading"和结构化检索上的进步,让这一边界管理变得可行。碎片化代码库对 Agent 永远是"不透明的",统一 monorepo 则是"可遍历、可推理、可修改"的。
这不是简单的"把代码合并",而是架构可观测性的极致体现:Agent 必须能像人类高级工程师一样"看到"系统边界、状态机、数据流。
三、技术栈:从基础设施到自愈闭环的全链路设计
CreaoAI 的栈高度标准化,每一层都为 Agent 设计"可预测、可诊断、可自动回滚":
基础设施:AWS + auto-scaling + circuit-breaker rollback。CloudWatch 是"中央神经系统"——所有服务输出结构化日志,25+ 个自定义 alarm,日常由自动化 workflow 查询。如果 AI 读不到日志,就无法诊断,这是 harness 的底线要求。
CI/CD:GitHub Actions 六阶段管道(Verify CI → Build/Deploy Dev → Test Dev → Deploy Prod → Test Prod → Release)。每个 PR 强制:
- 类型检查 + lint
- 单元 + 集成测试
- Docker build
- Playwright E2E
- 环境一致性检查
无人工 override,管道确定性强,Agent 可预测失败结果。
AI Code Review:Claude Opus 4.6 并行三路审查(Code quality / Security / Dependency scan)。这是审查门(gate),而非建议。部署频率达到一天 3-8 次时,人类已无法维持注意力,AI 必须承担第一道防线。
自愈反馈闭环(Self-Healing Loop)——这是帖子最亮眼的实践:
- 每天 9:00 UTC,Claude Sonnet 4.6 查询 CloudWatch,生成健康摘要 → Microsoft Teams。
- 1 小时后,triage engine 聚类 Sentry + CloudWatch 错误,按 9 个维度打分,自动在 Linear 创建 ticket(含样本日志、影响用户、建议路径)。
- 去重 + 回归检测:相同模式更新现有 issue,旧 issue 复现则 reopen。
- 工程师推送修复 → 三路 Claude review → 六阶段 deploy → triage engine 再次验证 → 自动 close ticket。
这是一个闭环系统:错误检测 → 诊断 → 修复 → 验证 全自动,人类仅在"风险判断"环节介入。Peter 总结:“AI 会做出 PR,人类只需 review 是否有风险。”
Feature Flags & 发布安全网:Statsig 管理 flags,支持团队内测 → 灰度百分比 → 全量或 kill。Circuit-breaker 自动回滚。Graphite 处理 PR 合并队列 + stacked PRs,实现高吞吐增量审查。
四、特性交付路径:Idea → Production 的标准化 Agent 流程
新特性路径:
- Architect 以结构化 prompt + 代码库上下文 + 约束定义任务。
- Agent 分解、规划、写代码 + 自生成测试。
- PR → 三路 Claude review + 人类战略风险 review。
- CI 验证 → Graphite 合并 → 六阶段 deploy。
- Feature flag 开启 → 灰度 + 指标监控 → kill switch 或 A/B。
Bug 修复路径:
CloudWatch/Sentry 触发 → triage 自动 ticket → 工程师验证诊断 → AI 写 PR → 相同管道 → 自动 close。
两条路径共用同一管道,标准化是 Agent 可规模化的前提。
五、新型工程组织:Architect 与 Operator
传统"人人都是架构师"的模型失效。未来只有两种角色:
Architect(1-2 人):设计 SOP、测试平台、集成系统、triage 引擎、架构边界。他们批判 Agent 输出:找漏掉的 failure mode、安全边界、技术债。Peter 说,他 PhD 物理背景教给他最有用的技能是"质疑假设、压力测试、找缺失"。批判 AI 的能力将比产出代码更值钱。
Operator(其余所有人):AI 把 ticket 分配给人,人做调查验证、UI 微调、CSS、PR review、最终确认。任务依然需要技能,但架构级推理由系统和 Architect 承担。
有趣现象:Junior 工程师适应更快。他们没有十年传统习惯要打破,反而觉得被赋能。Senior 工程师最难接受——两月工作量 AI 一小时完成,身份认同受到冲击。但 Peter 强调:经验在"定义约束、批判输出"上更有价值,只要心态转变,贡献会更大。
六、量化结果与人性的现实
14 天内平均每天 3-8 次生产部署(旧模式两周一次都难)。坏特性同日下线,好特性同日上线,A/B 实时验证。用户参与度和付费转化反而上升——更快的反馈循环带来更好决策。管理时间从 60% 降到 <10%。CTO 从"对齐会议"变成"构建 harness"。人际关系改善,因为不再为技术 trade-off 争论。副作用真实存在:部分人感到不确定,过渡期焦虑,CTO 每天 9AM-3AM 工作。
Peter 原则:不因引入 bug 解雇工程师(包括 AI),而是强化 review、测试、guardrail。
七、对工程师、CTO 和行业的启示
对工程师:代码产出价值每月都在下降,决策质量、产品 taste、批判性思考价值上升。19 岁实习生被建议:练批判思考、找 gap、理解"好设计"。
对 CTO/Founder:
- 如果 PM 周期 > 构建周期,先改规划。
- 先建测试 harness,再 scale Agent(Fast AI without fast validation = fast-moving technical debt)。
- 从 1 个 Architect 起步,证明系统后再扩 Operator。
- 把 AI-native 推到全公司(营销、运营、分析)。
对行业:Harness engineering 正在成为标准。模型能力(Opus 4.6 vs 4.5)是驱动时钟。下代模型会进一步加速。一人公司将成为常态——一个 Architect + Agent 可顶 100 人。
CreaoAI 证明:工具已就绪,优势在于愿意承担重构成本(员工焦虑、CTO 超负荷、过渡期混乱)。两月后,数据说话。
八、结语:从工具使用者到系统设计师
Peter 的帖子不是炫耀,而是实操手册。它告诉我们:AI 时代真正的护城河不是 prompt 技巧,而是把整个工程系统设计成 Agent 可自主、高可靠运行的状态。Monorepo、结构化可观测性、自愈闭环、Architect 角色……这些才是乘法杠杆。
对正在转型的团队,我的建议是:先做一次"legibility audit"——你的代码库、日志、测试、部署管道,对 LLM 是否完全可读、可验证、可自动修复?如果答案是否定的,那就从 monorepo 和自愈 triage 开始,一步步 build your harness。
未来不是"人 vs AI",而是"设计 harness 的人 vs 没设计的团队"。CreaoAI 用 25 人(10 工程师)跑出了远超传统 100 人团队的速度和质量,证明了这条路可行。
我们才刚刚开始。下一代模型 + 更成熟的 harness,将把"一人公司"从概念变成主流。准备好 redesign everything 了吗?